引言
最近在研究Faster-RCNN算法,作为一名目标检测的新手,参考了许多优秀的博客,希望将他们的核心思想记录下来以便日后回忆学习,同时加深自己的理解,以下是我根据一些优秀的博客整理总结的,参考资料注了其来源。
RCNN的算法思想
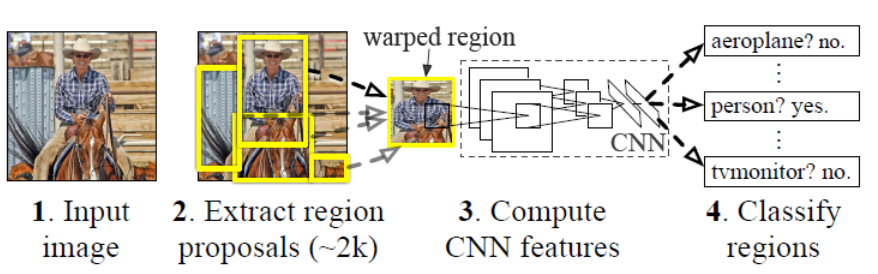
1.对图像生成候选区域
使用Selective Search从一张图像生成2k~3k个候选区域(上图黄色的框),大概思路为:
- 使用一种过分割手段,将图像分割成小区域
- 查看现有小区域,合并可能性最高的两个区域。重复直到整张图像合并成一个区域位置
- 输出所有曾经存在过的区域(包含R-CNN最终定位结果),所谓候选区域
为尽可能不遗漏候选区域,上述操作在多个颜色空间中同时进行(RGB,HSV,Lab等)。在一个颜色空间中,使用四条合并规则的不同组合进行合并。在得到所有颜色空间与所有规则的全部结果,去除重复后,作为候选区域输出。
2.特征提取
先对候选区域进行预处理(这里因为选取的CNN是Alexnet,其原来网络的输入就是227*****227,将输入的候选区域图像统一变换为227*****227),然后通过CNN对每个候选区域提取固定长度的特征向量。
在训练时,候选区域有 2000 个,所以很多会进行重叠。针对每个类,通过计算 IoU 指标,采取非极大性抑制,以最高分的区域为基础,剔除掉那些重叠位置的区域。
3.类别判断
对每一类目标,使用一个线性SVM二类分类器进行判别。输入为深度网络输出的候选区域的特征,输出是否属于此类。
4.位置精修
很多看似准确的检测结果,往往因为候选框不够准确,重叠面积很小。故需要一个位置精修步骤,对每一类目标,使用一个线性回归器对候选框位置进行精修。
Fast R-CNN的算法思想


1.RCNN存在的问题
训练和测试速度慢:
R-CNN中用CNN对每一个候选区域反复提取特征,而一张图片的2000个候选区域之间有大量重叠部分,这一设定造成特征提取操作浪费大量计算。
训练所需空间大:
R-CNN中目标分类与候选框的回归是独立的两个操作,并且需要大量特征作为训练样本。
2.Fast RCNN的特点
Fast RCNN的网络有2个输出层,一个softmax,一个bbox regressor,相对于RCNN中分类和回归分为2个部分,这里集成在同一网络,这样可以有效减少计算量。
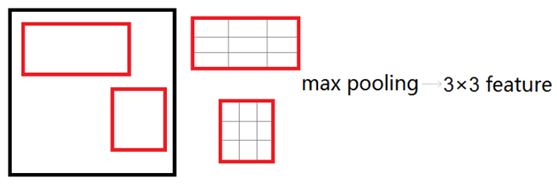
作者提出了一个叫做ROI Pooling的网络层,这个网络层可以把不同大小的输入映射到一个固定尺度的特征向量。ROI Pooling层将每个候选区域均匀分成M×N块,对每块进行max pooling。将特征图上大小不一的候选区域转变为大小统一的数据,送入下一层。这样虽然输入的图片尺寸不同,得到的feature map尺寸也不同,但是可以加入这个神奇的ROI Pooling层,对每个region都提取一个固定维度的特征表示,就可再通过正常的softmax进行类型识别。这样在分类时就不用变换候选区域图像为相同大小。
