文章目录
一、初始化
self.w_ = [np.random.randn(y, x) for x, y in zip(sizes[:-1], sizes[1:])]
- 首先中括号[ ]表明w_是一个列表。中括号里面的代码用来说明这个列表中是什么内容。
1、np.random.randn(y, x)
numpy.random.randn(d0,d1,…,dn)
- randn函数返回一个或一组样本,具有标准正态分布。
- dn表格每个维度
- 返回值为指定维度的array
np.random.randn() # 当没有参数时,返回单个数据
示例如下:
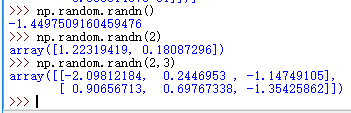
- 所以上面代码中的randn返回y行,x列的正态分布矩阵。
2、 zip(sizes[:-1], sizes[1:])
- zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的对象,这样做的好处是节约了不少的内存。
- 我们可以使用 list() 转换来输出列表。
- 如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 * 号操作符,可以将元组解压为列表。
- 下面看具体的例子来理解zip的使用

- 上面的代码
zip(sizes[:-1], sizes[1:])直接查看main中内容,可知,zip中第一个参数是[784, 40], 第二个参数是[40,10], 所以它的返回值是[(784, 40),(40,10)].
3、 神奇的for循环
先看一个简单的例子

可以把for的这种形式想象成数学中集合的表示,首先说明这个列表中是什么东西,然后说明这些东西满足什么条件。
- 一个稍微复杂点的例子

- 我们在加上randn语句来看看这到底是在干嘛

可以看到,e里面有三个array对象,第一个是1行4列,第二个是2行5列,第三个是3行6列。所以这句是在说e是一个列表,它里面的元素是randn产生的array,有多少次循环就有多少个array,每次array的格式都由x,y循环变量来确定。
4、终于看懂了一句代码
终于我们可以看懂那句代码了self.w_ = [np.random.randn(y, x) for x, y in zip(sizes[:-1], sizes[1:])]w_里面存放的是array,按照main中的输入参数,W_中有两个对象,一个对象是784行40列的正态分布array,另一个对象是40行10列的array。
- 也就是说,第一个array共40列,每一列代表第二层中一个神经元的输入权重(每个神经元有784个输入)。
- 第二个array共10列,每一列代表第三层中一个神经元的输入权重(每个神经元有40个输入)。
- 总结一下,那句代码为权值的存放开辟了内存空间,同时初始化了权值矩阵。
5、偏移初始化
self.b_ = [np.random.randn(y, 1) for y in sizes[1:]]
看懂了上面的那句,这句就不是啥难题了。首先b_同样是一个列表,里面是array对象,这些array对象都只有一列,按照main中传进来的参数,第一个array有40行,每行一个元素,对应神经网络第二层每个神经元的偏移量。第二个array有10行,每行一个元素,对应第三层中每个神经元的偏移量。
二、SGD函数说明
def SGD(self, training_data, epochs, mini_batch_size, eta, test_data=None):
参数说明:
training_data是训练数据(x, y);epochs是训练次数;mini_batch_size是每次训练样本数;eta是learning rate
- 这个函数主体是一个for循环,循环变量epochs控制循环次数,循环次数也是训练几轮。
1、 random.shuffle(training_data)
这句是打乱training_data的内部顺序,因为下面紧跟着就要按照mini_batch_size进行分批,如果不打乱,同一块相同形式的图片可能会被分到同一个batch,导致对训练结果产生负面影响。打乱验证:

