ES—倒排索引
【前言】
Elasticsearch 是通过 Lucene 的倒排索引技术实现比关系型数据库更快的过滤。特别是它对多条件的过滤支持非常好,比如年龄在 18 和 30 之间,性别为女性这样的组合查询。倒排索引很多地方都有介绍,但是其比关系型数据库的 b-tree 索引快在哪里?到底为什么快呢?
笼统的来说,b-tree 索引是为写入优化的索引结构。当我们不需要支持快速的更新的时候,可以用预先排序等方式换取更小的存储空间,更快的检索速度等好处,其代价就是更新慢。要进一步深入的化,还是要看一下 Lucene 的倒排索引是怎么构成的。
【正文】
ES中的索引在这里就不多讲了,相当于传统数据库的表一样
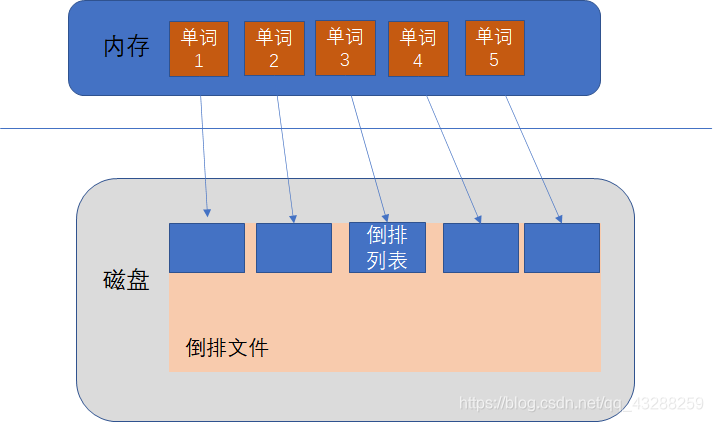
倒排索引(Inverted Index):每个文档都对应一个ID,倒排索引会按照指定语法对每一个文档进行分词,然后维护一张表,列举所有文档中出现的terms以及它们出现的文档ID和出现频率,它是实现"单词-文档矩阵"的一种具体存储形式。倒排索引主要由两部分组成:“单词词典"+"倒排文件”。
简单的来讲:正序索引是根据key找value,而倒序索引是根据value找key。
二者区别的示意图
正序索引

倒序索引

单词词典(Lexicon):单词词典是由文档集合中出现过的所有单词构成的字符串集合,单词词典内每条索引项记载单词本身的一些信息以及指向"倒排列表"的指针。
倒排列表(PostingList):倒排列表记载了出现过某个单词的所有文档的文档列表及单词在该文档中出现的位置信息,每条记录称为一个倒排项。
倒排文件(Inverted File):所有单词的倒排列表往往顺序地存储在磁盘的某个文件里,这个文件被称之为倒排文件,倒排文件是存储倒排索引的物理文件。