文章目录
前言
计算机视觉系列之学习笔记主要是本人进行学习人工智能(计算机视觉方向)的代码整理。本系列所有代码是用python3编写,在平台Anaconda中运行实现,在使用代码时,默认你已经安装相关的python库,这方面不做多余的说明。本系列所涉及的所有代码和资料可在我的github或者码云上下载到,gitbub地址:https://github.com/mcyJacky/DeepLearning-CV,如有问题,欢迎指出~。
一、BP(Back Propagation)神经网络简介
1.1 什么是BP神经网络
相对于单层感知器,BP神经网络是为了解决神经网络多层学习问题。如下图为3层神经网络结构图。
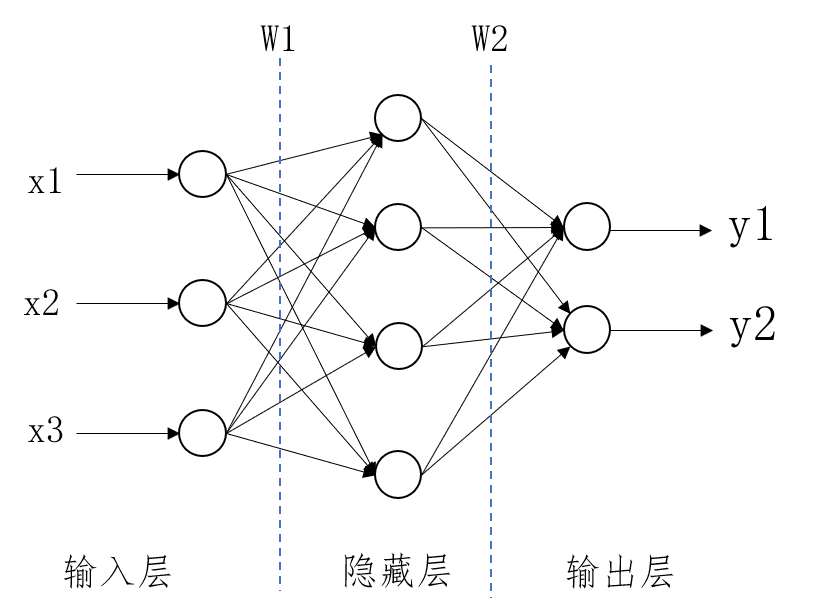
如图1.1所示,该神经网络由三层组成:输入层、隐藏层和输出层。输入层有3个特征节点作为输入,隐藏层有4个神经单元,输出层有2个神经单元。连接输入层和隐藏层的权值矩阵是
,连接隐藏层和输出层的权值矩阵是
。即正向传播的公式为:
其中,
为权值矩阵,
为偏置项,
为第i层预测结果,
为第i层激活函数。
1.2 BP神经网络推导结果
通过正向传播公式可以反推出反向传播的公式,这边不做具体的推导,而是直接给出BP神经网络反向传播的推导结果,推导过程请参考相关书籍或资料。误差函数为:
其中
为实际正确的标签值,
为通过神经网络预测的值。
其中
为神经网络的某一层,
为第
层至第
层的权值矩阵,
为第
层的输出信号。
其中
为为第
层至第
层的权值矩阵梯度变化,
为学习速率。其中
由下式表示:
其中
为神经网络的输出层的学习信号,
为神经网络的第
层的学习信号,
为第
层至第
层的权值阵,
为第
层的输入信号。
二、BP神经网络识别手写数字的应用
在此次应用中,我们使用sklearn库中的数字集的数据。它是由1797张手写数字图片组成,图片的像素是8x8。具体如下所示:
import numpy as np
from sklearn.datasets import load_digits #手写数字数据集
from sklearn.preprocessing import LabelBinarizer #标签二值化处理
from sklearn.model_selection import train_test_split #训练和测试集分隔
from sklearn.metrics import classification_report, confusion_matrix
import matplotlib.pyplot as plt
# 载入数据
digits = load_digits()
print(digits.images.shape) #结果:(1797, 8, 8)
# 输入的数据
X = digits.data
# 标签数据
T = digits.target
print(X.shape, X[:2], '\n')
print(T.shape, T[:2])
