概述
Nginx访问日志形式: $remote_addr – $remote_user [$time_local] “$request”$status $body_bytes_sent“$http_referer” ”$http_user_agent”
例如:192.168.241.1 - - [02/Mar/2017:15:22:57 +0800] “GET /favicon.ico HTTP/1.1” 404 209 “http://192.168.241.10/” “Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36”
考虑到Nginx服务器可能有多个,所以采用二级Agent来收集日志
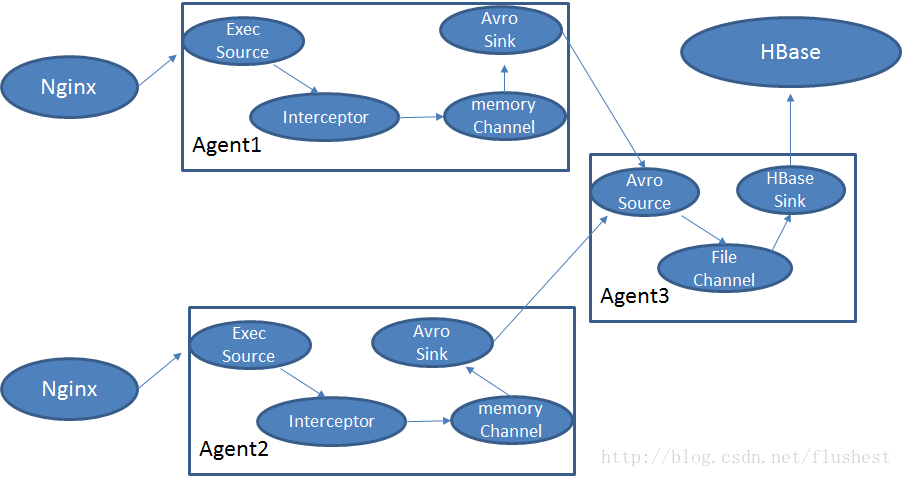
其中Interceptor是自定义拦截器,将利用正则表达式配置过滤掉无用记录,将文本记录转换为map对象。
HBaseSink是自定义HBaseSink,可以将map对象存储到HBase中,可配置时间字段作为行键前缀,可按时间升序排列。
自定义过滤器
package com.mine.flume.interceptors;
import org.apache.commons.io.output.ByteArrayOutputStream;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import org.apache.log4j.Logger;
import java.io.IOException;
import java.io.ObjectOutputStream;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class LogFormatInterceptor implements Interceptor{
private static Logger logger = Logger.getLogger(LogFormatInterceptor.class);
private Pattern regex; //正则匹配式
private String[] keys; //匹配内容所对应keys
public LogFormatInterceptor(Pattern regex,String[] keys) {
this.regex = regex;
this.keys = keys;
}
public void initialize() {
}
public Event intercept(Event event) {
byte[] body = event.getBody();
String record = new String(body);
Matcher matcher = regex.matcher(record);
if(matcher.find()) {
int groupCount = matcher.groupCount();
if(groupCount!=keys.length) {
logger.error("regex匹配的group数与keys长度不相等");
event = null;
}else {
//构造Map
Map<String,String> map = Util.matcherToMap(matcher,keys);
//将Map转换成byte数组存放到body中
byte[] bytes = Util.mapToByteArray(map);
//替换Event内容
event.setBody(bytes);
try {
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bos);
} catch (IOException e) {
e.printStackTrace();
}
}
}else {
event = null;
}
return event;
}
public List<Event> intercept(List<Event> list) {
List<Event> events = new ArrayList<Event>();
for(Event event: list) {
Event nEvent = intercept(event);
if(nEvent!=null) {//该事件有效
events.add(nEvent);
}
}
return events;
}
public void close() {
}
public static class Builder implements Interceptor.Builder {
private Pattern regex; //正则匹配式
private String[] keys; //匹配内容所对应keys
public Builder() {
}
public Interceptor build() {
return new LogFormatInterceptor(regex,keys);
}
public void configure(Context context) {
String regexString = context.getString("regex",".*");
regex = Pattern.compile(regexString);
String keyString = context.getString("keys");
keys = keyString.split(",");
}
}
}
Interceptor过滤器工作方式:Channel Processor会根据Class.newInstance()方法创建一个Build实例,将配置文件生成的Context传递给Build.configure方法从中获取Interceptor所需要的配置项,这里是regex和keys。而后调用Build.build()返回一个Interceptor对象。调用Interceptor.intercept(List)处理事件列表
flume配置
agent.sources = execSrc
agent.channels = memoryChannel
agent.sinks = avroSink
# 利用exec方式实时追踪日志
agent.sources.execSrc.type = exec
agent.sources.execSrc.command = tail -F /etc/nginx/log/access.log
agent.sources.execSrc.channels = memoryChannel
agent.sources.execSrc.interceptors = logformat
agent.sources.execSrc.interceptors.logformat.type = com.mine.flume.interceptors.LogFormatInterceptor$Builder
agent.sources.execSrc.interceptors.logformat.regex = (\\d+\\.\\d+\\.\\d+\\.\\d+) - ([^ ]*) \\[(.*)\\] \"(.*)\" ([^ ]*) ([^ ]*) \"([^\"]*)\" \"([^\"]*)\"
agent.sources.execSrc.interceptors.logformat.keys = remote_addr,remote_user,time_local,request,status,body_bytes_sent,http_referer,http_user_agent
agent.sinks.avroSink.type = avro
agent.sinks.avroSink.hostname = 192.168.241.10
agent.sinks.avroSink.port = 1111
agent.sinks.avroSink.channel = memoryChannel
agent.channels.memoryChannel.type = memory自定义HBaseSink
public class MapBodyHbaseSink implements HbaseEventSerializer {
