版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_16633405/article/details/82918855
文章目录
1、知道LDA的特点和应用方向
1.1、特点
知道LDA说的降维代表什么含义:将一篇分词后的文章降维为一个主题分布(即如20个特征向量主题)。
根据对应的特征向量中的相关主题概率(20个主题的概率相加为1即为主题分布)得到对应的文档主题,属于无监督学习(你没有给每个数据打标签)
1.2、应用方向
信息提取与搜索(语义分析),文档的分、聚类,文章摘要,计算机视觉,生物信息等方向(只要包含隐变量都可考虑使用)
PS:知道朴素贝叶斯在文本分析的劣势:无法识别一词多义和多词一意。
2、知道Beta分布和Dirichlet分布数学含义
Beta分布概率密度表达式是一条曲线,系数B的表达式是曲线下的面积。
知道二项分布的共轭先验分布是Beta分布,多项分布的共轭先验分布是Dirichlet分布。
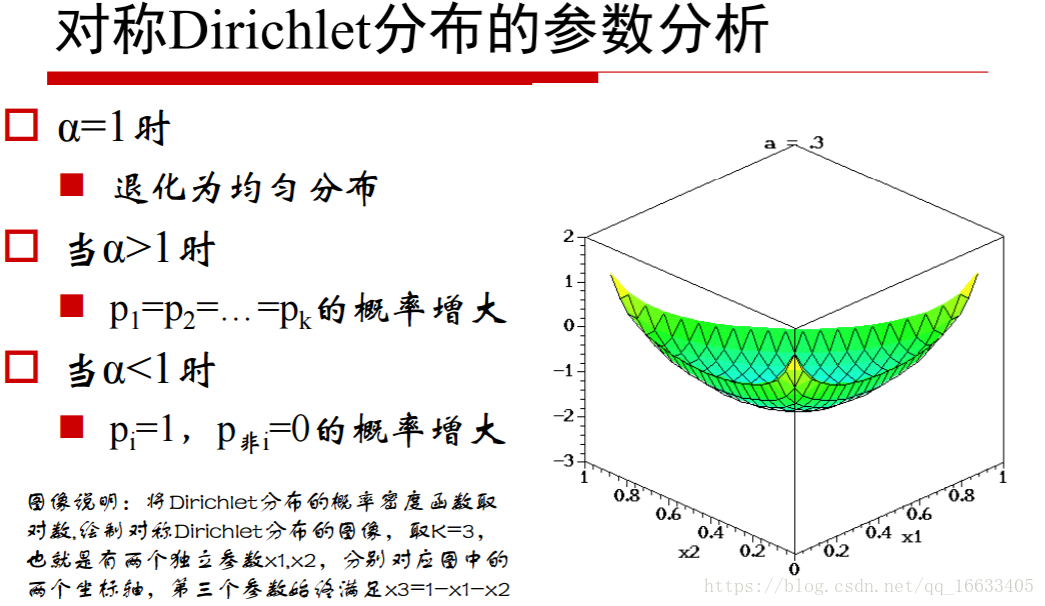
知道Dirichlet分布的概率密度函数的数学含义:当K=3时,密度函数数学含义也就是一个曲面



