HDFS工具
HDFS distcp并行复制
- 前面的HDFS访问模型多事单线程的访问。
- Hadoop有一个叫idstcp(分布式复制)的有用程序,能从Hadoop的文件系统并行复制大量数据.
- distcp一般用于在两个运行同一版本DFS集群中传输数据.
bin/hadoop distcp hdfs;//namenode1/foo
hdfs://namenode2/bar
这将从第一个集群中复制/foo目录(和它的内容)到第二个集群中的/bar目录下.
- distcp是作为一个MapReduce作业执行的,每个文件都由一个单一的map进行复制,并且distcp通过将文件分成大致相等的文件来为每个map数量大致相同的数据.
- 如果想在两个运行着不同版本HDFS的集群上利用distcp,使用hdfs协议是会失败的,因为RPC系统是不兼容的.
- 可以使用基于Http的HFTP协议弥补:
bin/hadoop distcp hftp://namenode1:50070/foo
hdfs://namenode2/bar
Hadoop复制
- Apache Flume
—将大规模流数据导入HDFS的工具,是一个海量日志采集、聚合和传输的系统.
—支持多种数据源收集 - Apache Sqoop
—用于HDSF的传统的关系型数据库之间的数据传递 - DataX
—Datax是一异构数据源离线同步工具
HDFS压缩
Hadoop可以创建自己的归档文件,即har文件
(hadoop archive file)
bin/hadoop archive -archiveName XXX.har -p <parentpath> <src>* <dest>
XXX.har //归档文件名
<src> //源路径
<dest> //输出路径
.har文件是hadoop中压缩文件的缩写.
har文件的优点:
har文件支持hadoop在HDFS云端的文件的压缩和打包.并且这个格式的文件能够在不打开,不解压的情况读取里面的部分的数据.
所以,har文件是HDFS专用的文件归档的格式方法.
启动上面的命令其实是启动了Mapreduce的程序帮我们把文件打包成har的格式.
列子,查看云端的文件:
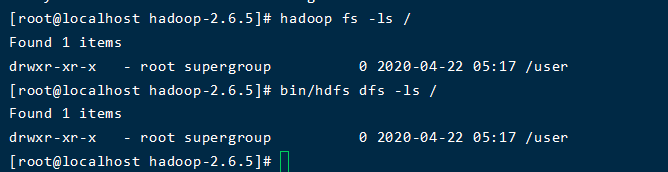
命令1:
bin/hdfs dfs -ls /
命令2:
hadoop fs -ls /
刚开始的时候,由于我没有指定路径,导致没查到,因为我的文件都在根目录下.
错误运行结果:

正常运行结果:
然后通过下面的命令对文件test_6_3_1进行打包,打包成data.har,放入文件夹test_6_3_1_1中.
运行效果图:


这里有一个坑:就是我们在指定目标文件夹的时候需要指定全路径,前面的那个父目录只是源文件路径的,不包括目标文件夹,这样就可以看到了.
总结:
不通过HDFS的工具,我们每次都是通过流的形式进行读和写操作的,但是如果我们使用HDFS的工具的话,我们就可能可以并行的进行文件的传输等等操作.然后的话archive命令的文件夹的目录需要指定全路径.
