(1)第一步:内容介绍

(2)
网易新闻的链接:https://news.163.com/
重点爬取五个板块的文字:国内,国际,军事,航空,无人机
需求:爬取基于文字的新闻数据
三步走
第一步:
新建项目
scrapy startproject wangyiPro
cd wangyiPro/
建立爬虫文件
scrapy genspider wangyi www.xxxx.com
第二步:组织数据结构和写爬虫文件
wangyi.py
import scrapy class WangyiSpider(scrapy.Spider): name = 'wangyi' # allowed_domains = ['www.xxx.com'] start_urls = ['https://news.163.com/'] def parse(self, response): lis=response.xpath('//div[@class="ns_area list"]/ul/li') indexs=[3,4,6,7,8] li_list=[] #存储的就是国内,国际,军事,航空,无人机五个模块对应的li标签对象 for index in indexs: li_list.append(lis[index]) #获取四个板块中的链接和文字标题 for li in li_list: url=li.xpath('./a/@href').extract_first() title=li.xpath('./a/text()').extract_first() print(url+":"+title)
在settings.py加上UA和robots设置
扫描二维码关注公众号,回复:
6700707 查看本文章

注意,在爬取数据量很小的时候可以不加,在某些网站上,这个案例就是这样
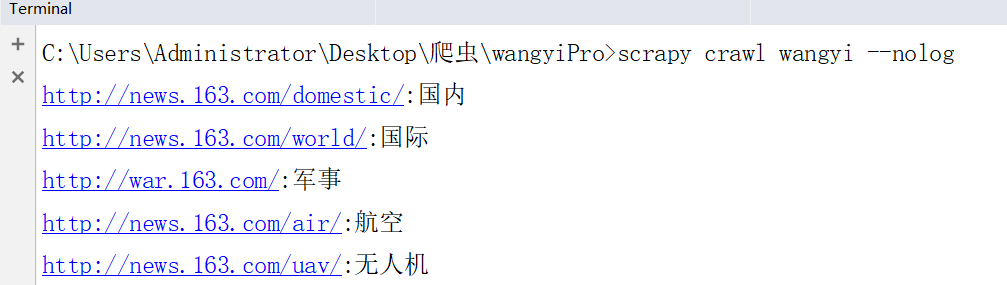
第三步:执行
scrapy crawl wangyi --nolog
结果:
(3)很多时间花费在解析数据上了
# -*- coding: utf-8 -*- import scrapy class WangyiSpider(scrapy.Spider): name = 'wangyi' # allowed_domains = ['www.xxx.com'] start_urls = ['https://news.163.com/'] def parse(self, response): lis=response.xpath('//div[@class="ns_area list"]/ul/li') indexs=[3,4,6,7,8] li_list=[] #存储的就是国内,国际,军事,航空,无人机五个模块对应的li标签对象 for index in indexs: li_list.append(lis[index]) #获取四个板块中的链接和文字标题 for li in li_list: url=li.xpath('./a/@href').extract_first() title=li.xpath('./a/text()').extract_first() # print(url+":"+title) #对每一个板块对应的url发起请求,获取页面数据(标题,缩略图,关键字,发布时间,url) yield scrapy.Request(url=url,callback=self.parseSecond) def parseSecond(self,response): div_list=response.xpath('//div[@class="data_row news_article clearfix"]') print(len(div_list)) for div in div_list: head=div.xpath('.//div[@class="news_title"]/h3/a/text()').extract_first() url=div.xpath('.//div[@class="news_title"]/h3/a/@href').extract_first() imgUrl=div.xpath('./a/img/@src').extract_first() publish_t=div.xpath('.//div[@class="news_tag"]/span/text()').extract_first() tag=div.xpath('.//div[@class="keywords"]/a/text()').extract() tag="".join(tag)

动态加载的数据拿不到,用selenium
(4)