制作数据集
import os
import tensorflow as tf
import numpy as np
output_flie = str(os.path.dirname(os.getcwd()))+"/deepcheml/dataset/train.tfrecords"
with tf.python_io.TFRecordWriter(output_flie) as writer:
labels = np.array([[1,0,0,1,0],[0,1,0,0,1],[0,0,0,0,1],[1,0,0,0,0]])
features = np.array([[0,0,0,0,0,0],[1,1,1,1,1,2],[1,1,1,0,0,2],[0,0,0,0,1,9]])
for i in range(4):
label = labels[i]
feature = features[i]
example = tf.train.Example(features=tf.train.Features(feature={
"label": tf.train.Feature(int64_list = tf.train.Int64List(value = label)),
'feature': tf.train.Feature(int64_list = tf.train.Int64List(value = feature))
}))
writer.write(example.SerializeToString())读取数据集
import os
import tensorflow as tf
import numpy as np
def read_tf(output_flie):
filename_queue = tf.train.string_input_producer([output_flie])
reader = tf.TFRecordReader()
_, serialized_example = reader.read(filename_queue)
result = tf.parse_single_example(serialized_example,
features={
'label': tf.FixedLenFeature([], tf.int64),
'feature' : tf.FixedLenFeature([], tf.int64),
})
feature = result['label']
label = result['feature']
return feature,label
output_flie = str(os.path.dirname(os.getcwd()))+"/deepcheml/dataset/train.tfrecords"
feature,label = read_tf(output_flie)
imageBatch, labelBatch = tf.train.batch([feature, label], batch_size=2,capacity=3)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
coord=tf.train.Coordinator()
threads= tf.train.start_queue_runners(sess=sess,coord=coord)
print(1)
images, labels = sess.run([imageBatch, labelBatch])
print(images)
print(labels)
coord.request_stop()
coord.join(threads)会报如下错误:
1
INFO:tensorflow:Error reported to Coordinator: <class 'tensorflow.python.framework.errors_impl.InvalidArgumentError'>, Name: <unknown>, Key: label, Index: 0. Number of int64 values != expected. Values size: 5 but output shape: []
[[Node: ParseSingleExample_3/ParseExample/ParseExample = ParseExample[Ndense=2, Nsparse=0, Tdense=[DT_INT64, DT_INT64], dense_shapes=[[], []], sparse_types=[], _device="/job:localhost/replica:0/task:0/cpu:0"](ParseSingleExample_3/ExpandDims, ParseSingleExample_3/ParseExample/ParseExample/names, ParseSingleExample_3/ParseExample/ParseExample/dense_keys_0, ParseSingleExample_3/ParseExample/ParseExample/dense_keys_1, ParseSingleExample_3/ParseExample/Const, ParseSingleExample_3/ParseExample/Const_1)]]
---------------------------------------------------------------------------
OutOfRangeError Traceback (most recent call last)
/opt/anaconda3/lib/python3.6/site-packages/tensorflow/python/client/session.py in _do_call(self, fn, *args)
1326 try:
-> 1327 return fn(*args)
1328 except errors.OpError as e:
/opt/anaconda3/lib/python3.6/site-packages/tensorflow/python/client/session.py in _run_fn(session, feed_dict, fetch_list, target_list, options, run_metadata)
1305 feed_dict, fetch_list, target_list,
-> 1306 status, run_metadata)
1307
/opt/anaconda3/lib/python3.6/contextlib.py in __exit__(self, type, value, traceback)
87 try:
---> 88 next(self.gen)
89 except StopIteration:
/opt/anaconda3/lib/python3.6/site-packages/tensorflow/python/framework/errors_impl.py in raise_exception_on_not_ok_status()
465 compat.as_text(pywrap_tensorflow.TF_Message(status)),
--> 466 pywrap_tensorflow.TF_GetCode(status))
467 finally:
OutOfRangeError: FIFOQueue '_55_batch_5/fifo_queue' is closed and has insufficient elements (requested 2, current size 0)
[[Node: batch_5 = QueueDequeueManyV2[component_types=[DT_INT64, DT_INT64], timeout_ms=-1, _device="/job:localhost/replica:0/task:0/cpu:0"](batch_5/fifo_queue, batch_5/n)]]
