HBase
Hadoop DataBase,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。HBase利用Hadoop HDFS作为其文件存储系统,利用hadoop MapReduce来处理HBase来处理HBase中的海量数据,利用Zookeeper作为协调工具。
行键Row key
主键用来检索记录的主键,访问hbase table中的行
通过单个row key访问
通过row key的range
全表扫描
所有行按照行键字典顺序排序存储
一行包括一列或者多列
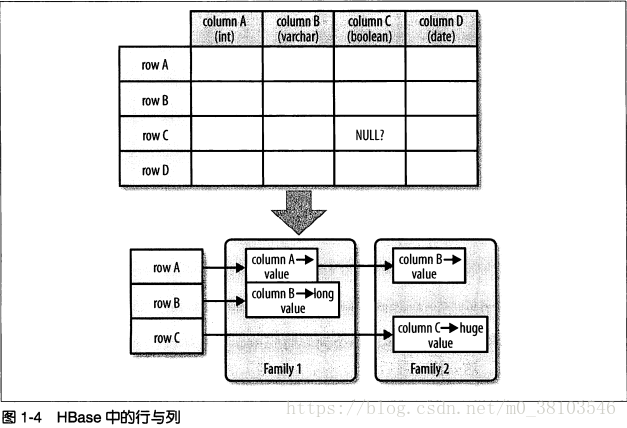
列族Column Family
列族在创建表的时候声明,一个列族可以包含多个列
一个列族的所有列存储在同一个底层的存储文件中,这个存储文件叫做HFile
列族不能修改的过于频繁,数量也不能太多
列
最基本的存储单位
列中的数据以二进制形式存在,没有数据类型和长度限制
列的数量没有限制:一个列族中可以有数百万个列
行与列
数据库中没有值的地方必须为null,但是在HBase中可以直接省略掉该列
时间戳timestamp
HBase中通过row和columns确定的一个存贮单元成为cell,每个cell都保存着同一个数据的多个版本;
通过时间戳来区分不同版本的值,一个单元格的不同版本值按降序排列在一起;
时间戳默认由系统指定,也可以由用户显示设置;
用户可以指定每个值所能保存的最大版本数量,也可以添加条件,如保存一周的数据

HBase基础知识
Master可以启动多个HMaster,通过Zookeeper的Master election机制保证总有一个master运行;
为Region server分配region
负责region server的负载平衡
发现失效的region server并重新分配其上的region
Region Server
维护Master分配给它的region,处理对这些region 的IO请求;
负责切分在运行过程中变得过大的region;
Client包含访问hbase的接口,client维护着一些cache来加快对hbase的访问,比如region的位置信息;
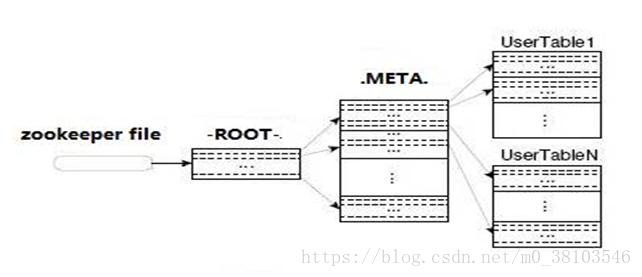
HBase中有两张特殊的table,-ROOT-和.META
-ROOT-记录.META.表的Region信息,-ROOT-只有一个region
.META.记录了用户创建的表的region信息,.META.可以有多个region
Zookeeper中记录了-ROOT-表的location
Client访问用户数据之前需要首先首先访问zookeeper,然后访问-ROOT-表,接着访问.META.表,最后才能找到用户数据的位置去访问。
HBase物理存储
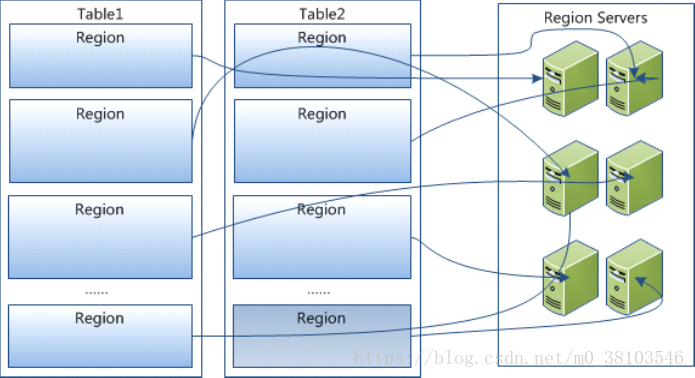
HBase中扩展和负载均衡的基本单元称为region,region本质上是以行键排序的连续存储区间。如果region太大,系统就会把他们动态拆分,相反地,就把多个region合并,以减少存储文件数量
每一个region只能由一台region服务器(region server)加载,每一台region服务器可以同时加载多个region。
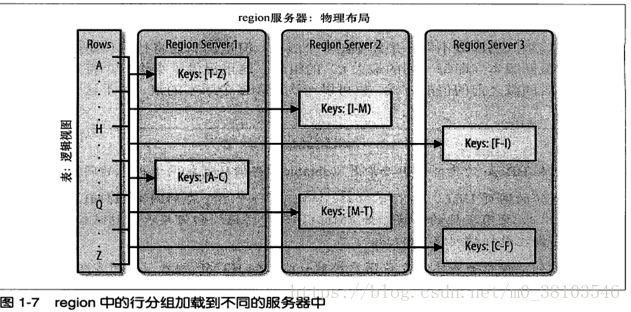
table在行的方向上分割为多个HRegion,一个region由(startkey,endkey)表示