PyTorch是使用GPU和CPU优化的深度学习张量库。基础参考资料和官方中文文档链接如下:
https://www.cnblogs.com/wj-1314/p/9830950.html
https://pytorch-cn.readthedocs.io/zh/latest/
手写数字识别是卷积神经网络其中一个比较传统的应用,搭建网络的思想来自于Lenet-5,处理过程中进行了一些简化。
step1 运行环境
1、Windows 10 64位
2、Visual Studio Code 1.38.1
3、Anaconda4.4.0 (Python3.6.2)
4、Pytorch 1.1.0 (CUDA9.0 CUDNN7.5)
5、OpenCV 3.4.3
step2 下载数据集/搭建网络/训练网络/保存模型
数据集:
Pytorch提供了常用数据集的下载,以及经典网络的结构,可以对经典网络根据需求进行微调。(参考:https://www.cnblogs.com/kk17/p/10156160.html)
MNIST数据集官方网站:http://yann.lecun.com/exdb/mnist/
共有4个文件:

实现手写数字的完整代码如下:
# 手写数字识别(MNIST数据集)
import torch
import torchvision
from torchvision import datasets,transforms #处理计算机视觉相关问题的包
from torch.autograd import Variable #自动求导包
import time #记录系统时间
import cv2 #OpenCV
# 将数据集的数据类型转换为pytorch能够处理的Tensor类型
transform=transforms.Compose([transforms.ToTensor()])
# 将数据集的数据进行标准化(自定义均值和标准差)
transforms.Normalize(mean=[0.5,0.5,0.5],std=[0.5,0.5,0.5])
# 下载数据集
# 如果已经下载完成,指定目录下存在数据集文件,可以将download选项置为False,避免重复下载
data_train=datasets.MNIST(root="./data/",transform=transform,train=True,download=False)
data_test=datasets.MNIST(root="./data/",transform=transform,train=False)
# 加载数据集
# shuffle置为True,加载过程中会将数据随机打乱并进行打包
data_loader_train=torch.utils.data.DataLoader(dataset=data_train,batch_size=64,shuffle=True)
data_loader_test=torch.utils.data.DataLoader(dataset=data_test,batch_size=64,shuffle=True)
# 预览数据
images,labels=next(iter(data_loader_train)) # 获取每个批次的图片数据和对应标签
img=torchvision.utils.make_grid(images) # 将一个批次的图片构造成网格模式
img=img.numpy().transpose(1,2,0) # 类型转换和维度交换
std=[0.5,0.5,0.5]
mean=[0.5,0.5,0.5]
img=img*std+mean
print(labels) # 打印每个批次图片数据对应标签
cv2.namedWindow("train_sample",cv2.WINDOW_NORMAL)
cv2.imshow("train_sample",img) # 显示每个批次图片数据
cv2.waitKey(100)
# 搭建卷积神经网络类
class Model(torch.nn.Module):
def __init__(self):
super(Model,self).__init__()
# 卷积层
self.conv1=torch.nn.Sequential(
torch.nn.Conv2d(1,64,kernel_size=3,stride=1,padding=1),
torch.nn.ReLU(),
torch.nn.Conv2d(64,128,kernel_size=3,stride=1,padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(stride=2,kernel_size=2))
# 全连接层
self.dense=torch.nn.Sequential(
torch.nn.Linear(14*14*128,1024),
torch.nn.ReLU(),
torch.nn.Dropout(p=0.5),
torch.nn.Linear(1024,10))
def forward(self,x):
x=self.conv1(x)
x=x.view(-1,14*14*128) # 将参数扁平化,否则输入至全连接层会报错
x=self.dense(x)
return x
# 对建立的模型进行实例化
model=Model()
print(model) # 打印模型结构
# 如果有GPU,将所有模型参数处理为cuda类型
# 否则,不作任何处理
if torch.cuda.is_available():
print("GPU state:",torch.cuda.is_available())
model.cuda()
# 如果有GPU,将数据处理为cuda类型
# 否则,将数据处理为Variable类型
def Transfer_Variable_or_Cuda(x):
if torch.cuda.is_available():
x=x.cuda()
return Variable(x)
# 定义损失函数类型为交叉熵类型
cost=torch.nn.CrossEntropyLoss()
# 定义模型参数优化方法为Adam
optimizer=torch.optim.Adam(model.parameters())
n_epochs=5 # 设置训练迭代次数
print("starting training...")