During handling of the above exception, another exception occurred:
OutOfRangeError Traceback (most recent call last)
<ipython-input-6-e2d123f65efb> in <module>()
23 threads= tf.train.start_queue_runners(sess=sess,coord=coord)
24 print(1)
---> 25 images, labels = sess.run([imageBatch, labelBatch])
26 print(images)
27 print(labels)
改正方法就是加上长度具体:
result = tf.parse_single_example(serialized_example,
features={
'label': tf.FixedLenFeature([5], tf.int64),
'feature' : tf.FixedLenFeature([6], tf.int64),再次运行:
1
[[1 0 0 1 0]
[0 1 0 0 1]]
[[0 0 0 0 0 0]
[1 1 1 1 1 2]]如果对于变长还可以这样:
制作数据集(和上面一样,没变)
import os
import tensorflow as tf
import numpy as np
train_TFfile = str(os.path.dirname(os.getcwd()))+"/deepcheml/dataset/hh.tfrecords"
writer = tf.python_io.TFRecordWriter(train_TFfile)
labels = [[1,2,3],[3,4],[5,2,6],[6,4,9],[9]]
features = [[2,5],[3],[5,8],[1,4],[5,9]]
for i in range(5):
label = labels[i]
print(label)
feature = features[i]
example = tf.train.Example(
features = tf.train.Features(
feature = {'label':tf.train.Feature(int64_list = tf.train.Int64List(value = label)),
'feature':tf.train.Feature(int64_list = tf.train.Int64List(value = feature))}))
writer.write(example.SerializeToString())
writer.close()读取数据集:
主要改变的就是:
tf.VarLenFeature(tf.int64)import os
import tensorflow as tf
import numpy as np
def read_tf(output_flie):
filename_queue = tf.train.string_input_producer([output_flie])
reader = tf.TFRecordReader()
_, serialized_example = reader.read(filename_queue)
result = tf.parse_single_example(serialized_example,
features={
'label': tf.VarLenFeature(tf.int64),
'feature' : tf.VarLenFeature(tf.int64),
})
feature = result['feature']
label = result['label']
return feature,label
output_flie = str(os.path.dirname(os.getcwd()))+"/deepcheml/dataset/hh.tfrecords"
Feature,Label = read_tf(output_flie)
Feature_batch, Label_batch = tf.train.batch([Feature, Label], batch_size=2,capacity=3)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
coord=tf.train.Coordinator()
threads= tf.train.start_queue_runners(sess=sess,coord=coord)
for i in range(3):
feature_batch, label_batch = sess.run([Feature_batch, Label_batch])
print(feature_batch)
print(label_batch)
print('---------')
coord.request_stop()
coord.join(threads)运行结果:
SparseTensorValue(indices=array([[0, 0],
[0, 1],
[1, 0]]), values=array([2, 5, 3]), dense_shape=array([2, 2]))
SparseTensorValue(indices=array([[0, 0],
[0, 1],
[0, 2],
[1, 0],
[1, 1]]), values=array([1, 2, 3, 3, 4]), dense_shape=array([2, 3]))
---------
SparseTensorValue(indices=array([[0, 0],
[0, 1],
[1, 0],
[1, 1]]), values=array([5, 8, 1, 4]), dense_shape=array([2, 2]))
SparseTensorValue(indices=array([[0, 0],
[0, 1],
[0, 2],
[1, 0],
[1, 1],
[1, 2]]), values=array([5, 2, 6, 6, 4, 9]), dense_shape=array([2, 3]))
---------
SparseTensorValue(indices=array([[0, 0],
[0, 1],
[1, 0],
[1, 1]]), values=array([5, 9, 2, 5]), dense_shape=array([2, 2]))
SparseTensorValue(indices=array([[0, 0],
[1, 0],
[1, 1],
[1, 2]]), values=array([9, 1, 2, 3]), dense_shape=array([2, 3]))
---------变长的时候什么时候用的多呢?通常当我们为了节省空间采用稀疏表示的时候可能就需要了,为了更加考虑到普遍情况,假设我们遇到的情况还是多标签
假设我们有3个样本,类别有8种,其label分别是:
[0,1,0,0,0,0,0,0]
[1,0,0,0,1,0,0,0]
[0,0,1,1,0,1,0,0]
那我们如果采用稀疏表示就是:
[1]
[0,4]
[2,3,5]
那么我们存储上面即可,那么怎么恢复其原始标签呢?可以借助tf.sparse_to_dense,这里就举一个简单的类子吧:
制作数据集
#提取训练集集指纹和label
import os
import tensorflow as tf
import numpy as np
train_TFfile = str(os.path.dirname(os.getcwd()))+"/deepcheml/dataset/kk.tfrecords"
writer = tf.python_io.TFRecordWriter(train_TFfile)
labels = [[1],[0,4],[2,3,5]]
for i in range(3):
label = labels[i]
example = tf.train.Example(
