参考:https://blog.csdn.net/wspba/article/details/75671573
若有不对,欢迎指正,先谢了
目前,通常意义上的网络模型压缩,主流思路有两个方向,一个是设计更小的网络模型,这个侧重轻量级网络模型设计,如SqueezeNet,MobileNet,ShuffleNet等,可以根据实际精度要求,不断裁剪模型,调试优化。另外一种思路是网络模型结构不变,通过一定方法减小网络带宽,内存开销,提升速度,主要基于目前多数网络模型存在大量冗余节点,节点权重存在占位浪费等原因,做一定算法实现层面的加速优化。这里所谓的模型压缩,主要是指第二种,即网络结构基本不变,做模型压缩。主要从以下几个方面进行压缩:
模型裁剪,权重共享,核稀疏(正则),量化,二值化,Low-rank分解,知识蒸馏等方向,下图是Distiller实现的几种方案。
基于模型裁剪的方法
对以训练好的模型进行裁剪的方法,是目前模型压缩中使用最多的方法,通常是寻找一种有效的评判手段,来判断参数的重要性,将不重要的connection或者filter进行裁剪来减少模型的冗余。
这里需要注意的是,严格意义上的剪枝,是将不重要的节点权重,激活值清0,而不是删除。其结果只是将模型稀疏化,所以,如果没有指定特定的稀疏矩阵加速库,那么剪枝的加速效果是不明显的。可以对权重,偏置,激活值进行剪枝,但是,偏置对一层的贡献较大,所以,不好对偏置做稀疏化。权重一般是接近0的很小的数,实际上压缩意义也不大(这个看需求,可以将不重要的权重置0,依情况而定),剪枝主要是对Relu类的激活值进行稀疏化,因为其输出具有大概率0值(也要注意,如果激活函数不是这种分布的输出,那么压缩也不明显)。
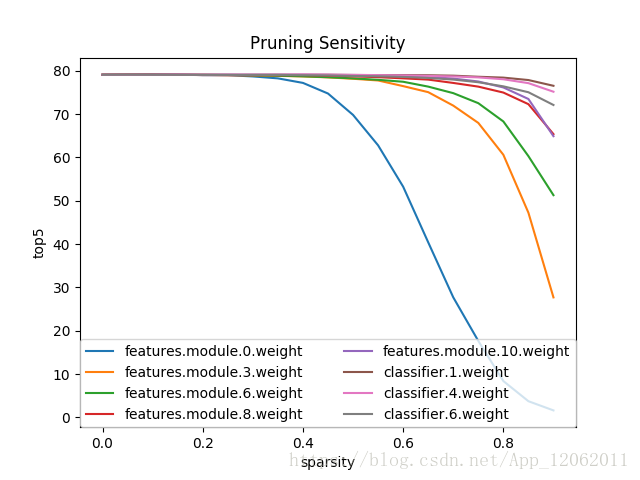
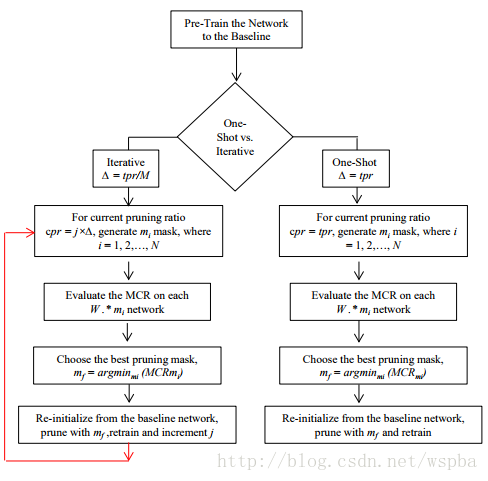
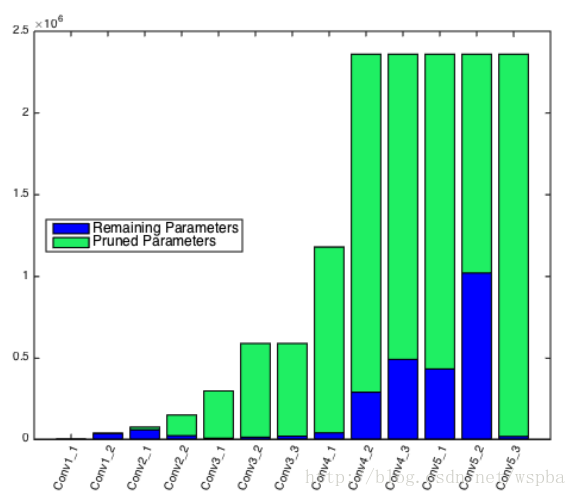
剪枝,需要剪枝准则,通常可以针对每个节点,卷积核,通道,块,调整其稀疏度,然后测试结果,看其对性能的影响,这样,就可以生成敏感性分析报告,从而确定每个节点,卷积核,通道,块的敏感度阈值。这里的稀疏度,用L0范数来定义。如下图:
这类方法最多,下面列举几篇典型的方案。
-
Pruning Filters for Efficient Convnets 论文地址
作者提出了基于量级的裁剪方式,用weight值的大小来评判其重要性,对于一个filter,其中所有weight的绝对值求和,来作为该filter的评价指标,将一层中值低的filter裁掉,可以有效的降低模型的复杂度并且不会给模型的性能带来很大的损失,算法流程如下:
裁剪方式如下:
对于ResNet之类的网络:
作者在裁剪的时候同样会考虑每一层对裁剪的敏感程度,作者会单独裁剪每一层来看裁剪后的准确率。对于裁剪较敏感的层,作者使用更小的裁剪力度,或者跳过这些层不进行裁剪。目前这种方法是实现起来较为简单的,并且也是非常有效的,它的思路非常简单,就是认为参数越小则越不重要。 -
Network Trimming: A Data-Driven Neuron Pruning Approach towards Efficient Deep Architectures 论文地址
作者认为,在大型的深度学习网络中,大部分的神经元的激活都是趋向于零的,而这些激活为0的神经元是冗余的,将它们剔除可以大大降低模型的大小和运算量,而不会对模型的性能造成影响,于是作者定义了一个量APoZ(Average Percentage of Zeros)来衡量每一个filter中激活为0的值的数量,来作为评价一个filter是否重要的标准。APoZ定义如下:
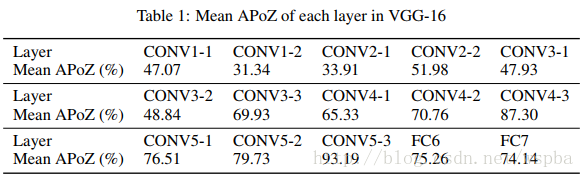
作者发现在VGG-16中,有631个filter的APoZ超过了90%,也就说明了网络中存在大量的冗余。作者的裁剪方式如下:
但是作者仅在最后一个卷积层和全连接层上进行了实验,因此该方法在实际中的效果很难保证。 -
An Entropy-based Pruning Method for CNN Compression 论文地址
作者认为通过weight值的大小很难判定filter的重要性,通过这个来裁剪的话有可能裁掉一些有用的filter。因此作者提出了一种基于熵值的裁剪方式,利用熵值来判定filter的重要性。 作者将每一层的输出通过一个Global average Pooling将feature map转换为一个长度为c(filter数量)的向量,对于n张图像可以得到一个n*c的矩阵,对于每一个filter,将它分为m个bin,统计每个bin的概率,然后计算它的熵值 利用熵值来判定filter的重要性,再对不重要的filter进行裁剪。第j个feature map熵值的计算方式如下:
在retrain中,作者使用了这样的策略,即每裁剪完一层,通过少数几个迭代来恢复部分的性能,当所有层都裁剪完之后,再通过较多的迭代来恢复整体的性能,作者提出,在每一层裁剪过后只使用很少的训练步骤来恢复性能,能够有效的避免模型进入到局部最优。作者将自己的retrain方式与传统的finetuning方式进行比较,发现作者的方法能够有效的减少retrain的步骤,并也能达到不错的效果。
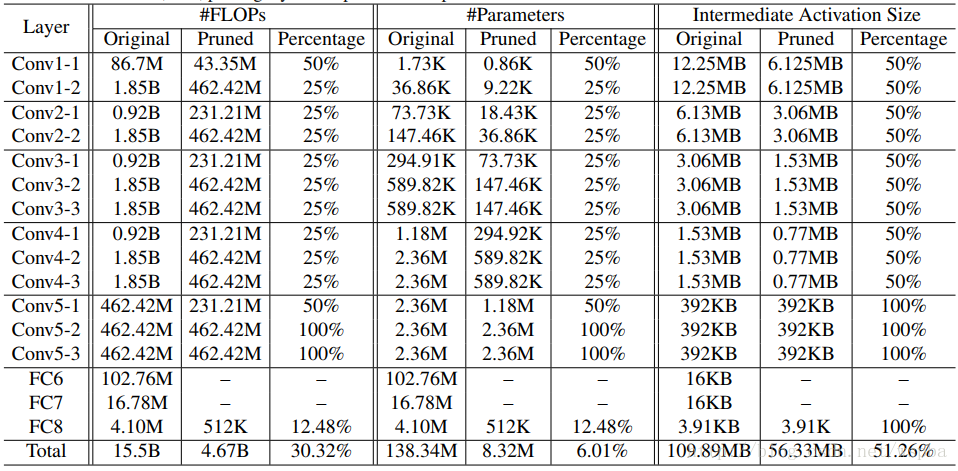
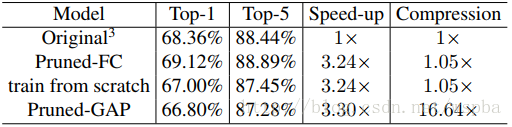
在VGG16上作者的裁剪方式和结果如下,由于作者考虑VGG-16全连接层所占的参数量太大,因此使用GAP的方式来降低计算量: -
Designing Energy-Efficient Convolutional Neural Networks using Energy-Aware Pruning 论文地址
这篇文章也是今天的CVPR,作者认为以往的裁剪方法,都没有考虑到模型的带宽以及能量的消耗,因此无法从能量利用率上最大限度的裁剪模型,因此提出了一种基于能量效率的裁剪方式。 作者指出一个模型中的能量消耗包含两个部分,一部分是计算的能耗,一部分是数据转移的能耗,在作者之前的一片论文中(与NVIDIA合作,Eyeriss),提出了一种估计硬件能耗的工具,能够对模型的每一层计算它们的能量消耗。然后将每一层的能量消耗从大到小排序,对能耗大的层优先进行裁剪,这样能够最大限度的降低模型的能耗,对于需要裁剪的层,根据weight的大小来选择不重要的进行裁剪,同样的作者也考虑到不正确的裁剪,因此将裁剪后模型损失最大的weight保留下来。
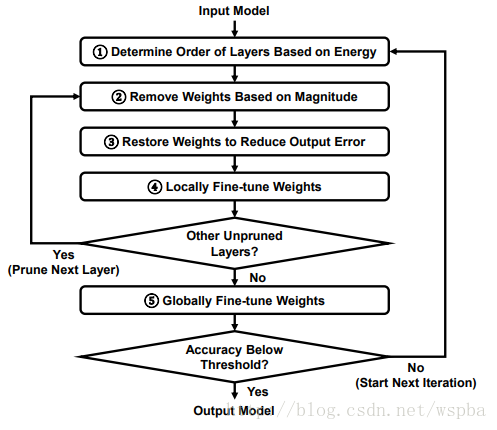
每裁剪完一层后,对于该层进行locally的fine-tune,locally的fine-tune,是在每一层的filter上,使用最小二乘优化的方法来使裁剪后的filter调整到使得输出与原始输出尽可能的接近。在所有层都裁剪完毕后,再通过一个global的finetuning来恢复整体的性能。整个流程如下:
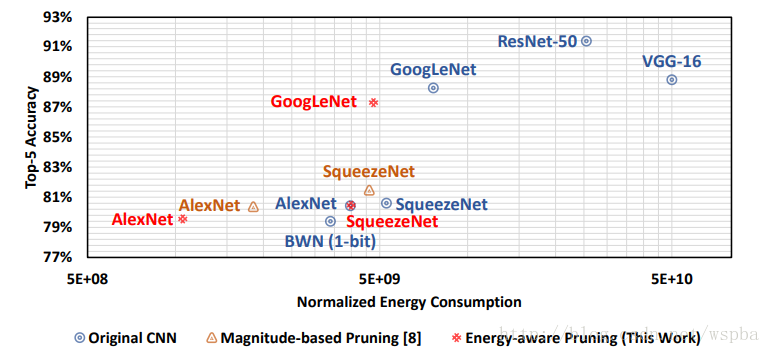
作者从能耗的角度对层的裁剪程度进行分析,经过裁剪后,模型的能耗压缩较大: -
Coarse Pruning of Convolutional Neural Networks with Random Masks 论文地址
此文的方法比较有意思,作者认为,既然我无法直观上的判定filter的重要性,那么就采取一种随机裁剪的方式,然后对于每一种随机方式统计模型的性能,来确定局部最优的裁剪方式。 这种随机裁剪方式类似于一个随机mask,假设有M个潜在的可裁剪weight,那么一共就有2^M个随机mask。假设裁剪比例为a,那么每层就会随机选取ML*a个filter,一共随机选取N组组合,然后对于这N组组合,统计裁剪掉它们之后模型的性能,然后选取性能最高的那组作为局部最优的裁剪方式。 算法流程如下:
作者同样将这种裁剪方式运用在kernel上,对kernel进行裁剪,并将filter级和kernel级的裁剪进行组合,得到了较好的结果。方法简单粗暴,看起来也比较有效,没有考虑每一层对于裁剪的敏感性,也没有评价参数的重要性,可能需要尝试多个mask才能得到较好的结果。
-
Efficient Gender Classification Using a Deep LDA-Pruned Net 论文地址
作者发现,在最后一个卷积层中,经过LDA分析发现对于每一个类别,有很多filter之间的激活是高度不相关的,因此可以利用这点来剔除大量的只具有少量信息的filter而不影响模型的性能。 作者在VGG-16上进行实验,VGG-16的conv5_3具有512个filter,将每一个filter的输出值中的最大值定义为该filter的fire score,因此对应于每一张图片就具有一个512维的fire向量,当输入一堆图片时,就可以得到一个N*512的fire矩阵,作者用intra-class correlation来衡量filter的重要性:
具体实现如下:
其中:
Sw为类内距离,Sb为类间距离,作者这样做的目的是通过只保留对分类任务提取特征判别性最强的filter,来降低模型的冗余。 在前面几个卷积层,由于提取的特征都是很简单的特征,如边缘、颜色,直接对它们求ICC可能难以达到好的效果,因此作者在这些层之后接了deconv层,将特征映射到pixel级别,再来计算。 对于VGG最后用来分类的全连接层,作者认为参数量太大,故用Bayesian或者SVM来替代,在目前的ResNet或者Inception中不存在这样的问题,可以不用考虑。在VGG16上,本文方法裁剪的力度还是比较大的,但是本文作者做的任务为性别识别,在其他任务中的效果未知。 -
Sparsifying Neural Network Connections for Face Recognition 论文地址
本文为2016年的CVPR,应用场景为人脸识别的模型:DeepID。作者认为,如果一层中的某个神经元的激活与上一层的某个神经元的激活有很强的相关性,那么这个神经元对于后面层的激活具有很强的判别性。也就是说,如果前后两层中的某对神经元的激活具有较高的相关性,那么它们之间的连接weight就是非常重要的,而弱的相关性则代表低的重要性。如果某个神经元可以视为某个特定视觉模式的探测器,那么与它正相关的神经元也提供了这个视觉模式的信息,而与它负相关的神经元则帮助减少误报。作者还认为,那些相关性很低的神经元对,它们之间的连接不一定是一点用也没有,它们可能是对于高相关性神经元对的补充。在全连接层中,计算方式如下:
其中 ai 是当前层的一个神经元,上一层有 K 个神经元,为bik。
卷积层的计算方式如下:
其中 aim 是当前层第 i 个feature map中的第 m 神经元,bmk 应该是上一层 feature map 中与aim连接的神经元。
本文的算法流程如下:
作者提供了一个基于神经元激活相关性的重要性判别方法,属于irregular的方法,在计算公式上增加一个求和项可以将这种方法拓展到filter级上。但是作者在实验中并没有对所有的层进行裁剪来比较效果,但是在人脸识别任务上的效果确实是非常好。 -
Pruning Convolutional Neural Networks for Resource Efficient Transfer Learning Inference 论文地址
本文为今年的ICLR,Nvidia的工作,作者将裁剪问题当做一个组合优化问题:从众多的权重参数中选择一个最优的组合B,使得被裁剪的模型的代价函数的损失最小,即:
这类似于Oracle pruning的方式,即通过将每一个weight单独的剔除后看模型损失函数的衰减,将衰减最少的参数认为是不重要的参数,可以剔除,这也是OBD的思路,但是OBD的方法需要求二阶导数,实现起来难度较大,而本文提出的Taylor expansion的方法可以很好的解决这个问题:
其中hi=0表示hi这个feature map被剔除,因此,可以通过将损失函数C在hi=0出进行Taylor展开,因此就可以将损失函数的衰减转化成损失函数对feature map的梯度和feature map激活乘积的绝对值,这样就能够用来评价参数的重要性,由于是一个Global的裁剪,因此将每一个Taylor展开计算得到的值进行标准化:
并将计算量(Flops)考虑进去:
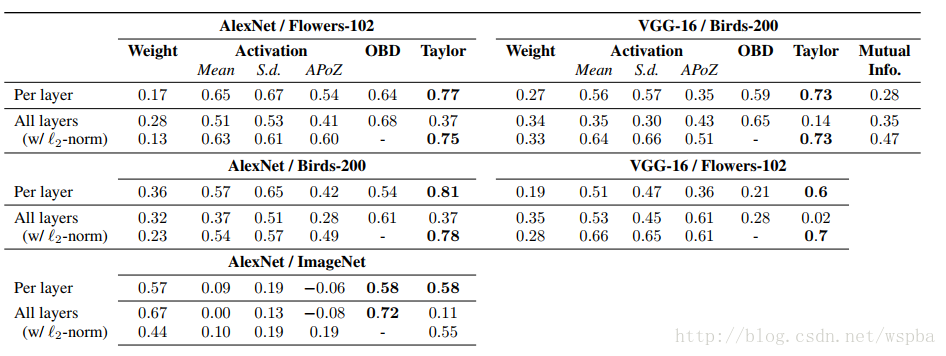
为了评价作者方法的有效性,作者通过Taylor对所有的filter进行评级,然后将评级顺序与Oracle pruning得到的评级顺序计算一个相关性,作者也将其他的裁剪方法,如weight大小、feature map激活等方法分别于Oracle的方法计算相关性,得到的结果如下表:
发现Taylor的方法确实与Oracle的方法最接近的,从上表我们还发现,OBD的效果也与Oracle非常接近,在某些任务上,甚至超过了Taylor的方法,可见这个上世纪80年代提出的方法多么伟大。
本文的方法还有一个优点就是,可以在训练的反向过程中将梯度记录下来,然后与feature map的activation直接相乘,可以达到边训练边裁剪的效果。

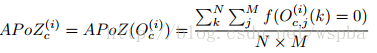
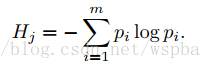

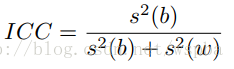
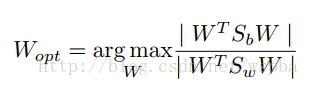
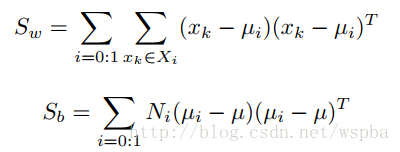
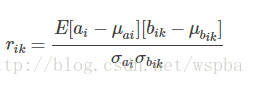
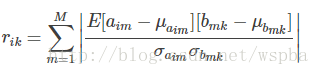

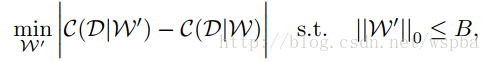
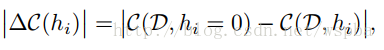
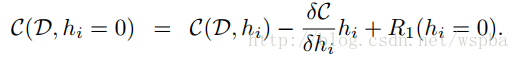
