版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/baiziyuandyufei/article/details/82721624
怎么将二分类模型应用到多分类问题
二分类模型数量众多,但实际应用中往往待预测类别数量不只有2个,于是有了一些将二分类模型应用到多分类的方法。
- 常见二分类模型
- One-vs-Rest
- One-vs-One
- Directed Acyclic Graph Method
常见二分类模型
- 逻辑回归
- 单层感知机
- 支持向量机
One-vs-Rest
如果有k个类别要预测,训练阶段就训练k个二分类模型。比如,针对第i个类的训练,将第i类样本取出作为类别1的训练数据,将其余类样本取出作为类别-1的训练数据,之后就训练这个模型。预测阶段输入一个预测实例,用这k个模型分别预测,得到k个预测值,将预测值最大的那个模型所对应的类别标记作为预测结果。

这个方法的缺陷是会使本来样本均衡的训练集变得不均衡。比如对于一个有k个类的多分类问题,正样本集和负样本集的样本数之比在原始训练集均匀的情况下将会是1/(k−1) 。针对该缺陷,一种比较常见的做法是只抽取负样本集中的一部分来进行训练(比如抽取其中的三分之一)。
One-vs-One
与One-vs-Rest不同,这里将训练k(k-1)/2个二分类模型。也就是说训练阶段无序从k个类别中抽取2个类别训练一个分类器。预测阶段,输入一个样本实例,统计k(k-1)/2个分类器的预测类别,结果中出现次数最多的类别,就是最终的预测结果。

这个模型的缺陷是由于模型的量级是k^2,所以它的时间开销会相当大。
Directed Acyclic Graph Method
它的训练阶段和OvO的训练阶段完全一致,区别只在于最后的预测阶段。
构建一个下图所示的分类器图:
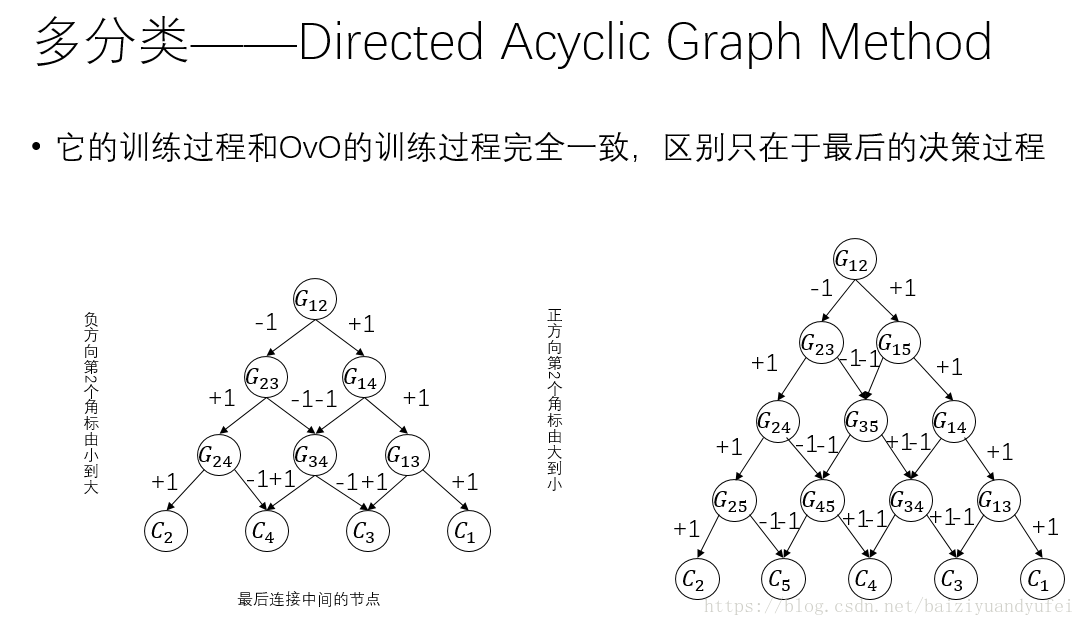
输入一个预测实例,首先将它送入根节点G12分类器,按照预测结果,将它送入后续分类器节点,树枝上的权重-1表示预测结果为Gij中的j类别,+1表示预测结果为Gij中的i类别。最后以叶节点所表示的类别作为预测结果。