1.更改py-faster-rcnn/lib/rpn/generate_anchors.py中函数generate_anchors,其中参数scales出现的问题
Check failed: outer_num_ * inner_num_ == bottom[1]->count() (21546 vs. 35910) Number of labels must match number of predictions; e.g., if softmax axis == 1 and prediction shape is (N, C, H, W), label count (number of labels) must be N*H*W, with integer values in {0, 1, ..., C-1}.
修改过程参考http://www.bubuko.com/infodetail-2306438.html
https://github.com/rbgirshick/py-faster-rcnn/issues/161
修改示例:
①修改generate_anchors.py,修改为scales=(2,4,8,16,32);
②修改anchor_target_layer.py,修改为anchor_scales = layer_params.get('scales', (2, 4, 8, 16, 32));
③修改proposal_layer.py,修改为anchor_scales = layer_params.get('scales', (2, 4, 8, 16, 32));
④修改faster_rcnn_alt_opt/faster_rcnn_end2end(用哪一个训练,修改哪一个即可)中,rpn_cls_score层的num_output改为30 # 2(bg/fg) * 15(anchors),其中anchors数量为scales(5个)与ratios(3个)的数量相乘,rpn_bbox_pred层的num_output改为60 # 4 * 15(anchors)
⑤修改faster_rcnn_alt_opt/faster_rcnn_end2end(用哪一个训练,修改哪一个即可)中,rpn_cls_prob_reshape层的第2个dim,即shape { dim: 0 dim: 18 dim: -1 dim: 0 }中18改为:30 #2*15(anchors)
2.学习率base_lr的理解
参考https://stackoverflow.com/questions/30033096/what-is-lr-policy-in-caffe
示例:lr_policy: "step":

3.深度学习网络可视化工具(caffe)
参考http://ethereon.github.io/netscope/#/editor
示例展示:
4.修改各类参数(base_lr,weight_decay,base_size,scales,……),训练结果中mAP一直不提升,反而下降,考虑数据集中是否存在错误
参考https://github.com/rbgirshick/py-faster-rcnn/issues/9,其中讨论到数据集Annotations中没有groundtruth,会影响到训练结果,因此,检查自己数据集,发现有xmax与ymax为0的情况,直接去掉这部分数据(删除py-faster-rcnn/data/VOCdevkit2007/VOC2007/ImageSets/Main中文件里面出现对应问题的序号)
效果比对(VGG16):
①删除前:mAP=0.31;(最大迭代次数为80000,60000,80000,60000)
②删除后:mAP=0.3339;(最大迭代次数为80000,60000,80000,60000)
③删除后:mAP=0.3334;(最大迭代次数为200000,120000,200000,120000)
所以,数据集的正确性对于faster-rcnn训练过程起到了一定的作用,80000次的最大迭代次数已经满足了VGG16的训练迭代要求。
5.大图中小目标检测
参考网站与论文:
https://github.com/rbgirshick/py-faster-rcnn/issues/86
https://github.com/rbgirshick/py-faster-rcnn/issues/433
https://www.merl.com/publications/docs/TR2016-144.pdf
①修改config.py中的RPN_MIN_SIZE,对于小目标检测,改小一点就行(由于我的数据集中有特别小的对象,直接将16改为了8),用SqueezeNet(https://blog.csdn.net/u011956147/article/details/53714616)训练测试,mAP从0.2354提升至0.2552(这是在第4步的基础上)
6.训练过程中问题bbox_loss = nan的情况
报错:RuntimeWarning: invalid value encountered in greater_equal
keep = np.where((ws >= min_size) & (hs >= min_size))[0]
参考网站:https://github.com/chainer/chainercv/issues/326
①cpu模式下出现的问题,具体查看参考网站;
②主要是自己制作的数据集存在一定问题。比如,我的数据集中存在对象面积为0的情况,去掉对应xml文件即可正常运行
③VOC数据集从1开始计算像素,而自己的数据集很有可能存在从0开始标注对象(object)的情况,将x1 = float(bbox.find('xmin').text) #原始多一个-1
y1 = float(bbox.find('ymin').text) #原始多一个-1
x2 = float(bbox.find('xmax').text) #原始多一个-1
y2 = float(bbox.find('ymax').text) #原始多一个-1
(主要参考方式②)
7.IndexError: list index out of range
py-faster-rcnn/data/cache/下的缓存文件未删除的原因,直接删除即可。
8.eval时出现问题
line 126, in voc_eval
R = [obj for obj in recs[imagename] if obj['name'] == classname]
参考网站:https://www.cnblogs.com/xthrough/p/6386651.html
文件夹/py-faster-rcnn/data/VOCdevkit2007/annotations_cache/下面的文件没有被删除,直接删除即可。
9.faster-rcnn中RPN实现的三步骤
参考网站:https://www.quora.com/How-does-the-region-proposal-network-RPN-in-Faster-R-CNN-work
step1: the input image goes through a convolution network which will output a set of convlutional feature maps on the last convolutional layer.
{卷积特征提取层:input-data → conv1_1|relu1_1(channel:64,kernel:3,pad:1) → conv1_2|relu1_2(64,3,1) → pool1(kernel:2,stride:2) → conv2_1|relu2_1(128,3,1) → conv2_2|relu2_2(128,3,1) → pool2(2,2) → conv3_1|relu3_1(256,3,1) → conv3_2|relu3_2(256,3,1) → pool3(2,2) → conv4_1|relu4_1(512,3,1) → conv4_2|relu4_2(512,3,1) → conv4_3|relu4_3(512,3,1) → pool4(2,2)→ conv5_1|relu5_1(512,3,1) → conv5_2|relu5_2(512,3,1) → conv5_3|relu5_3(512,3,1)}
step2:Then a sliding window is run spatially on these feature maps.
{→ rpn_conv/3×3|rpn_relu/3×3(512,3,1)→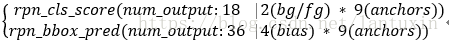
step3:classification (cls) and regression (reg)
10.各层作用
卷积层(前五层,包括relu,pool)--提取图片特征
全连接层--针对分类的特征提取
如:对于人脸性别识别来说,一个CNN模型前面的卷积层所学习到的特征就类似于学习人脸共性特征,然后全连接层所学习的特征就是针对性别分类的特征了。
参考网站:http://lib.csdn.net/article/deeplearning/43032
