在提交spark作业的时候,spark出现报错
./spark-shell
19/05/14 05:37:40 WARN util.NativeCodeLoader: Unable to load native-hadoop
library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
19/05/14 05:37:49 ERROR spark.SparkContext: Error initializing SparkContext.
org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.ipc.StandbyException):
Operation category READ is not supported in state standby. Visit https://s.apache.org/sbnn-error
at org.apache.hadoop.hdfs.server.namenode.ha.StandbyState.checkOperation(StandbyState.java:88)
at org.apache.hadoop.hdfs.server.namenode.NameNode$NameNodeHAContext.checkOperation(NameNode.java:1826)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkOperation(FSNamesystem.java:1404)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getFileInfo(FSNamesystem.java:4208)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.getFileInfo(NameNodeRpcServer.java:895)
at org.apache.hadoop.hdfs.server.namenode.AuthorizationProviderProxyClientProtocol.getFileInfo(AuthorizationProviderProxyClientProtocol.java:527)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.getFileInfo(ClientNamenodeProtocolServerSideTranslatorPB.java:824)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:617)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:1073)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2086)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2082)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1693)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2080)
原因分析
今天我将spark的history-server打开了,测试的时候用的好好的,但是一会发现启动不了spark作业提交不了。
通过分析日志并查看HDFS的Web界面,发现应该是我的spark连接不到HDFS的ActiveNN,而spark启动就需要连接HDFS的服务只有写入job日志这一项,所以我查看了指定sparkJob日志写入路径的spark-defaults.conf文件,果然路径指定的是standByNN
spark.eventLog.dir hdfs://hadoop002:8020/g6_direcory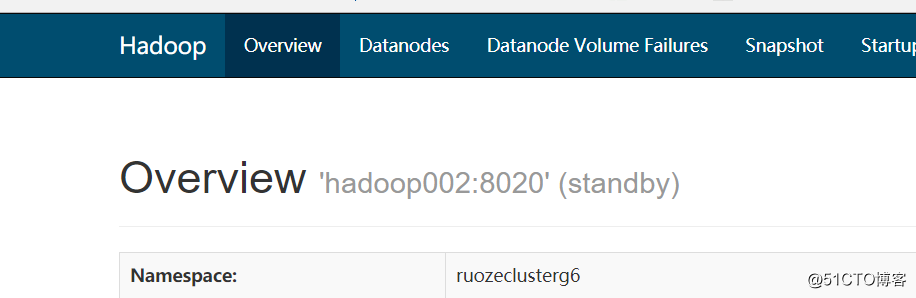
所以spark不能通过连接standByNN将日志写入HDFS
解决
将spark-defaults.conf和spark-env.sh 里面日志目录文件路径从单一NN改为命名空间的路径就好
我的命名空间是
<property>
<name>fs.defaultFS</name>
<value>hdfs://ruozeclusterg6</value>
</property>修改spark-defaults.conf
spark.eventLog.enabled true
spark.eventLog.dir hdfs://ruozeclusterg6:8020/g6_direcory修改spark-env.sh
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://ruozeclusterg6:8020/g6_direcory"测试
[hadoop@hadoop002 spark]$ spark-shell
19/05/14 06:00:04 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://hadoop002:4040
Spark context available as 'sc' (master = local[*], app id = local-1557828013138).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.2
/_/
Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_131)
Type in expressions to have them evaluated.
Type :help for more information.
scala>