features = tf.train.Features(
feature = {'label':tf.train.Feature(int64_list = tf.train.Int64List(value = label))}))
writer.write(example.SerializeToString())
writer.close()提取数据集:
import os
import tensorflow as tf
import numpy as np
def read_tf(output_flie):
filename_queue = tf.train.string_input_producer([output_flie])
reader = tf.TFRecordReader()
_, serialized_example = reader.read(filename_queue)
result = tf.parse_single_example(serialized_example,
features={
'label': tf.VarLenFeature(tf.int64),
})
label = result['label']
return label
output_flie = str(os.path.dirname(os.getcwd()))+"/deepcheml/dataset/kk.tfrecords"
Label = read_tf(output_flie)
Label_batch = tf.train.batch([Label], batch_size=3,capacity=3)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
coord=tf.train.Coordinator()
threads= tf.train.start_queue_runners(sess=sess,coord=coord)
label_batch = sess.run(Label_batch)
print(label_batch)
print('---------')
label_x = tf.expand_dims(label_batch.indices[:,0],1)
label_y = tf.expand_dims(label_batch.values,1)
label_index = tf.concat([label_x, label_y],1).eval()
feature = tf.sparse_to_dense(label_index, [3,8], 1.0,0.0,validate_indices=False)
print(sess.run(feature))
coord.request_stop()
coord.join(threads)运行结果:
SparseTensorValue(indices=array([[0, 0],
[1, 0],
[1, 1],
[2, 0],
[2, 1],
[2, 2]]), values=array([1, 0, 4, 2, 3, 5]), dense_shape=array([3, 3]))
---------
[[0. 1. 0. 0. 0. 0. 0. 0.]
[1. 0. 0. 0. 1. 0. 0. 0.]
[0. 0. 1. 1. 0. 1. 0. 0.]]简单说明一下:
从上面可以清楚的看到label_batch的样子,其是由indices,values和dense_shape构成的
label_x是label_batch.indices的第一维度即0,1,1,2,2,2
label_y是label_batch.values即1,0,4,2,3,5
label_index就是一系列坐标,对应到原始label矩阵中就是所有1标签的坐标
需要特别注意validate_indices=False的一定要设为False,不然遇到不是递增的话会报错
在实际训练神经网络的时候,我们可以使用tfrecords+Dataset 来配合开始,不需要从外部feed数据:
举例:
制作数据:还是以多标签为例
#提取训练集集指纹和label
import os
import tensorflow as tf
import numpy as np
train_TFfile = str(os.path.dirname(os.getcwd()))+"/deepcheml/dataset/kk.tfrecords"
writer = tf.python_io.TFRecordWriter(train_TFfile)
labels = [[1,3],[0,4,1],[7,9],[3,2,1,5],[7,5,9,2,1,4]]
for i in range(5):
label = labels[i]
example = tf.train.Example(
features = tf.train.Features(
feature = {'label':tf.train.Feature(int64_list = tf.train.Int64List(value = label))}))
writer.write(example.SerializeToString())
writer.close()import os
import tensorflow as tf
import numpy as np
def read_tf(example_proto):
result = tf.parse_single_example(example_proto,
features={
'label': tf.VarLenFeature(tf.int64),
})
result['label'] = tf.sparse_tensor_to_dense(result['label'])
y = tf.cast(tf.expand_dims(result['label'],1),tf.int32)
x = tf.expand_dims(tf.fill([tf.shape(result['label'])[0]], 0),1)
concated = tf.concat([x, y],1)
result['label'] = tf.sparse_to_dense(concated, [1,10], 1.0,0.0,validate_indices=False)[0]
return result
train_file = str(os.path.dirname(os.getcwd()))+"/deepcheml/dataset/kk.tfrecords"
num_epochs = 2
dataset = tf.contrib.data.TFRecordDataset([train_file])
new_dataset = dataset.map(read_tf)
epoch_dataset = new_dataset.repeat(num_epochs)
# shuffle_dataset = epoch_dataset.shuffle(buffer_size=100)
batch_dataset = epoch_dataset.batch(2)
iterator = batch_dataset.make_one_shot_iterator()
next_element = iterator.get_next()
with tf.Session() as sess:
i=1
while True:
try:
label = sess.run(next_element['label'])
# 如果遍历完了数据集,则返回错误
except tf.errors.OutOfRangeError:
print("End of dataset")
break
else:
# 显示每个样本中的所有feature的信息,只显示scalar的值
print('==============example %s ==============' %i)
print(label)
i+=1运行结果:
==============example 1 ==============
[[0. 1. 0. 1. 0. 0. 0. 0. 0. 0.]