start_time = time.time() # 记录训练开始时刻
for epoch in range(n_epochs):
print("Epoch{}/{}".format(epoch,n_epochs))
print("-"*10)
# 训练数据集
running_loss=0.0 # 初始误差
running_correct=0 # 初始分类正确样本数
for data in data_loader_train:
# 获取数据并处理
X_train,Y_train=data
X_train,Y_train=Transfer_Variable_or_Cuda(X_train),Transfer_Variable_or_Cuda(Y_train)
# 前向传播 softmax返回每个类别对应的概率
outputs=model(X_train)
# torch.max()[1] 返回最大值对应的索引(最大概率对应的索引,即数字)
_,pred=torch.max(outputs.data,1)
# 模型参数梯度清零
optimizer.zero_grad()
loss=cost(outputs,Y_train)
loss.backward()
# 更新梯度
optimizer.step()
# 误差累计
running_loss+=loss.item()
# 训练集中分类正确样本数,用于后续计算模型在训练集上的准确度
running_correct+=torch.sum(pred==Y_train.data)
# 测试数据集
testing_correct=0 # 初始分类正确样本数
for data in data_loader_test:
# 获取数据并处理
X_test,Y_test=data
X_test,Y_test=Transfer_Variable_or_Cuda(X_test),Transfer_Variable_or_Cuda(Y_test)
# 前向传播 softmax返回每个类别对应的概率
outputs=model(X_test)
# torch.max()[1] 返回最大值对应的索引(最大概率对应的索引,即数字)
_,pred=torch.max(outputs.data,1)
# 测试集中分类正确样本数,用于后续计算模型在测试集上的准确度
testing_correct+=torch.sum(pred==Y_test.data)
# 每轮训练迭代,输出训练误差/训练集准确度/测试集准确度
print("Loss is:{:.4f},Train Accuracy is:{:.4f}%,Test Accuracy is:{:.4f}%".format(
running_loss/len(data_train),100*running_correct/len(data_train),
100*testing_correct/len(data_test)))
stop_time = time.time() # 记录训练结束时刻
print("training time is:{:.4f}s".format(stop_time-start_time)) # 输出训练时长(s)
# 保存训练的模型,pkl格式
# model.state_dict() 只保存网络的参数,速度快,不保存网络的计算图
# model 保存全部网络结构和训练参数
# 读入训练好的网络时,需要建立一个与原来网络结构相同的新网络,才能进行网络参数的复制
torch.save(model, './data/mnist.pkl')
print("save model successfully!")
# 测试样本可视化
test_correct=0 # 初始分类正确样本数
batch_size=10 # batch_size 为测试时使用的数据数量
data_loader_test=torch.utils.data.DataLoader(dataset=data_test,batch_size=batch_size,shuffle=True)
# 获取数据并处理
X_test,Y_test=next(iter(data_loader_test))
X_test,Y_test=Transfer_Variable_or_Cuda(X_test),Transfer_Variable_or_Cuda(Y_test)
# 前向传播
outputs=model(X_test)
_,pred=torch.max(outputs.data,1)
test_correct+=torch.sum(pred==Y_test.data)
print("Predict label is:",[i for i in pred.data])
print("Real label is:",[i for i in Y_test.data])
print("Test Accuracy is:{:.4f}%".format(100*test_correct/batch_size))
img=torchvision.utils.make_grid(X_test)
# 在gpu上处理完所有数据返回后,需要将其转换为cpu类型
img=img.cpu().numpy().transpose(1,2,0)
std=[0.5,0.5,0.5]
mean=[0.5,0.5,0.5]
img=img*std+mean
cv2.namedWindow("test_sample",cv2.WINDOW_NORMAL)
cv2.imshow("test_sample",img)
cv2.waitKey(0)
step3 测试
训练数据集(部分):
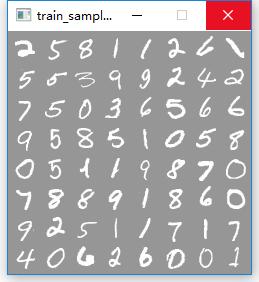
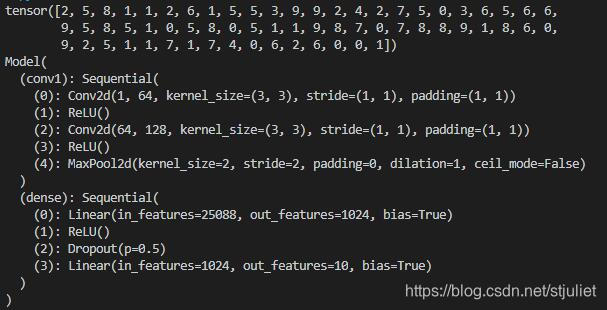
训练数据集(部分)标签/模型结构:
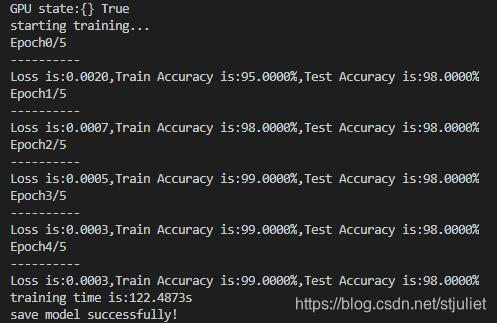
GPU状态,True表示可用/开始训练/保存模型成功:
选取测试集中的10个样本进行测试:
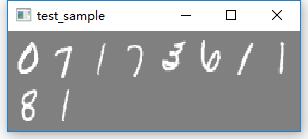
测试结果(全部识别正确):

如何读取训练好的模型?
在保存全部网络结构和训练参数的情况下,如果要读取已训练好的模型文件,可以使用以下代码,同时仍需加上搭建模型时的类,否则会报错。
model=torch.load('./data/mnist.pkl').cuda()
只保存网络训练参数的情况,也需要加上搭建模型时的类,再使用以下代码:
model = Model()
if torch.cuda.is_available():
model.cuda()
model.load_state_dict(torch.load('./data/mnist_params.pkl'))
参考文章:
https://www.cnblogs.com/wj-1314/p/9842719.html
https://blog.csdn.net/panrenlong/article/details/81736754
https://blog.csdn.net/manong_wxd/article/details/78592915
https://blog.csdn.net/e01528/article/details/84981058
https://blog.csdn.net/qq_29631521/article/details/92806793
https://akimoto-cris.github.io/2019/03/14/load_state_dict/index.html
Juliet 于 2019.10