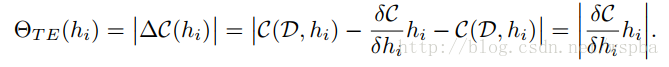
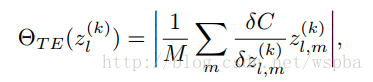
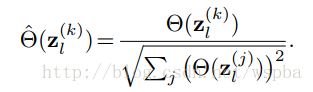
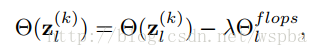
总结
可以看出来,基于模型裁剪的方法很多,其思路源头都是来自于Oracle pruning 的方法,即挑选出模型中不重要的参数,将其剔除而不会对模型的效果造成太大的影响,而如何找到一个有效的对参数重要性的评价手段,在这个方法中就尤为重要,我们也可以看到,这种评价标准花样百出,各有不同,也很难判定那种方法更好。在剔除不重要的参数之后,通过一个retrain的过程来恢复模型的性能,这样就可以在保证模型性能的情况下,最大程度的压缩模型参数及运算量。目前,基于模型裁剪的方法是最为简单有效的模型压缩方式
基于核的稀疏化方法
核的稀疏化,是在训练过程中,对权重的更新加以正则项进行诱导,使其更加稀疏,使大部分的权值都为0。
实际上,我们大多数情况下,在网络loss上面增加的权重衰减,是用权重的L2范数,制约数据损失,起到提高泛化能力的作用,如果再增加一项正则,如下:
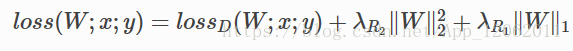
其中第一项数据损失,第二项,权重的L2正则,第三项,稀疏化正则L1,这样也可以起到模型压缩的作用。
另外,上面这种正则是对每个节点进行限制,还有组正则,即指定一个组单位(可以是卷积核,通道,层),进行正则,如下:
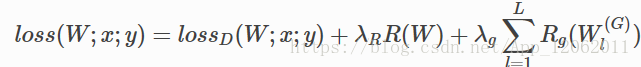
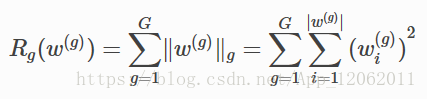
核的稀疏化方法分为regular和irregular,regular的稀疏化后,裁剪起来更加容易,尤其是对im2col的矩阵操作,效率更高;而irregular的稀疏化后,参数需要特定的存储方式,或者需要平台上稀疏矩阵操作库的支持,可以参考的论文有:
-
Learning Structured Sparsity in Deep Neural Networks 论文地址
本文作者提出了一种Structured Sparsity Learning的学习方式,能够学习一个稀疏的结构来降低计算消耗,所学到的结构性稀疏化能够有效的在硬件上进行加速。 传统非结构化的随机稀疏化会带来不规则的内存访问,因此在GPU等硬件平台上无法有效的进行加速。 作者在网络的目标函数上增加了group lasso的限制项,可以实现filter级与channel级以及shape级稀疏化。所有稀疏化的操作都是基于下面的loss func进行的,其中Rg为group lasso:
则filter-channel wise:
而shape wise:
由于在GEMM中将weight tensor拉成matrix的结构,因此可以通过将filter级与shape级的稀疏化进行结合来将2D矩阵的行和列稀疏化,再分别在矩阵的行和列上裁剪掉剔除全为0的值可以来降低矩阵的维度从而提升模型的运算效率。该方法是regular的方法,压缩粒度较粗,可以适用于各种现成的算法库,但是训练的收敛性和优化难度不确定。作者的源码为:https://github.com/wenwei202/caffe/tree/scnn -
Dynamic Network Surgery for Efficient DNNs 论文地址
