介绍ES为什么介绍这些?理下关系,ES是一种分布式全文检索系统,用来做分布式系统上的信息检索。它是一个集群,底层单机版用的是Lucence,Lucene是一种全文检索工具。
一、什么是全文检索?
数据一般分为两种:结构化数据(有固定格式或有限长度的数据,如数据库、元数据)和非结构化数据(长度和格式不定的数据,如word文档)。数据存起来就是为了以后检索的,在对非结构化数据内容进行检索,一般有两种方式,顺序扫描和全文检索。顺序扫描就是把全部文档的全部文档从头到尾搜索一遍来和查询关键字对比。全文索引是把非结构化数据的一部分信息提取出来,重新组织成有一定结构的数据,从原非结构化数据提取出来然后重新组织的细腻,称为索引,再搜索的时候根据结构化的索引取查找数据位置,进一步找到数据全文。这种先建立所以,再对索引进行搜索的过程叫全文检索。
总结下,全文检索是一种针对非结构化数据的检索方式,它会先把非结构化数据重排建立索引,再对索引进行检索。
Hats off to the shres:https://blog.csdn.net/u013115157/article/details/53607622
二、Lucene
lucence是一种单机版的全文检索开源框架
2-1 倒排索引
一般我们在索引的时候都是根据记录来确定属性值(用key找value),而倒排索引则是通过属性值来确定记录(用value来找值)。举个例子对比正排索引和倒排索引:
对一系列文档建立正排索引:
文档1:word1出现次数、word1所在位置;word2出现次数、word2所在位置……
文档2:word1出现次数、word1位置;word3出现次数,位置;……
……
在其中检索关键字“大数据”,则需要扫描全部文档,找出关键字,再通过模型打分,根据打分排名呈现搜索结果。
对这一系列文档建立倒排索引,将正向索引重新构建为倒排索引,建立关键字到文档的映射,每个关键词映射到包含这个词的文档:
word1:文档1的位置、文档2的位置……
word2:……
……
在其中检索关键字“大数据”,只需要扫描索引就能查找到该关键字所处位置。
Lucence快的原因,添加数据时,对数据进行分词,将分词后的词建立索引,存储到索引库中,然后再将真正的内容即文档,也保存起来,存储在文档区域。
查找时,将查询条件分词,先在索引库中查找,如果查找成功,返回文档ID,然后根据文档ID再到文档存储区域查找具体内容。
Hats off to the sharers:http://www.cnblogs.com/zlslch/p/6440114.html
2-2 Lucene的索引过程
Hats off to the sharers!
作者:Regan_Hoo
来源:CSDN
原文:https://blog.csdn.net/regan_hoo/article/details/78802897
版权声明:本文为博主原创文章,转载请附上博文链接!
---------------------
作者:程序员杂谈
来源:CSDN
原文:https://blog.csdn.net/trecn001/article/details/86529253
https://blog.csdn.net/regan_hoo/article/details/78802897#commentBox
①获取内容
②建立文档
获取原始内容后,就需要对这些内容进行索引(倒排索引),必须首先将这些内容转换成部件(通常称为文档),以供搜索引擎使用。文档主要包括几个带值的域,比如标题、正文、摘要、作者和链接。
③文档分析
搜索引擎不能直接对文本进行索引:确切地说,必须将文本分割成一系列被称为语汇单元的独立的原子元素。每一个语汇单元大致与语言中的“单词”对应起来。
④文档索引
在索引步骤中,文档被加入到索引列表。
2-3 Lucence搜索处理
搜索处理过程就是从索引中查找单词,从而找到包含该单词的文档。搜索质量主要由查准率和查全率来衡量。查全率用来衡量搜索系统查找相关文档的能力;而查准率用来衡量搜索系统过滤非相关文档的能力。
①用户搜索界面
Lucene不提供默认的用户搜索界面,需要自己开发。
②建立查询
用户从搜索界面提交一个搜索请求,通常以HTML表单或者Ajax请求的形式由浏览器提交到你的搜索引擎服务器。然后将这个请求转换成搜索引擎使用的查询对象格式,这称为建立查询。
③搜索查询
查询检索索引并返回与查询语句匹配的文档,结果返回时按照查询请求来排序。
④展现结果
一旦获得匹配查询语句并排好序的文档结果集,接下来就得用直观的、经济的方式为用户展现结果。