3、了解共轭先验分布
含义:找个一个先验分布和后验分布都满足于同一种分布的概率分布。这样你知道其中的一个分布就代表知道了另外一个分布。

4、知道先验概率和后验概率
**先验概率:**是指根据以往经验和分析得到的概率.
**后验概率:**事情已经发生,要求这件事情发生的原因是由某个因素引起的可能性的大小
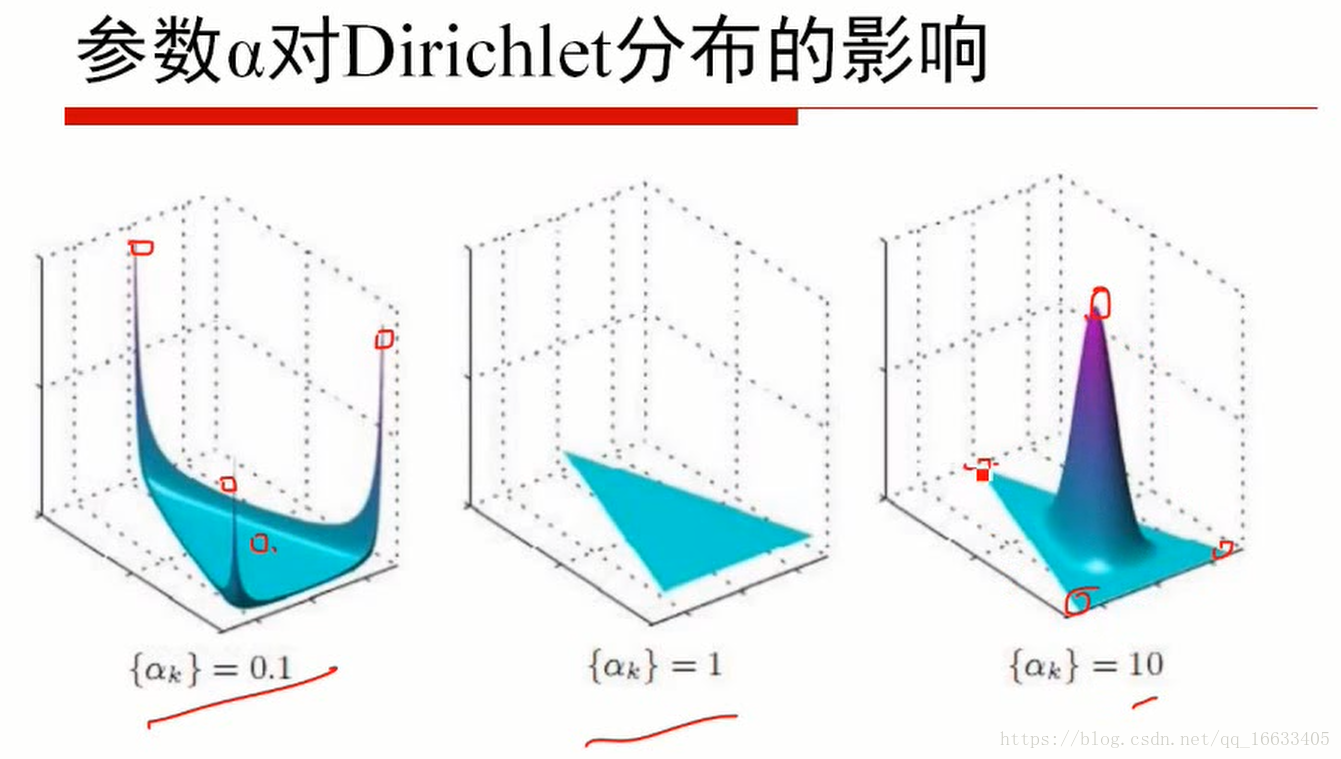
5、知道参数α值的大小对应的含义
当α小于1的时候代表取某一个值的概率很高(即某一主题的概率很高即主题鲜明),=1的时候代表概率为均匀分布,大于1的时候代表k个p相同的概率增大。
对应的z轴就代表这个点对应的概率
6、掌握LDA主题模型的生成过程
总结一句话:主题概率模型生成一个主题分布再生成一个主题,词概率模型生成主题的词分布再生成一个词;最终得到一个主题对应这个词。(连接的条件主题的标号)
掌握整个过程:
θ代表的一个主题分布,即K维的主题向量。


- 从α控制的Dirichlet分布的概率密度函数中采取一个对应的K维的主题分布即θm(第m篇文档的主题)
- 从β控制的Dirichlet分布的概率密度函数中生成K个对应的V维的词分布即φk
- Zm,n即代表第m个文档的第n个主题。当n=2时即代表采到第m篇文档的第二个主题,就到对应的β生成的第二个主题的词分布即φk(对应的第几个主题的词分布)
- 从φk中随机挑选一个词作为Wm,n的值(即第m篇文档第n个主题对应的词)
- 循环执行上述步骤得到每个主题对应的词
PS:各个参数的含义
θm代表第m篇文档的主题分布(m为文档总数)
φk表示第k个主题的词分布(k为主题的个数)
Zm,n代表第m篇文档中的第n个主题
Wm,n代表第m篇文档中的第n个单词

7、知道超参数α等值的参考值

8、LDA总结
- 由于在词和文档之间加入的主题的概念,可以较好的解决一词多义和多词一义的问题。
- 在实践中发现,LDA用于短文档往往效果不明显一这是可以解释的:因为一个词被分配给某个主题的次数和一个主题包括的词数目尚未敛。往往需要通过其他方亲“连接”成长文档。
- 用户评论/Twitter/微博囗LDA可以和其他算法相结合。首先使用LDA将长度Ni的文档降维到K维(主题的数目),同时给出每个主题的概率(主题分布),从而可以使用if-idf继续分析或者直接作为文档的特征进入聚类或者标签传播算法用于社区发现等问题。
- 知道LDA是一个生成模型,由y得到对应的x(y代表的是主题,x代表的词)