作者提出了一种动态的模型裁剪方法,包括以下两个过程:pruning和splicing,其中pruning就是将认为不中要的weight裁掉,但是往往无法直观的判断哪些weight是否重要,因此在这里增加了一个splicing的过程,将哪些重要的被裁掉的weight再恢复回来,类似于一种外科手术的过程,将重要的结构修补回来,它的算法如下:
作者通过在W上增加一个T来实现,T为一个2值矩阵,起到的相当于一个mask的功能,当某个位置为1时,将该位置的weight保留,为0时,裁剪。在训练过程中通过一个可学习mask将weight中真正不重要的值剔除,从而使得weight变稀疏。由于在删除一些网络的连接,会导致网络其他连接的重要性发生改变,所以通过优化最小损失函数来训练删除后的网络比较合适。
优化问题表达如下:
参数迭代如下:
其中用于表示网络连接的重要性 h 函数定义如下:
该算法采取了剪枝与嫁接相结合、训练与压缩相同步的策略完成网络压缩任务。通过网络嫁接操作的引入,避免了错误剪枝所造成的性能损失,从而在实际操作中更好地逼近网络压缩的理论极限。属于irregular的方式,但是ak和bk的值在不同的模型以及不同的层中无法确定,并且容易受到稀疏矩阵算法库以及带宽的限制。论文源码:https://github.com/yiwenguo/Dynamic-Network-Surgery -
Training Skinny Deep Neural Networks with Iterative Hard Thresholding Methods 论文地址
作者想通过训练一个稀疏度高的网络来降低模型的运算量,通过在网络的损失函数中增加一个关于W的L0范式可以降低W的稀疏度,但是L0范式就导致这是一个N-P难题,是一个难优化求解问题,因此作者从另一个思路来训练这个稀疏化的网络。算法的流程如下:
先正常训练网络s1轮,然后Ok(W)表示选出W中数值最大的k个数,而将剩下的值置为0,supp(W,k)表示W中最大的k个值的序号,继续训练s2轮,仅更新非0的W,然后再将之前置为0的W放开进行更新,继续训练s1轮,这样反复直至训练完毕。 同样也是对参数进行诱导的方式,边训练边裁剪,先将认为不重要的值裁掉,再通过一个restore的过程将重要却被误裁的参数恢复回来。也是属于irregular的方式,边训边裁,性能不错,压缩的力度难以保证。
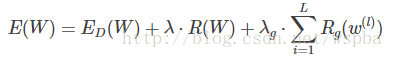
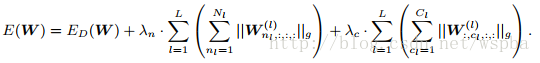
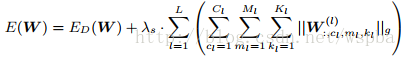

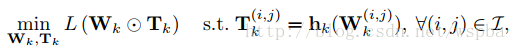
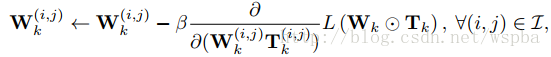
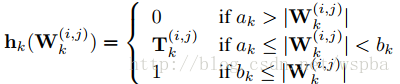

总结
以上三篇文章都是基于核稀疏化的方法,都是在训练过程中,对参数的更新进行限制,使其趋向于稀疏,或者在训练的过程中将不重要的连接截断掉,其中第一篇文章提供了结构化的稀疏化,可以利用GEMM的矩阵操作来实现加速。第二篇文章同样是在权重更新的时候增加限制,虽然通过对权重的更新进行限制可以很好的达到稀疏化的目的,但是给训练的优化增加了难度,降低了模型的收敛性。此外第二篇和第三篇文章都是非结构化的稀疏化,容易受到稀疏矩阵算法库以及带宽的限制,这两篇文章在截断连接后还使用了一个surgery的过程,能够降低重要参数被裁剪的风险。