2-4 索引过程的核心类
先看文档和域的概念:
文档是Lucene索引和搜索的原子单位。文档为包含一个或多个域的容器,而域则依次包含“真正的”被搜索内容。每个域都有一个标识名称,该名称为一个文本值或二进制值。如:用户在输入搜索内容“title:lucene”时,搜索结果则为标题域值包含单词“lucene”的所有文档。
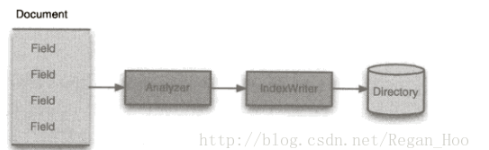
·IndexWriter
·Directory
·Analyzer
·Document
·Field
①IndexWriter
索引过程的核心组件。这个类负责创建新索引或者打开已有索引,以及向索引中添加、删除或更新被索引文档的信息。可以把IndexWriter看作这样一个对象:它为你提供针对索引文件的写入操作,但不能用于读取或搜索索引。IndexWriter需要开辟一定空间来存储索引,该功能可以由Directory完成。
②Directory
该类描述了Lucene索引的存放位置。它是一个抽象类,它的子类负责具体指定索引的存储路径。用FSDirectory.open方法来获取真实文件在文件系统的存储路径,然后将它们一次传递给IndexWriter类构造方法。IndexWriter不能直接索引文本,这需要先由Analyzer将文本分割成独立的单词才行(即进行分词)。
③Analyzer
文本文件在被索引之前,需要经过Analyzer(分析器)处理。Analyzer是由IndexWriter的构造方法来指定的,它负责从被索引文本文件中提取语汇单元,并提出剩下的无用信息。如果被索引内容不是纯文本文件,那就需要先将其转换为文本文档。对于要将Lucene集成到应用程序的开发人员来说,选择什么样Analyzer是程序设计中非常关键的一步。分析器的分析对象为文档,该文档包含一些分离的能被索引的域。
④Document
Document对象代表一些域(Field)的集合。文档的域代表文档或者文档相关的一些元数据。元数据(如作者、标题、主题和修改日期等)都作为文档的不同域单独存储并被索引。Document对象的结构比较简单,为一个包含多个Filed对象容器;Field是指包含能被索引的文本内容的类。
⑤Field
索引中的每个文档都包含一个或多个不同命名的域,这些域包含在Field类中。每个域都有一个域名和对应的域值,以及一组选项来精确控制Lucene索引操作各个域值。
2-5 搜索过程中的核心类
对于索引的查询,首先构建查询的Query,通过IndexSearcher进行查询,得到命中的TopDocs。然后通过TopDocs的scoreDocs()方法,拿到ScoreDoc,通过ScoreDoc,得到对应的文档编号,IndexSearcher通过文档编号,使用IndexReader对制定目录下的索引内容进行读取,得到命中的文档后返回。
·IndexSearcher
·Term
·Query
·TermQuery
·TopDocs
①IndexSearcher
该类用于搜索由IndexWriter类创建的索引,它是连接索引的中心环节。可以将IndexSearcher类看作是一个以只读方式打开索引的类。它需要利用Directory实例来掌控前期创建的索引,然后才能提供大量的搜索方法。
②Term
Term对象是搜索功能的基本单元。Term对象包含一对字符串元素:域名和单词(或域名文本值)。
③Query
包含了一些非常有用的方法,TermQuery是它的一个子类。
④TermQuery
该类提供最基本的查询,用来匹配指定域中包含特定项的文档。
⑤TopDocs
该类是一个简单的指针容器,指针一般指向前N个排名的搜索结果,搜索结果即匹配查询条件的文档。
三、Lucence支持的查询
作者:chen长记
来源:CSDN
原文:https://blog.csdn.net/u012477338/article/details/80513044
版权声明:本文为博主原创文章,转载请附上博文链接!
----------------------------------------------------------------------------------------
词项查询 TermQuery
短语查询 PhraseQuery
布尔查询 BooleanQuery
正则查询 RegexpQuery
模糊查询 FuzzyQuery
前缀查询 PrefixQuery
通配符查询 WildcardQuery
范围查询 TermRangeQuery