什么是ES?
ES是Elasticsearch的简称,Elasticsearch是一个分布式可扩展的实时搜索和分析引擎,一个建立在全文搜索引擎 Apache Lucene™ 基础上的搜索引擎。Lucene只是一个框架,要充分利用它的功能,需要使用JAVA,并且在程序中集成Lucene,学习成本高,且Lucene确实非常复杂。
特点:
- 分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索
- 实时分析的分布式搜索引擎
- 可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据
ES的核心概念
- 索引(Index)
ES将数据存储于一个或多个索引中。类比传统的关系型数据库领域来说,索引相当于SQL中的一个数据库,或者一个数据存储方案(schema)。索引由其名称(必须为全小写字符)进行标识。一个ES集群中可以按需创建任意数目的索引。 - 类型(Type)
类型是索引内部的逻辑分区(category/partition),一个索引内部可定义一个或多个类型(type)。类比传统的关系型数据库领域来说,类型相当于“表”。 - 文档(Document)
文档是索引和搜索的原子单位,它是包含了一个或多个域(Field)的容器,每个域拥有一个名字及一个或多个值,有多个值的域通常称为“多值域”,文档基于JSON格式进行表示。每个文档可以存储不同的域集,但同一类型下的文档至应该有某种程度上的相似之处。 - 集群(Cluster)
一个或者多个拥有相同cluster.name配置的节点组成, 它们共同承担数据和负载的压力。 - 节点(Node)
一个运行中的 Elasticsearch 实例称为一个节点。
ES集群中的节点有三种不同的类型:
主节点:负责管理集群范围内的所有变更,例如增加、删除索引,或者增加、删除节点等。 主节点并不需要涉及到文档级别的变更和搜索等操作。可以通过属性node.master进行设置。
数据节点:存储数据和其对应的倒排索引。默认每一个节点都是数据节点(包括主节点),可以通过node.data属性进行设置。
协调节点:如果node.master和node.data属性均为false,则此节点称为协调节点,用来响应客户请求,均衡每个节点的负载。
ES倒排索引
什么是倒排索引: 倒排索引也叫反向索引,通俗来讲正向索引是通过key找value,反向索引则是通过value找key。
假设有3条文档数据:

那么Elasticsearch建立的索引如下:
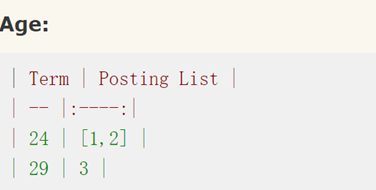
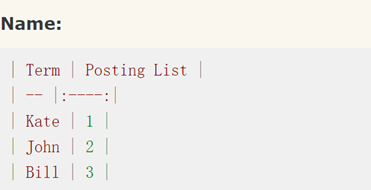

Elasticsearch分别为每个field都建立了一个倒排索引,24,Kate, John Female这些叫term,而[1,2]就是Posting List倒排列表。Posting list就是一个int的数组,倒排列表记录了出现过某个单词的所有文档的文档列表及单词在该文档中出现的位置信息,每条记录称为一个倒排项(Posting)。根据倒排列表,即可获知哪些文档包含某个单词。
思考:如果这里有上千万的记录呢?如何通过term来查找呢?这就需要了解一下Term Dictionary和Term Index的概念
Term Dictionary:
Elasticsearch为了能快速找到某个term,将所有的term排个序,二分法查找term,logN的查找效率,就像通过字典查找一样,这就是Term Dictionary。现在再看起来,似乎和传统数据库通过B-Tree的方式类似,为什么说比B-Tree的查询快呢?
Term Index:
B-Tree通过减少磁盘寻道次数来提高查询性能,Elasticsearch也是采用同样的思路,直接通过内存查找term,不读磁盘,但是如果term太多,term dictionary也会很大,放内存不现实,于是有了Term Index,就像字典里的索引页一样,A开头的有哪些term,分别在哪页,可以理解term index是一颗树
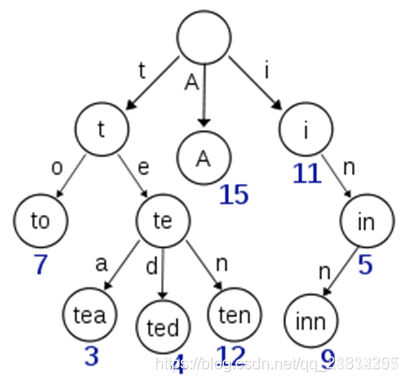
这棵树不会包含所有的term,它包含的是term的一些前缀。通过term index可以快速地定位到term dictionary的某个offset,然后从这个位置再往后顺序查找
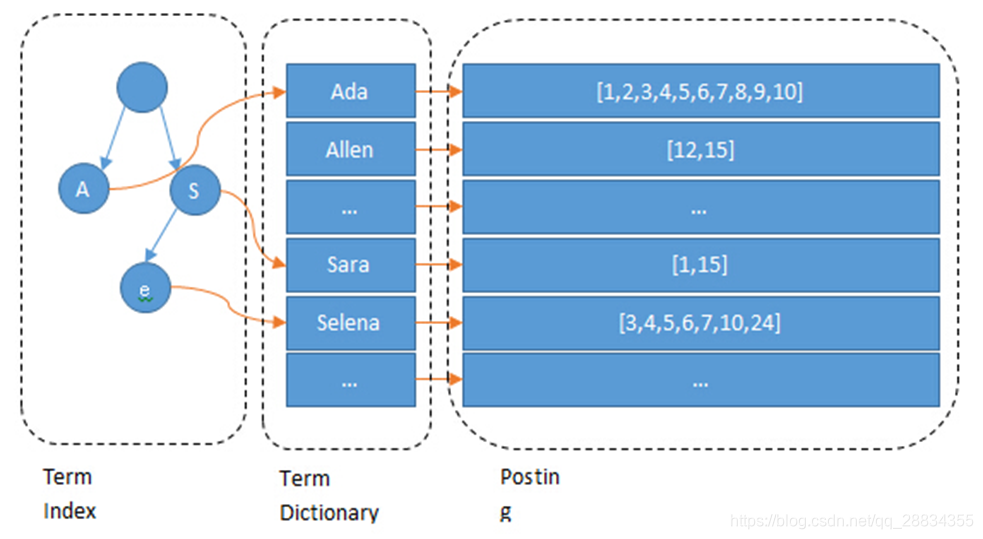
所以term index不需要存下所有的term,而仅仅是他们的一些前缀与Term Dictionary的block之间的映射关系,再结合FST(Finite State Transducers)的压缩技术,可以使term index缓存到内存中。从term index查到对应的term dictionary的block位置之后,再去磁盘上找term,大大减少了磁盘随机读的次数。