2、 mini_batches = [training_data[k:k+mini_batch_size] for k in range(0, n, mini_batch_size)]
这句就是分批了,[ ]表示mini_batche是一个列表,里面的语句来说明它里面到底是什么东西,training_data[k:k+mini_batch_size]说明mini_batches里面的元素是training_data的子集,后面的for语句说明了k所满足的关系:k从0取值每隔mini_batch_size取一个值,直到n,这样就把一个大小为n的训练数据集分成了多个大小为mini_batch_size的子集。分包验证:

self.update_mini_batch(mini_batch, eta)for循环中这句就是真正学习的过程,没学习一个包更新一个权重和偏移。- 然后后面的if语句如果传进来了测试数据集的话就对这一轮的学习结果进行评估,并打印出评估结果。
三、其他函数的简单说明
def sigmoid(self, z):这是sigmiod函数,激活函数,控制每个神经元的输出在0-1范围之内。
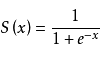
def sigmoid_prime(self, z):Sigmoid函数的导函数,用在反向传播误差,更新权重时。
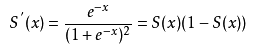
def feedforward(self, x):前馈,根据输入的x,进行一次迭代,返回结果是列表,里面包含输出层神经元应该输出的结果,每层每个神经元使用下面的公式计算输出,然后再把上一层的输出值赋给x继续迭代。
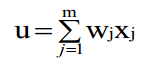
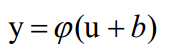
def backprop(self, x, y):误差反向传播更新权值矩阵。x是输入向量,y是标签。- 如果将要计算输出层的更新权重:
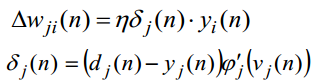
- 如果不是输出层:
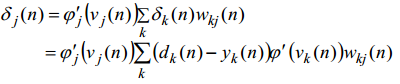
- 如果将要计算输出层的更新权重:
def update_mini_batch(self, mini_batch, eta):更新权重.
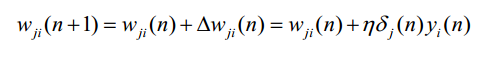
def cost_derivative(self, output_activations, y):返回output_activations和y之差。def load_samples(dataset="training_data"):根据参数加载数据集。并将图像和标签对应起来。def load_mnist(dataset="training_data", digits=np.arange(10), path="."):根据参数从文件中读取相关数据。def evaluate(self, test_data):根据测试数据集对模型进行评估,看有多少识别结果和标签一致。
四、实验结果
- 参看资料:
- 完整代码
附:MNIST数据集文件格式(官网说明翻译)
//括号中的英语是原文中的单词,为防止翻译出现歧义,特意标注
一些说明
- 手写数字MNIST数据库,可以从本页下载(available),它有一个60000个样例的训练数据集和一个10000个样例的测试数据集。它是一个大数据集的子集(可以从NIST下载)。里面的数字已经被尺寸归一化并且集中在固定大小的图像中。
- 它是一个很好的数据集,对想要学习技术或者现实世界数据的模式识别方法而花很少的时间在预处理和格式化上的人来说。
- 四个文件在下面这些站点可下载:
train-images-idx3-ubyte.gz: training set images (9912422 bytes)
train-labels-idx1-ubyte.gz: training set labels (28881 bytes)
t10k-images-idx3-ubyte.gz: test set images (1648877 bytes)
t10k-labels-idx1-ubyte.gz: test set labels (4542 bytes) - 请注意你的浏览器可能在没有通知你的情况下对文件进行解压。 如果你下载的文件大小超过上面说明的大小,他们有可能是被你的浏览器解压了。简单的对它们重新命名去除掉.gz扩展即可。有些人问我“我的程序无法打开你的图像文件”。这些文件并不是任何标准的图像格式。你必须写你自己的程序(非常简单)去读取他们。文件格式在本页的下面进行了描述。
- NIST对原始的黑白(双水平)图像进行了尺寸标准化,以适合于20x20像素的盒子(box),同时保留了它们的高宽比。由于归一化算法使用了抗混叠技术,所以结果图片包含灰度级。通过计算像素的质心,将图像中心化到一个28x28的图像中,然后平移图像,使这个点位于28x28区域的中心。
MNIST数据集文件格式
- 数据存储在一个非常简单的文件格式中,这种格式用来存储向量和多维矩阵。这种格式的一般信息在本页的末尾给出,但是你不需要为了使用文件而去读那些东西。
- 所有在文件中的整数都用大多数非intel处理器使用的MSB优先(high endian)格式存储。intel处理器的使用者和其他low-endian机器必须翻转头部字节.
- 有四个文件
train-images-idx3-ubyte: training set images
train-labels-idx1-ubyte: training set labels
t10k-images-idx3-ubyte: test set images
t10k-labels-idx1-ubyte: test set labels
-
训练数据集包含60000个样例,测试数据集包含10000个样例。
扫描二维码关注公众号,回复: 6395901 查看本文章
-
测试数据集的前5000个样例取自原始NIST训练集。后5000个取自原始NIST测试集。前5000个比后5000个更加清晰容易。

Pixels are organized row-wise. Pixel values are 0 to 255. 0 means background (white), 255 means foreground (black).