# 结果:
# (1797, 64) [[ 0. 0. 5. 13. 9. 1. 0. 0. 0. 0. 13. 15. 10. 15. 5. 0. 0. 3.
# 15. 2. 0. 11. 8. 0. 0. 4. 12. 0. 0. 8. 8. 0. 0. 5. 8. 0.
# 0. 9. 8. 0. 0. 4. 11. 0. 1. 12. 7. 0. 0. 2. 14. 5. 10. 12.
# 0. 0. 0. 0. 6. 13. 10. 0. 0. 0.]
# [ 0. 0. 0. 12. 13. 5. 0. 0. 0. 0. 0. 11. 16. 9. 0. 0. 0. 0.
# 3. 15. 16. 6. 0. 0. 0. 7. 15. 16. 16. 2. 0. 0. 0. 0. 1. 16.
# 16. 3. 0. 0. 0. 0. 1. 16. 16. 6. 0. 0. 0. 0. 1. 16. 16. 6.
# 0. 0. 0. 0. 0. 11. 16. 10. 0. 0.]]
# (1797,) [0 1]
# 定义一个神经网络 64-100-10,隐藏层神经元单元为100,输出层神经元单元为10
# 输入层至隐藏层的权值矩阵
V = np.random.random([64,100])*2 -1
# 隐藏层至输出层的权值矩阵
W = np.random.random([100,10])*2 -1
# 数据切分,默认测试集占0.25
X_train,X_test,y_train,y_test = train_test_split(X,T)
# 标签二值化,独热编码
# 1 -> 0100000000
labels_train = LabelBinarizer().fit_transform(y_train)
print(y_train[:2])
print(labels_train[:2])
#打印结果:
#[5 9]
#[[0 0 0 0 0 1 0 0 0 0]
#[0 0 0 0 0 0 0 0 0 1]]
# 激活函数
def sigmoid(x):
return 1/(1+np.exp(-x))
# 激活函数的导数
def dsigmoid(x):
return x*(1-x)
#预测值计算
def predict(x):
L1 = sigmoid(np.dot(x,V))
L2 = sigmoid(np.dot(L1,W))
return L2
#模型训练
def train(X, T, steps=10000, lr=0.11):
global V,W
for n in range(steps + 1):
#从样本中随机选取一个数据
i = np.random.randint(X.shape[0])
x = X[i]
x = np.atleast_2d(x) #转换为2D矩阵
#BP算法公式
L1 = sigmoid(np.dot(x,V))
L2 = sigmoid(np.dot(L1,W))
L2_delta = (T[i] - L2)*dsigmoid(L2)
L1_delta = L2_delta.dot(W.T)*dsigmoid(L1)
W += lr * L1.T.dot(L2_delta)
V += lr * x.T.dot(L1_delta)
if n%1000 == 0:
output = predict(X_test)
predictions = np.argmax(output, axis=1)
acc = np.mean(np.equal(predictions, y_test))
print('iter: ' + str(n + 1) + " acc: " + str(acc))
train(X_train,labels_train,30000)
#输出结果:
# iter: 1 acc: 0.8644444444444445
# iter: 1001 acc: 0.8733333333333333
# iter: 2001 acc: 0.8688888888888889
# ...
# iter: 5001 acc: 0.8711111111111111
# ...
# iter: 22001 acc: 0.8666666666666667
# iter: 23001 acc: 0.8711111111111111
#....
# iter: 28001 acc: 0.8711111111111111
# iter: 29001 acc: 0.8666666666666667
# iter: 30001 acc: 0.8711111111111111
# 结果评估
output = predict(X_test)
predictions = np.argmax(output,axis=1)
print(classification_report(predictions,y_test))
# precision recall f1-score support
# 0 1.00 0.88 0.93 49
# 1 1.00 0.82 0.90 60
# 2 1.00 1.00 1.00 45
# 3 0.93 0.98 0.95 43
# 4 0.00 0.00 0.00 0
# 5 0.97 0.86 0.92 44
# 6 0.97 0.71 0.82 55
# 7 0.93 0.91 0.92 46
# 8 0.91 0.83 0.87 47
# 9 0.98 0.90 0.94 61
# avg / total 0.97 0.87 0.92 450
#混淆矩阵
print(confusion_matrix(predictions,y_test))
# [[43 0 0 0 6 0 0 0 0 0]
# [ 0 49 0 0 9 1 0 0 1 0]
# [ 0 0 45 0 0 0 0 0 0 0]
# [ 0 0 0 42 0 0 0 1 0 0]
# [ 0 0 0 0 0 0 0 0 0 0]
# [ 0 0 0 0 5 38 0 0 1 0]
# [ 0 0 0 0 15 0 39 0 1 0]
# [ 0 0 0 0 4 0 0 42 0 0]
# [ 0 0 0 1 4 0 1 1 39 1]
# [ 0 0 0 2 2 0 0 1 1 55]]
三、sklearn识别手写数字的应用
使用BP神经网络计算时,需要从数学的角度自己去构建相关的公式,最后得到计算结果。而使用sklearn是一个强大的机器学习库,我们可以使用自身带的一些功能来进行多层感知器分类。如下:
from sklearn.neural_network import MLPClassifier
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
import matplotlib.pyplot as plt
digits = load_digits()
x_data = digits.data
y_data = digits.target
print(x_data.shape)
print(y_data.shape)
# (1797, 64)
# (1797,)
#数据拆分
x_train,x_test,y_train,y_test = train_test_split(x_data,y_data)
#构建模型,2个隐藏层,第一个隐藏层有100个神经元,第2隐藏层50个神经元,训练500周期
mlp = MLPClassifier(hidden_layer_sizes=(100,50), max_iter=500)
mlp.fit(x_train,y_train)
#测试集准确率的评估
predictions = mlp.predict(x_test)
print(classification_report(y_test, predictions))
# precision recall f1-score support
# 0 1.00 1.00 1.00 51
# 1 1.00 1.00 1.00 53
# 2 0.97 0.95 0.96 40
# 3 0.95 0.97 0.96 37
# 4 1.00 1.00 1.00 44
# 5 0.91 0.96 0.93 45
# 6 0.98 0.98 0.98 45
# 7 1.00 0.95 0.98 43
# 8 0.96 1.00 0.98 44
# 9 1.00 0.96 0.98 48
# avg / total 0.98 0.98 0.98 450
如上所示,使用sklearn库构建BP神经网络,只需构建多层感知器分类器MLPClassifier,输入神经网络隐藏层的神经单元个数,并通过fit()方法进行训练,训练完成后通过predict()方法进行预测即可。对识别手写数字来说,测试结果准确率较高,能达到98%。
【参考】:
1. 城市数据团课程《AI工程师》计算机视觉方向
2. deeplearning.ai 吴恩达《深度学习工程师》
3. 《机器学习》作者:周志华
转载声明:
版权声明:非商用自由转载-保持署名-注明出处
署名 :mcyJacky
文章出处:https://blog.csdn.net/mcyJacky
