转自:https://blog.csdn.net/kisslotus/article/details/78427585
1. 简介
在机器学习领域,LDA是两个常用模型的简称:Linear Discriminant Analysis 和 Latent Dirichlet Allocation。本文的LDA仅指代Latent Dirichlet Allocation. LDA 在主题模型中占有非常重要的地位,常用来文本分类。
LDA由Blei, David M.、Ng, Andrew Y.、Jordan于2003年提出,用来推测文档的主题分布。它可以将文档集中每篇文档的主题以概率分布的形式给出,从而通过分析一些文档抽取出它们的主题分布后,便可以根据主题分布进行主题聚类或文本分类。
2. 先验知识
LDA 模型涉及很多数学知识,这也许是LDA晦涩难懂的主要原因。本小节主要介绍LDA中涉及的数学知识。数学功底比较好的读者可以直接跳过本小节。
LDA涉及到的知识有:二项分布、Gamma函数、Beta分布、多项分布、Dirichlet分布、马尔科夫链、MCMC、Gibbs Sampling、EM算法等。
2.1 词袋模型
LDA 采用词袋模型。所谓词袋模型,是将一篇文档,我们仅考虑一个词汇是否出现,而不考虑其出现的顺序。在词袋模型中,“我喜欢你”和“你喜欢我”是等价的。与词袋模型相反的一个模型是n-gram,n-gram考虑了词汇出现的先后顺序。
二项分布是N重伯努利分布,即为X ~ B(n, p). 概率密度公式为:
2.3 多项分布
多项分布,是二项分布扩展到多维的情况. 多项分布是指单次试验中的随机变量的取值不再是0-1的,而是有多种离散值可能(1,2,3…,k).概率密度函数为:
2.4 Gamma函数
Gamma函数的定义:
分部积分后,可以发现Gamma函数如有这样的性质:
Gamma函数可以看成是阶乘在实数集上的延拓,具有如下性质:
2.5 Beta分布
Beta分布的定义:对于参数α>0,β>0, 取值范围为[0, 1]的随机变量x的概率密度函数为:
其中,
2.6 共轭先验分布
在贝叶斯概率理论中,如果后验概率P(θ∣x)先验概率 p(θ)满足同样的分布律,那么,先验分布和后验分布被叫做共轭分布,同时,先验分布叫做似然函数的共轭先验分布。
Beta分布是二项式分布的共轭先验分布,而狄利克雷(Dirichlet)分布是多项式分布的共轭分布。
共轭的意思是,以Beta分布和二项式分布为例,数据符合二项分布的时候,参数的先验分布和后验分布都能保持Beta分布的形式,这种形式不变的好处是,我们能够在先验分布中赋予参数很明确的物理意义,这个物理意义可以延续到后续分布中进行解释,同时从先验变换到后验过程中从数据中补充的知识也容易有物理解释。
2.7 Dirichlet分布
Dirichlet的概率密度函数为:
其中,
据Beta分布、二项分布、Dirichlet分布、多项式分布的公式,我们可以验证Beta分布是二项式分布的共轭先验分布,而狄利克雷(Dirichlet)分布是多项式分布的共轭分布。
对于Beta分布的随机变量,其均值可以用α/(α+β)来估计。Dirichlet分布也有类似的结论,
这两个结论非常重要,后面的LDA数学推导过程会使用这个结论。
2.9 MCMC 和 Gibbs Sampling
在现实应用中,我们很多时候很难精确求出精确的概率分布,常常采用近似推断方法。近似推断方法大致可分为两大类:第一类是采样(Sampling), 通过使用随机化方法完成近似;第二类是使用确定性近似完成近似推断,典型代表为变分推断(variational inference).(其实求解方法,理解就可以,这里不搬了)
3. 文本建模
一篇文档,可以看成是一组有序的词的序列d=(ω1,ω2,⋯,ωn) 从统计学角度来看,文档的生成可以看成是上帝抛掷骰子生成的结果,每一次抛掷骰子都生成一个词汇,抛掷N词生成一篇文档。在统计文本建模中,我们希望猜测出上帝是如何玩这个游戏的,这会涉及到两个最核心的问题:
上帝都有什么样的骰子;
上帝是如何抛掷这些骰子的;
第一个问题就是表示模型中都有哪些参数,骰子的每一个面的概率都对应于模型中的参数;第二个问题就表示游戏规则是什么,上帝可能有各种不同类型的骰子,上帝可以按照一定的规则抛掷这些骰子从而产生词序列。
3.1 Unigram Model
在Unigram Model中,我们采用词袋模型,假设了文档之间相互独立,文档中的词汇之间相互独立。假设我们的词典中一共有 V 个词 ν1,ν2,⋯,νV,那么最简单的 Unigram Model 就是认为上帝是按照如下的游戏规则产生文本的。