Pixels are organized row-wise. Pixel values are 0 to 255. 0 means background (white), 255 means foreground (black). -
运行下面的程序之前你应该清楚:
- 新建文件夹test(也可以是其它名字),然后将程序(pythonBP.py)放在test文件夹下
- 在test下新建文件夹MNIST_data(必须是这个名字),将上面下载下来的四个GZ压缩格式的数据集进行解压缩,并放在MNIST_data文件夹下面 。
- 最终的文件关系如下:
test |---pythonBP.py |---MNIST_data |----train-images.idx3-ubyte |----train-labels.idx1-ubyte |----t10k-images.idx3-ubyte |----t10k-labels.idx1-ubyte- 由于这个程序中使用到了numpy库,所以如果你之前没有安装过这个库的话,你需要用下面的命令在命令行来安装这个库
python -m pip install --user numpy- 开始运行安装命令后出现如下界面,耐心等待它下载安装:

- 安装完毕以后,在IDLE中进行测试是否安装好,如果没有报错,说明安装好了。如下图
- 开始运行安装命令后出现如下界面,耐心等待它下载安装:
-
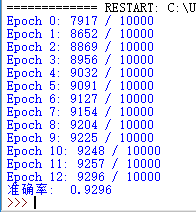
程序正常运行结果如下图:

# pythonBP.py
import numpy as np
import random
import os, struct
from array import array as pyarray
from numpy import append, array, int8, uint8, zeros
class NeuralNet(object):
# 初始化神经网络,sizes是神经网络的层数和每层神经元个数
def __init__(self, sizes):
self.sizes_ = sizes
self.num_layers_ = len(sizes) # 层数
self.w_ = [np.random.randn(y, x) for x, y in zip(sizes[:-1], sizes[1:])] # w_、b_初始化为正态分布随机数
self.b_ = [np.random.randn(y, 1) for y in size........s[1:]]
# Sigmoid函数,S型曲线,
def sigmoid(self, z):
return 1.0/(1.0+np.exp(-z))
# Sigmoid函数的导函数
def sigmoid_prime(self, z):
return self.sigmoid(z)*(1-self.sigmoid(z))
def feedforward(self, x):
for b, w in zip(self.b_, self.w_):
x = self.sigmoid(np.dot(w, x)+b)
return x
def backprop(self, x, y):
nabla_b = [np.zeros(b.shape) for b in self.b_]
nabla_w = [np.zeros(w.shape) for w in self.w_]
activation = x
activations = [x]
zs = []
for b, w in zip(self.b_, self.w_):
z = np.dot(w, activation)+b
zs.append(z)
activation = self.sigmoid(z)
activations.append(activation)
delta = self.cost_derivative(activations[-1], y) * \
self.sigmoid_prime(zs[-1])
nabla_b[-1] = delta
nabla_w[-1] = np.dot(delta, activations[-2].transpose())
for l in range(2, self.num_layers_):
z = zs[-l]
sp = self.sigmoid_prime(z)
delta = np.dot(self.w_[-l+1].transpose(), delta) * sp
nabla_b[-l] = delta
nabla_w[-l] = np.dot(delta, activations[-l-1].transpose())
return (nabla_b, nabla_w)
def update_mini_batch(self, mini_batch, eta):
nabla_b = [np.zeros(b.shape) for b in self.b_]
nabla_w = [np.zeros(w.shape) for w in self.w_]
for x, y in mini_batch:
delta_nabla_b, delta_nabla_w = self.backprop(x, y)
nabla_b = [nb+dnb for nb, dnb in zip(nabla_b, delta_nabla_b)]
nabla_w = [nw+dnw for nw, dnw in zip(nabla_w, delta_nabla_w)]
self.w_ = [w-(eta/len(mini_batch))*nw for w, nw in zip(self.w_, nabla_w)]
self.b_ = [b-(eta/len(mini_batch))*nb for b, nb in zip(self.b_, nabla_b)]
# training_data是训练数据(x, y);epochs是训练次数;mini_batch_size是每次训练样本数;eta是learning rate
def SGD(self, training_data, epochs, mini_batch_size, eta, test_data=None):
if test_data:
n_test = len(test_data)
n = len(training_data)
for j in range(epochs):
random.shuffle(training_data)
mini_batches = [training_data[k:k+mini_batch_size] for k in range(0, n, mini_batch_size)]
for mini_batch in mini_batches:
self.update_mini_batch(mini_batch, eta)
if test_data:
print("Epoch {0}: {1} / {2}".format(j, self.evaluate(test_data), n_test))
else:
print("Epoch {0} complete".format(j))
def evaluate(self, test_data):
test_results = [(np.argmax(self.feedforward(x)), y) for (x, y) in test_data]
return sum(int(x == y) for (x, y) in test_results)
def cost_derivative(self, output_activations, y):
return (output_activations-y)
# 预测
def predict(self, data):
value = self.feedforward(data)
return value.tolist().index(max(value))
# 保存训练模型
def save(self):
pass # 把_w和_b保存到文件(pickle)
def load(self):
pass
def load_mnist(dataset="training_data", digits=np.arange(10), path="."):
if dataset == "training_data":
fname_image = os.path.join(path, 'MNIST_data/train-images.idx3-ubyte')
fname_label = os.path.join(path, 'MNIST_data/train-labels.idx1-ubyte')
elif dataset == "testing_data":
fname_image = os.path.join(path, 'MNIST_data/t10k-images.idx3-ubyte')
fname_label = os.path.join(path, 'MNIST_data/t10k-labels.idx1-ubyte')
else:
raise ValueError("dataset must be 'training_data' or 'testing_data'")
flbl = open(fname_label, 'rb')
magic_nr, size = struct.unpack(">II", flbl.read(8))
lbl = pyarray("b", flbl.read())
flbl.close()
fimg = open(fname_image, 'rb')
magic_nr, size, rows, cols = struct.unpack(">IIII", fimg.read(16))
img = pyarray("B", fimg.read())
fimg.close()
ind = [ k for k in range(size) if lbl[k] in digits ]
N = len(ind)
images = zeros((N, rows, cols), dtype=uint8)
labels = zeros((N, 1), dtype=int8)
for i in range(len(ind)):
images[i] = array(img[ ind[i]*rows*cols : (ind[i]+1)*rows*cols ]).reshape((rows, cols))
labels[i] = lbl[ind[i]]
return images, labels
def load_samples(dataset="training_data"):
image,label = load_mnist(dataset)
X = [np.reshape(x,(28*28, 1)) for x in image]
X = [x/255.0 for x in X] # 灰度值范围(0-255),转换为(0-1)
# 5 -> [0,0,0,0,0,1.0,0,0,0]; 1 -> [0,1.0,0,0,0,0,0,0,0]
def vectorized_Y(y):
e = np.zeros((10, 1))
e[y] = 1.0
return e
if dataset == "training_data":
Y = [vectorized_Y(y) for y in label]
pair = list(zip(X, Y))
return pair
elif dataset == 'testing_data':
pair = list(zip(X, label))
return pair
else:
print('Something wrong')
if __name__ == '__main__':
INPUT = 28*28
OUTPUT = 10
net = NeuralNet([INPUT, 40, OUTPUT])#传进去的是一个链表,分别表示每一层的神经元个数,而链表的长度刚好就是神经网络的层数
train_set = load_samples(dataset='training_data')
test_set = load_samples(dataset='testing_data')
net.SGD(train_set, 13, 100, 3.0, test_data=test_set)
#准确率
correct = 0;
for test_feature in test_set:
if net.predict(test_feature[0]) == test_feature[1][0]:
correct += 1
print("准确率: ", correct/len(test_set))