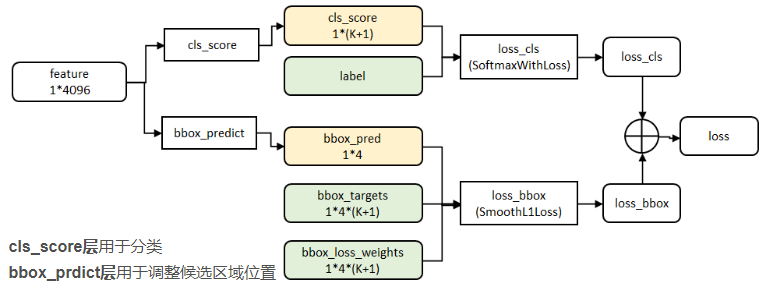
在R-CNN中,先生成候选框,然后再通过CNN提取特征,之后再用SVM分类,最后再做回归得到具体位置(bbox regression)。而在Fast R-CNN中,作者巧妙的把最后的bbox regression也放进了神经网络内部,与区域分类合并成为了一个multi-task模型,这两个任务能够共享卷积特征,并且相互促进。如下图所示:
Faster RCNN算法思想

1.网络结构介绍
Conv layers 作为一种CNN网络目标检测方法,Faster RCNN首先使用一组基础的conv+relu+pooling层提取image的feature maps。该feature maps被共享用于后续RPN层和全连接层。
Region Proposal Networks RPN网络用于生成region proposals。该层通过softmax判断anchors属于positive或者negative,再利用bounding box regression修正anchors获得精确的proposals。
Roi Pooling 该层收集输入的feature maps和proposals,综合这些信息后提取proposal feature maps,送入后续全连接层判定目标类别。
Classification 利用proposal feature maps计算proposals的类别,同时再次bounding box regression获得检测框最终的精确位置。
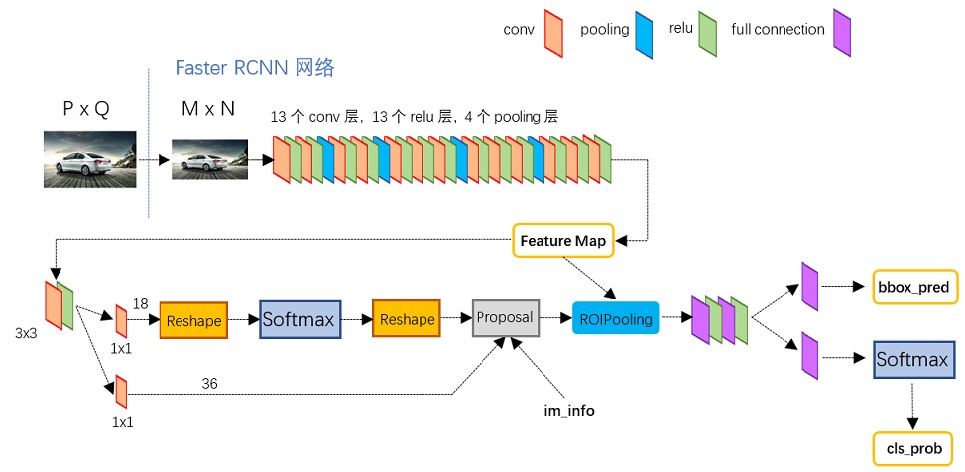
网络对于一副任意大小PxQ的图像,首先缩放至固定大小MxN,然后将MxN图像送入网络;而Conv
layers中包含了13个conv层+13个relu层+4个pooling层;RPN网络首先经过3x3卷积,再分别生成positive
anchors和对应bounding box regression偏移量,然后计算出proposals;而Roi Pooling层则利用proposals从feature maps中提取proposal feature送入后续全连接和softmax网络作classification(即分类proposal到底是什么object)。
参考资料
【1】:https://blog.csdn.net/shenxiaolu1984/article/details/51066975#fn:1,作者:shenxiaolu1984
【2】:https://blog.csdn.net/briblue/article/details/82012575
【3】:https://www.jianshu.com/p/fbbb21e1e390