正排索引
正排表是以文档的ID为关键字,表中记录文档中每个字的位置信息,查找时扫描表中每个文档中字的信息直到找出所有包含查询关键字的文档。
正排表结构如图1所示,这种组织方法在建立索引的时候结构比较简单,建立比较方便且易于维护;因为索引是基于文档建立的,若是有新的文档加入,直接为该文档建立一个新的索引块,挂接在原来索引文件的后面。若是有文档删除,则直接找到该文档号文档对应的索引信息,将其直接删除。但是在查询的时候需对所有的文档进行扫描以确保没有遗漏,这样就使得检索时间大大延长,检索效率低下。
尽管正排表的工作原理非常的简单,但是由于其检索效率太低,除非在特定情况下,否则实用性价值不大。

倒排索引(反向索引)
倒排表以字或词为关键字进行索引,表中关键字所对应的记录表项记录了出现这个字或词的所有文档,一个表项就是一个字表段,它记录该文档的ID和字符在该文档中出现的位置情况。
由于每个字或词对应的文档数量在动态变化,所以倒排表的建立和维护都较为复杂,但是在查询的时候由于可以一次得到查询关键字所对应的所有文档,所以效率高于正排表。在全文检索中,检索的快速响应是一个最为关键的性能,而索引建立由于在后台进行,尽管效率相对低一些,但不会影响整个搜索引擎的效率。
倒排表的结构图如图2:
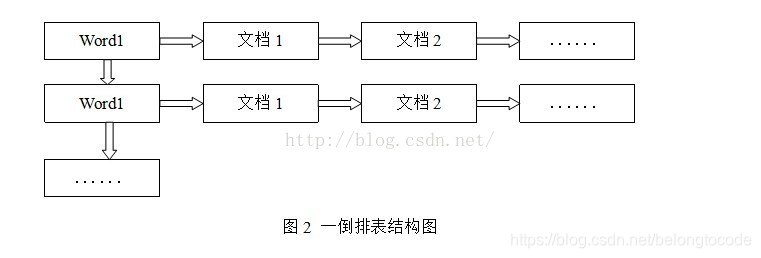
正排索引是从文档到关键字的映射(已知文档求关键字),倒排索引是从关键字到文档的映射(已知关键字求文档)。
实际运用
搜索引擎通常检索的场景是: 给定几个关键词,找出包含关键词的文档。
怎么快速找到包含某个关键词的文档就成为搜索的关键。这里我们借助单词——文档矩阵模型,
通过这个模型我们可以很方便知道某篇文档包含哪些关键词,某个关键词被哪些文档所包含。
单词-文档矩阵的具体数据结构可以是倒排索引、签名文件、后缀树等。
倒排索引源于实际应用中需要根据属性的值来查找记录,lucene是基于倒排索引实现的。
这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。
由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)。
带有倒排索引的文件我们称为倒排索引文件,简称倒排文件(inverted file)。
倒排索引一般表示为一个关键词,然后是它的频度(出现的次数),位置(出现在哪一篇文章或网页中,及有关的日期,作者等信息),它相当于为互联网上几千亿页网页做了一个索引,好比一本书的目录、标签一般。读者想看哪一个主题相关的章节,直接根据目录即可找到相关的页面。不必再从书的第一页到最后一页,一页一页的查找。
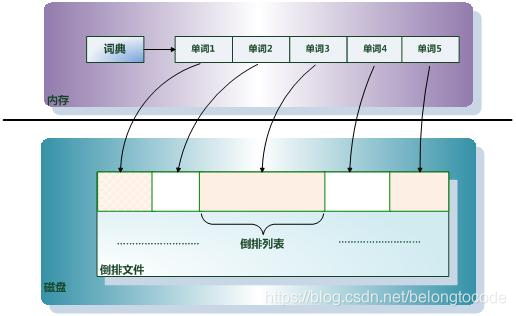
倒排索引由两个部分组成:单词词典和倒排文件。
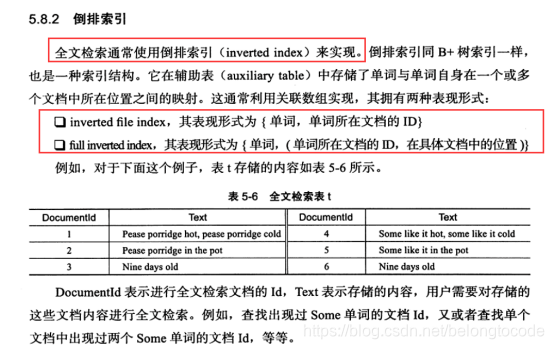
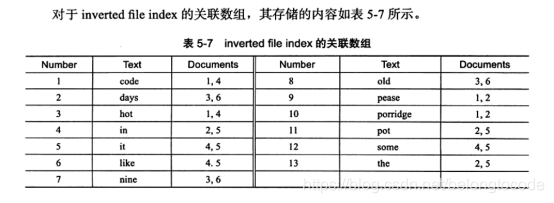
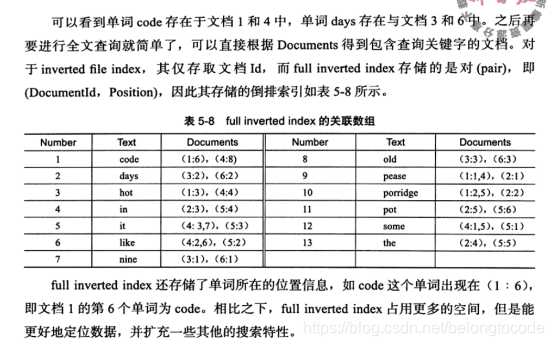
实例理解:
参考:
https://blog.csdn.net/zhangzeyuaaa/article/details/48676775
https://blog.csdn.net/weixin_33737774/article/details/85735880