基于权重共享
实际上,对模型加速,带宽没有太大帮助,主要是存储及内存开销的节省,就是如果一个组块内,存在多个节点的贡献一致,则用一个节点的权重,代替整个组块每个就节点的权重。
基于量化的模型压缩
所谓量化,指的是减少数据在内存中的位数操作,例如,对于权重来说,如果大多数都在0附近,那么32位的浮点表示,其实是有很大浪费的。这一方向的研究,主要是8位类型来表示32位浮点(定点化),甚至直接训练低8位模型,二值模型。其作用不仅可以减少内存开销,同时,可以节省带宽,通过某些定点运算方式,甚至可以消除乘法操作,只剩加法操作,某些二值模型,直接使用位操作。当然,代价是位数越低,精度下降越明显。
一般情况下,采用8位定点运算表示,理论上,可以节省4倍内存,带宽,但是实际上,不是所有的模型参数,都可以定点化,这涉及到性能与加速的平衡。
但是 ,需要注意的是,如果你的模型本身够快,那么8位定点化操作, 可能没有加速或者甚至变慢,因为,浮点转定点,本身也是一笔开销。大量浮点运算是比较慢,但是,模型参数不是很大的情况下,这种慢的差别在现代编译器及硬件环境上几乎体现不出来的,甚至可能量化开销导致性能变慢。
基于教师——学生网络的方法(知识蒸馏)
基于教师——学生网络的方法,属于迁移学习的一种。迁移学习也就是将一个模型的性能迁移到另一个模型上,而对于教师——学生网络,教师网络往往是一个更加复杂的网络,具有非常好的性能和泛化能力,可以用这个网络来作为一个soft target来指导另外一个更加简单的学生网络来学习,使得更加简单、参数运算量更少的学生模型也能够具有和教师网络相近的性能,也算是一种模型压缩的方式。
-
Distilling the Knowledge in a Neural Network 论文地址
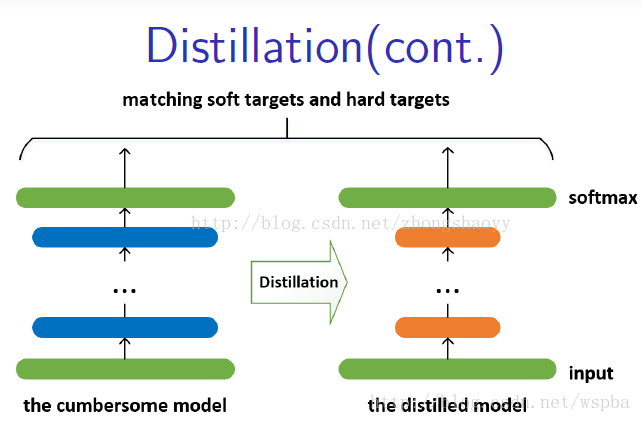
较大、较复杂的网络虽然通常具有很好的性能,但是也存在很多的冗余信息,因此运算量以及资源的消耗都非常多。而所谓的Distilling就是将复杂网络中的有用信息提取出来迁移到一个更小的网络上,这样学习来的小网络可以具备和大的复杂网络想接近的性能效果,并且也大大的节省了计算资源。这个复杂的网络可以看成一个教师,而小的网络则可以看成是一个学生。
这个复杂的网络是提前训练好具有很好性能的网络,学生网络的训练含有两个目标:一个是hard target,即原始的目标函数,为小模型的类别概率输出与label真值的交叉熵;另一个为soft target,为小模型的类别概率输出与大模型的类别概率输出的交叉熵,在soft target中,概率输出的公式调整如下,这样当T值很大时,可以产生一个类别概率分布较缓和的输出:
作者认为,由于soft target具有更高的熵,它能比hard target提供更加多的信息,因此可以使用较少的数据以及较大的学习率。将hard和soft的target通过加权平均来作为学生网络的目标函数,soft target所占的权重更大一些。 作者同时还指出,T值取一个中间值时,效果更好,而soft target所分配的权重应该为T^2,hard target的权重为1。 这样训练得到的小模型也就具有与复杂模型近似的性能效果,但是复杂度和计算量却要小很多。
对于distilling而言,复杂模型的作用事实上是为了提高label包含的信息量。通过这种方法,可以把模型压缩到一个非常小的规模。模型压缩对模型的准确率没有造成太大影响,而且还可以应付部分信息缺失的情况。 -
