本章介绍TensorFlow的主要结构和常用方法的相关函数及功能。这一章涉及到的专业术语会很多,有利于提高读者的代码阅读能力和使用能力,也涉及到很多神经网络方面的知识,在后面我们还会介绍到。
编程模型
TensorFlow的编程结构就像一个流程图,图中的tensor会从起点流入图之后,在图中每个节点传递数据,计算完成之后从输出端流出。这也由TensorFlow的命名决定,Tensor为张量代表多维数组,Flow为流代表张量在图中进行数据流图计算。
了解模型的运行机制
TensorFlow的运行机制由两部分组成:定义数据流图和运行数据流图。在TensorFlow中,算法都被表示成数据流图,所以在上手TensorFlow之前,我们应该理解表1的几个基本概念。
表1 模型构建中的基本概念
| 类型 |
描述 |
含义 |
||
| 张量(tensors) |
数据
扫描二维码关注公众号,回复:
6555933 查看本文章

|
数据,即某一类型的多维数组。 |
||
| 变量(variables) |
变量 |
常用于定义模型中的参数,是通过不断训练得到的值。 |
||
| Graph(计算图) |
描述结算过程 |
图必须在称之为“会话”的上下文中执行。会话将图的OP分发到诸如CPU或GPU上计算 |
||
| 会话(sessions) |
会话 |
在TensorFlow中,所有操作都必须在会话(session)中执行,会话负责分配和管理各种资源 |
||
| 图中的节点操作(operation,op) |
操作 |
即一个OP获得0个或多个tensor,执行计算,输出额外的0个或多个tensor。 |
||
| 占位符(placeholder) |
占位符 |
输入变量的载体。可以理解为定义函数时的参数。 |
||
| feed(注入机制) |
|
为op的Tensor赋值,通过占位符向模型中传入数据 |
||
| fetch(取回机制) |
取值 |
从op的Tensor中取值,从模型中得到结果 |
||
| Constant(常量) |
常量 |
|
表1中的基本概念有如图1关系,张量、变量、会话、操作以及占位符等基本概念都是在一个被称为“图”的容器中完成的,一个图就是一个计算执行过程。实现图构建以后,在session中启动运行数据流图。整个过程可表述为session将op分发到各自的CPU、GPU等设备上,同时为op提供执行方法。执行这些方法以后,会产生相应的tensor返回。若是在Python中执行,将返回numpynadarry对象。在模型中,实参就是输入的样本,形参就是占位符,运算过程就相当于函数体,得到的结果相当于返回值。

图1 session和图的工作关系
在实际过程中,图1的运行情况会训练场景、测试场景和使用场景。下边为三个场景做详细介绍。
训练场景:是生成模型的过程。其过程是将样本和标签作为输入节点,通过大量循环迭代,正向输出得到输出值,再进行反向运算,更行模型中的学习参数,最终会使模型产生的正向输出最大化接近样本标签。这就得到了一个可以拟合样本规律的模型。
测试场景和使用场景:测试场景是利用 图的正向输出结果与张氏值进行比较的差别;使用场景也是直接利用图的正向输出得到结果,并直接使用。所以二者的运算过程是一样的。对于该场景下的模型与正常编程用的函数特别相似。在函数中,可以分为实参、形参、函数体与返回值。同样在模型中,实参就是输入的样本,形参就是占位符,运算过程就相当于函数体,得到的结果想到于返回值。
实例1:编写hello world程1 训练场景
建立一个session,在session中输出hello,TensorFlow!
代码1 hello
输出结果:
![]()
代码1中的tf.constant用来定义一个常量,session启动时输入hello的内容。下边用with来启动session。
实例2:演示with session的使用
with session的用法是最常见的,它沿用了 Python中with的语法,即当程序结束后会自动关闭session,而不需要再去写close。
实例描述:
使用with session来建立session,并在session实现两个变量(4和7)的相加和相乘运算。
代码2 withsession

输出结果:
![]()
实例3:演示注入机制
定义占位符,使用feed机制将具体数值(4和 7)通过占位符传入,并进行相加和相乘运算。
代码3 withsessionfeed

运行结果:
![]()
其中,tf.placeholder为这些操作创建占位符,然后使用feed_dict把具体数值放到占位符里。
建立session 的其他方法
建立session还有交互的tf.InteractiveSession()和Supervisor方式。
tf.InteractiveSession()方式一般在Jupyter环境下使用较多,它为自己成为了默认的session,也就是用户在运行是不必知名是用哪个session。即run()和eval()函数可以不指明session。
Supervisor方法更加高级,使用也更复杂可以用来自动管理session中的具体任务,例如,载入/载出检查点文件、写入TensorBoard等,另外该方法还支持分布式训练的部署。
实例4:使用注入机制获取节点
在实例3中,通过在最后一句加上如代码4的代码可实现一次将多个节点取出来。
代码4 withsessionfeed1