1. 上帝只有一个骰子,这个骰子有V面,每个面对应一个词,各个面的概率不一;
2. 每抛掷一次骰子,抛出的面就对应的产生一个词;如果一篇文档中N个词,就独立的抛掷n次骰子产生n个词;
这里也不搬了。
3.1.2 贝叶斯派视角
对于以上模型,贝叶斯统计学派的统计学家会有不同意见,他们会很挑剔的批评只假设上帝拥有唯一一个固定的骰子是不合理的。在贝叶斯学派看来,一切参数都是随机变量,以上模型中的骰子不是唯一固定的,它也是一个随机变量。所以按照贝叶斯学派的观点,上帝是按照以下的过程在玩游戏的:
1. 现有一个装有无穷多个骰子的坛子,里面装有各式各样的骰子,每个骰子有V个面;
2. 现从坛子中抽取一个骰子出来,然后使用这个骰子不断抛掷,直到产生语料库中的所有词汇
LDA是基于贝叶斯模型的,涉及到贝叶斯模型离不开“先验分布”,“数据(似然)”和"后验分布"三块。在贝叶斯学派这里:
先验分布 + 数据(似然)= 后验分布
这点其实很好理解,因为这符合我们人的思维方式,比如你对好人和坏人的认知,先验分布为:100个好人和100个的坏人,即你认为好人坏人各占一半,现在你被2个好人(数据)帮助了和1个坏人骗了,于是你得到了新的后验分布为:102个好人和101个的坏人。现在你的后验分布里面认为好人比坏人多了。这个后验分布接着又变成你的新的先验分布,当你被1个好人(数据)帮助了和3个坏人(数据)骗了后,你又更新了你的后验分布为:103个好人和104个的坏人。依次继续更新下去。
其实,这里已经把关键问题解释掉了,也就是说,我们用多项式分布表示数据(似然),用Dirichlet分布表示先验分布,之后,利用贝叶斯公式,先近似先验分布(如MCMC采样),再计算后验分布(先验和后验共轭)。不断迭代更新模型分布。
LDA主题模型
前面做了这么多的铺垫,我们终于可以开始LDA主题模型了。
我们的问题是这样的,我们有M篇文档,对应第d个文档中有有Nd个词。即输入为如下图:
我们的目标是找到每一篇文档的主题分布和每一个主题中词的分布。在LDA模型中,我们需要先假定一个主题数目K,这样所有的分布就都基于K个主题展开。那么具体LDA模型是怎么样的呢?具体如下图:
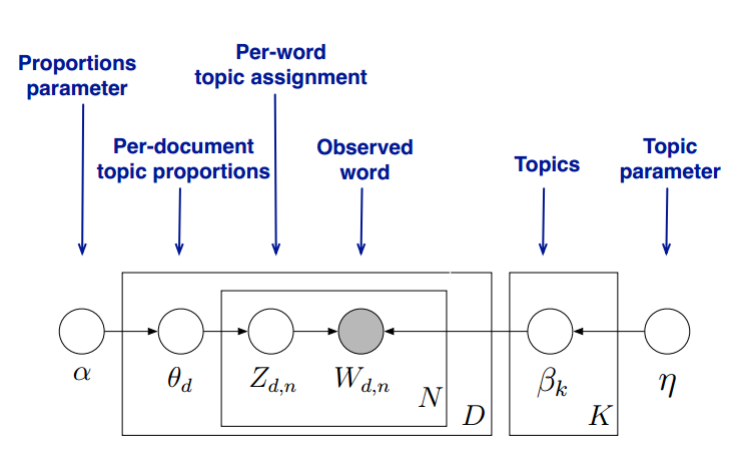
LDA假设文档主题的先验分布是Dirichlet分布,即对于任一文档d, 其主题分布θd为:θd=Dirichlet(α→),其中,α为分布的超参数,是一个K维向量。
LDA假设主题中词的先验分布是Dirichlet分布,即对于任一主题k, 其词分布βk为:βk=Dirichlet(η→)其中,η为分布的超参数,是一个V维向量。V代表词汇表里所有词的个数。
对于数据中任一一篇文档d中的第n个词,我们可以从主题分布θd中得到它的主题编号zdn的分布为:zdn=multi(θd)
而对于该主题编号,得到我们看到的词wdn的概率分布为:wdn=multi(βzdn)
理解LDA主题模型的主要任务就是理解上面的这个模型。这个模型里,我们有M个文档主题的Dirichlet分布,而对应的数据有M个主题编号的多项分布,这样(α→θd→z→d)就组成了Dirichlet-multi共轭,可以使用前面提到的贝叶斯推断的方法得到基于Dirichlet分布的文档主题后验分布。
如果在第d个文档中,第k个主题的词的个数为:n(k)d, 则对应的多项分布的计数可以表示为n→d=(nd(1),nd(2),...nd(K))
利用Dirichlet-multi共轭,得到θd的后验分布为:Dirichlet(θd|α→+n→d)
同样的道理,对于主题与词的分布,我们有K个主题与词的Dirichlet分布,而对应的数据有K个主题编号的多项分布,这样η→βk→w→(k))就组成了Dirichlet-multi共轭,可以使用前面提到的贝叶斯推断的方法得到基于Dirichlet分布的主题词的后验分布。
如果在第k个主题中,第v个词的个数为:n(v)k, 则对应的多项分布的计数可以表示为n→k=(nk(1),nk(2),...nk(V))
利用Dirichlet-multi共轭,得到βk的后验分布为:Dirichlet(βk|η→+n→k)
由于主题产生词不依赖具体某一个文档,因此文档主题分布和主题词分布是独立的。理解了上面这M+K组Dirichlet-multi共轭,就理解了LDA的基本原理了。
现在的问题是,基于这个LDA模型如何求解我们想要的每一篇文档的主题分布和每一个主题中词的分布呢?
一般有两种方法,第一种是基于Gibbs采样算法求解,第二种是基于变分推断EM算法求解。