Paying More Attention to Attention: Improving the Performance of Convolutional Neural Networks via Attention Transfer 论文地址
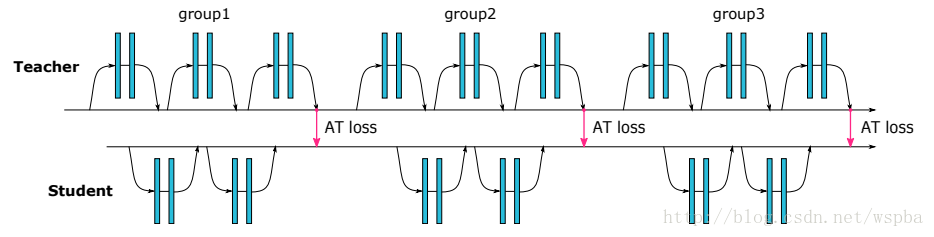
作者借鉴Distilling的思想,使用复杂网络中能够提供视觉相关位置信息的Attention map来监督小网络的学习,并且结合了低、中、高三个层次的特征,示意图如下:
教师网络从三个层次的Attention Transfer对学生网络进行监督。其中三个层次对应了ResNet中三组Residual Block的输出。在其他网络中可以借鉴。 这三个层次的Attention Transfer基于Activation,Activation Attention为feature map在各个通道上的值求和,基于Activation的Attention Transfer的损失函数如下:
其中Qs和Qt分别是学生网络和教师网络在不同层次的Activation向量,作者提出在这里在这里对Q进行标准化对于学生网络的训练非常重要。
除了基于Activation的Attention Transfer,作者还提出了一种Gradient Attention,它的损失函数如下:
但是就需要两次反向传播的过程,实现起来较困难并且效果提升不明显。 基于Activation的Attention Transfer效果较好,而且可以和Hinton的Distilling结合。
目前已有基于Activation的实现源码:https://github.com/szagoruyko/attention-transfer
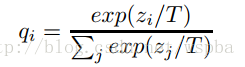
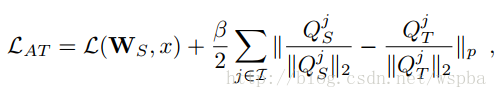
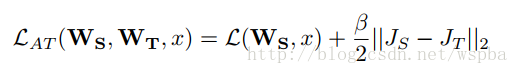
小结
教师学生网络的方法,利用一个性能较好的教师网络,在神经元的级别上,来监督学生网络的训练,相当于提高了模型参数的利用率。其实可以这么来理解,我们一般训练一个神经网络就像是要爬一座山,你的target就是山顶的终点线,给了你一个目标,但是需要你自己去摸索如何找到通往终点的路,你就需要不断学习不断尝试,假如你的体力有效,可能就难以达到目标;但是如果这个时候有一个经验丰富的老司机,他以及达到过终点,那么他就可以为你指明一条上山的路,或者在路上给你立很多路标,你就只要沿着路标上山就好了,这样你也能够很容易的到达山顶,这就是教师——学生网络的意义。
基于Low-rank分解
一个典型的 CNN 卷积核是一个 4D 张量,需要注意的是这些张量中可能存在大量的冗余。而基于张量分解的思想也许是减少冗余的很有潜力的方法。而全连接层也可以当成一个 2D 矩阵,低秩分解同样可行。
所有近似过程都是一层接着一层做的,在一个层经过低秩滤波器近似之后,该层的参数就被固定了,而之前的层已经用一种重构误差标准(reconstruction error criterion)微调过。这是压缩 2D 卷积层的典型低秩方法。
缺陷:低秩方法很适合模型压缩和加速,该方法补充了深度学习的近期发展,如 dropout、修正单元(rectified unit)和 maxout。但是,低秩方法的实现并不容易,因为它涉及计算成本高昂的分解操作。另一个问题是目前的方法逐层执行低秩近似,无法执行非常重要的全局参数压缩,因为不同的层具备不同的信息。最后,分解需要大量的重新训练来达到收敛。