[1. 1. 0. 0. 1. 0. 0. 0. 0. 0.]]
==============example 2 ==============
[[0. 0. 0. 0. 0. 0. 0. 1. 0. 1.]
[0. 1. 1. 1. 0. 1. 0. 0. 0. 0.]]
==============example 3 ==============
[[0. 1. 1. 0. 1. 1. 0. 1. 0. 1.]
[0. 1. 0. 1. 0. 0. 0. 0. 0. 0.]]
==============example 4 ==============
[[1. 1. 0. 0. 1. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 1. 0. 1.]]
==============example 5 ==============
[[0. 1. 1. 1. 0. 1. 0. 0. 0. 0.]
[0. 1. 1. 0. 1. 1. 0. 1. 0. 1.]]
End of dataset在使用这种方法的时候要注意:
在解析的时候即
result['label'] = tf.sparse_tensor_to_dense(result['label'])这句话的主要性,总结如下:
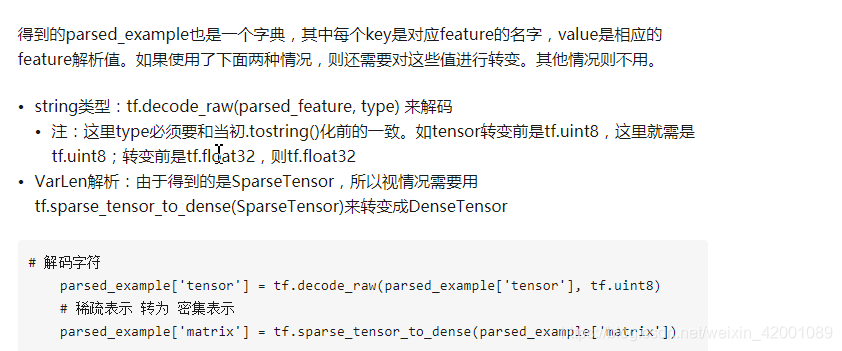
图片源自:https://zhuanlan.zhihu.com/p/33223782
上述博客讲的非常清晰,建议看一下
下面问题待确定:
此外还有一个问题就是,如果使用使用了上面的结构,那么当我们在训练的过程中还想要动态的看一下其在测试集上面的效果,那么这个时候怎么将测试集的数据喂入到网络呢?
假设我们的网络定义如下:
def Net(x):
.....
return result按照上面的情形,我们可以直接:
prediction = Net(next_element['label'])假设现在我们又要看一下其在测试上面的效果,那么怎么办呢?
难道再调用一遍网络?
prediction = Net(test)但是这里调用Net 中的权值参数是否是上面训练集调用中的权值,还是又重新生成了一个网络,很显然又重新了生成了一个,就是说通过训练训练集网络中权值参数不断更新,而测试集的权值一直都是初始化状态,这里的权值和训练集中的权值完全是两回事,两则没有统一,导致的一个结果就是测试集不变,所以这种情况还是要通过feed形式统一喂入比较好