输出结果:

指定GPU运算
如果设备上有多个GPU,则指定第一个为默认GPU其他的不工作。若想用其他GPU,可用with tf.device(……)指定。实例如下:
代码5 指定GPU

目前设备用字符串标识,大概可表示为:
cpu:0 机器的cpu
gpu:0 机器的第一个GPU,如果有的话
gpu:1 机器的第二个GPU……
同时还可通过tf.ConfigProto方式来构建一个config,在config中指定相关的GPU。tf.ConfigProto参数如下:
log_device_placement = True :是否打印设备分配日志
allow_soft_placement = True :如果指设备不存在,允许tf自动分配
使用举例:
config = tf.ConfigProto(log_device_placement = Ture, allow_soft_placement = Ture)
session = tf.Session(config=config,……)
保存和载入模型的方法介绍
训练完成的模型在一般情况下都需要保存,网上介绍了TensorFlow加载和保存的几种基本方法,下边给大家分别做介绍。
1.保存模型
最常用的基本方法是使用saver.save()方法保存,先建立一个saver,然否在session中通过saver的save即可将模型保存起来。代码示例如下:
代码6 保存模型

2.加载模型
最常用的基本方法是用saver.restore()方法载入,模型保存后可在session中通过saver的restore()函数载入。代码示例如下:
代码7 加载模型

实例5:保存/载入线性回归模型
代码8是已经添加了保存及载入功能的线性回归模型的展示。
代码8 线性回归模型的保存及载入




程序运行输出结果:



最后再重启一个session,命名为sess2的部分是用来证明测试效果的,这里是通过saver的restore函数将模型载入。将前面的session注释掉,可以看到如图输出,说明模型载入成功,并且计算出正确的值。
![]()
同时在代码的同级目录 下log文件夹里生成了几个文件,如图所示:

图2 模型文件
实例6:分析模型内容,演示模型的其他 保存方法
1.模型内容
模型保存以后对我们是不透明的,我们可以通过编写代码来查看模型里的内容。通过把模型里的东西打印出来,来了解有那些东西,是什么样的。
代码9 模型内容

运行代码,输出如下:

可以看到,tensor_name: 后面跟的就是创建的变量名,接着是他的数值。
2.保存模型的其他方法
本例给大家介绍tf.train.Saver函数的其他更加高级的功能,通过在函数里放参数来指定存储变量名字与变量的对应关系。实例如下:
代码10 查看模型内容

运行代码,输出如下:

代码saver = tf.train.Saver({‘wight’:w,……})表示将w变量的值放到weight名字中。从结果可以看到,给b和w分别指定固定的值之后,创建的saver将它们颠倒了。
检查点(Checkpoint)
TensorFlow训练模型因为很多原因可能会出现中断情况,这种情况下,即使没有训练完,我们还是希望训练过程中得到的中间参数保存下来,不然下次又要从头开始训练。所以为了在训练中保存模型,引入了检查点概念。
实例7:为模型添加保存检查点
实列描述:
为一个线性回归模型添加“检查点功能”功能。通过该功能,可以生成载入检查点文件,并能够指定生成检查点文件的个数。
该例相比模型保存功能,保存位置发生了变化,保存位置放在了迭代训练中的打印信息后面。
完整代码如下:
代码11 保存检查点





代码运行完以后,会在log文件下多如下几个文件,就是检查点文件。

图3 检查点文件
其中头tf,train.Saver(max_to_keep=1)表示在迭代过程中只保存一个文件,这样以后,新生成的模型会覆盖掉以前的模型。
实例8:更简便地保存检查点
还有另一种方法可以保存检查点,而且相对上一例更加简单便捷——tf.train.MonitoredTraining Session函数。该函数可以直接实现保存及载入检查点模型的文件。与前面的方式不同,本例中并不是按照循环步数来保存,而是按照训练时间来保存的。通过指定save_ckeckpoint_secs参数的具体秒数,来设置每训练多久保存一次检查点。
实例描述:
演示使用MonitoredTrainingSession函数来自动管理检查点文件。
具体代码如下:
代码12 更简保存检查点

运行输出如下:

将程序终止,可看到log/checkpoints下面生成以下几个文件。
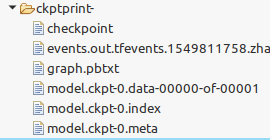
图4 检查点文件
再次运行代码,有如下输出:

可见,程序自动载入检查点是从第0次开始运行的。