第16节课 Three Learning Principles
- 本节课主要学习了机器学习中非常实用的三个“锦囊妙计”:奥卡姆剃刀定律、抽样偏差、避免“偷窥数据”。本节课多为概念性的知识,比较好懂。最后一小节对16节课学过的知识进行了回顾,个人认为很重要,这一块内容抄了一遍在本子上,加深记忆,更好的回顾学过的东西!
(一)奥卡姆剃刀定律
1.定义:奥卡姆剃刀定律(Occam’s Razor) 这个原理称为“如无必要,勿增实体”,就像剃刀一样,将不必要的部分去除掉。

2.奥卡姆剃刀定律反映到机器学习领域中,指的是在所有可能选择的模型中,我们应该选择能够很好地解释已知数据并且十分简单的模型。
例如下面的两幅图:

虽然上面两幅图都正确分类,但左边的模型简单,右边的模型复杂。我们会选择左边的模型。
3.简单的模型一方面指的是简单的hypothesis h
simple hypothesis h和simple model H是紧密联系的。为了让模型简单化,我们可以一开始就选择简单的model,或者用regularization,让hypothesis中参数个数减少,都能降低模型复杂度。
4.为什么选择简单的模型好?
机器学习的目的是“找规律”,即分析数据的特征,总结出规律性的东西出来。

如果使用某种简单的模型就可以将数据分开,那表明数据本身应该符合某种规律性。相反地,如果用很复杂的模型将数据分开,并不能保证数据本身有规律性存在,也有可能是杂乱的数据,因为无论是有规律数据还是杂乱数据,复杂模型都能分开。这就不是机器学习模型解决的内容了。所以,模型选择中,我们应该尽量先选择简单模型,例如最简单的线性模型。
(二)抽样偏差
1.引例:

2.这个例子表明,抽样的样本会影响到结果。意思是,如果抽样有偏差的话,那么学习的结果也产生了偏差,这种情形称之为抽样偏差Sampling Bias。

从技术上来说,就是训练数据和验证数据要服从同一个分布,最好都是独立同分布的,这样训练得到的模型才能更好地具有代表性。
(三)避免“偷窥数据”
1.之前的课程学习了在模型选择时应该尽量避免偷窥数据,因为这样会使我们人为地倾向于某种模型,而不是根据数据进行随机选择。所以,Φ应该自由选取,最好不要偷窥到原始数据,这会影响我们的判断。
因为事实上,数据偷窥发生的情况有很多,会引入数据的污染。

2.引例:
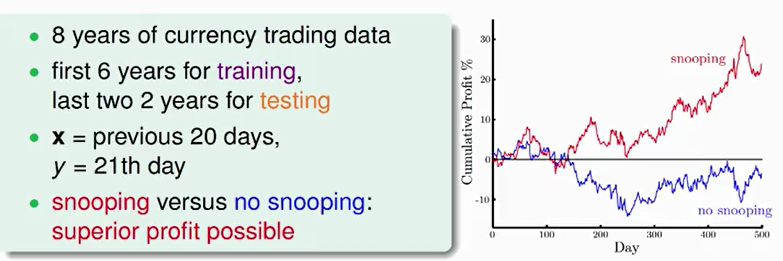


3.在机器学习过程中,避免“偷窥数据”非常重要,但实际上,完全避免也很困难。
实际操作中,有一些方法可以帮助我们尽量避免偷窥数据。
①第一个方法是“看不见”数据。先选模型,再看数据。
②第二个方法是保持怀疑。要通过自己的研究与测试来进行模型选择,这样才能得到比较正确的结论。