private static Logger logger = Logger.getLogger(MapBodyHbaseSink.class);
private String rowPrefix;
private byte[] incrementRow;
private byte[] cf;
private Map<String,String> body;
private byte[] incCol;
private KeyType keyType;
public void configure(Context context) {
rowPrefix = context.getString("rowPrefix", "default");
incrementRow = context.getString("incrementRow", "incRow").getBytes(Charsets.UTF_8);
String suffix = context.getString("suffix", "uuid");
String incColumn = context.getString("incrementColumn", "iCol");
if (suffix.equals("timestamp")) {
keyType = KeyType.TS;
} else if (suffix.equals("random")) {
keyType = KeyType.RANDOM;
} else if (suffix.equals("nano")) {
keyType = KeyType.TSNANO;
} else if(suffix.equals("timePrefix")){
//自定义主键类型,以某个时间字段为前缀,rowPrefix指定时间段域名
keyType = KeyType.TIMEPREFIX;
} else {
keyType = KeyType.UUID;
}
if (incColumn != null && !incColumn.isEmpty()) {
incCol = incColumn.getBytes(Charsets.UTF_8);
}
}
public void configure(ComponentConfiguration conf) {
}
public void initialize(Event event, byte[] cf) {
this.body = Util.byteArrayToMap(event.getBody());
this.cf = cf;
}
public List<Row> getActions() throws FlumeException {
List<Row> actions = new LinkedList<Row>();
if (body != null&&!body.isEmpty()) {
byte[] rowKey;
try {
if (keyType == KeyType.TS) {
rowKey = SimpleRowKeyGenerator.getTimestampKey(rowPrefix);
} else if (keyType == KeyType.RANDOM) {
rowKey = SimpleRowKeyGenerator.getRandomKey(rowPrefix);
} else if (keyType == KeyType.TSNANO) {
rowKey = SimpleRowKeyGenerator.getNanoTimestampKey(rowPrefix);
} else {
if(keyType == KeyType.TIMEPREFIX) {
String dateString = body.get(rowPrefix);
if(dateString==null) return actions;
Date access_time = Util.parseDate(dateString);
if(access_time==null) {//解析访问时间失败
logger.error("解析时间失败:"+body.get(rowPrefix));
return actions;
}else {
body.put(rowPrefix,Util.formatDate(access_time));
rowPrefix = access_time.getTime()+"";
}
}
rowKey = SimpleRowKeyGenerator.getUUIDKey(rowPrefix);
}
for(String col : body.keySet()) {
Put put = new Put(rowKey);
put.add(cf, col.getBytes(), body.get(col).getBytes());
actions.add(put);
}
} catch (Exception e) {
throw new FlumeException("Could not get row key!", e);
}
}
return actions;
}
public List<Increment> getIncrements() {
List<Increment> incs = new LinkedList<Increment>();
if (incCol != null) {
Increment inc = new Increment(incrementRow);
inc.addColumn(cf, incCol, 1);
incs.add(inc);
}
return incs;
}
public void close() {
}
public enum KeyType {
UUID,
RANDOM,
TS,
TSNANO,
TIMEPREFIX;
}
}HBaseSink工作方式:从configure方法获取配置信息,包括行键类型、行键前缀等,我在这里添加行键类型timePrefix可以配置某个时间字段作为行键前缀,因为HBase中按照行键升序排列。
flume配置
agent.sources = avroSrc
agent.channels = memoryChannel
agent.sinks = hbaseSink
agent.sources.avroSrc.type = avro
agent.sources.avroSrc.bind = 192.168.241.10
agent.sources.avroSrc.port = 1111
agent.sources.avroSrc.channels = memoryChannel
agent.sinks.hbaseSink.type = hbase
agent.sinks.hbaseSink.table = access_logs
agent.sinks.hbaseSink.columnFamily = log
agent.sinks.hbaseSink.serializer = com.mine.flume.sinks.MapBodyHbaseSink
agent.sinks.hbaseSink.serializer.rowPrefix = time_local
agent.sinks.hbaseSink.serializer.suffix = timePrefix
agent.sinks.hbaseSink.channel = memoryChannel
agent.channels.memoryChannel.type = memory
将项目打成jar包,放到flume的lib目录下
配置完成之后,启动flume
flume-ng agent -c /home/user/hadoop/apache-flume-1.7.0-bin/conf -f /home/user/hadoop/apache-flume-1.7.0-bin/conf/flume-conf.properties -n agent-c — 配置文件目录
-f — 配置文件位置
-n — agent名字(即配置文件中agent.sources其中agent就是名字)
问题
1.工作时,NoDefClass异常:ProtobufUtil
这个是由于打包时,直接用idea导出jar包,其中会包含依赖jar包中的class文件,所以导致与flume/lib中jar包重复冲突导致异常,利用mvn install打包文件之后,将仓库下jar文件复制到lib目录下就可以避免。