支持向量机
1.前言
支持向量机(Support Vector Machine)是常用的分类模型,其核心思想是求解超平面使得数据集分成两堆,其中一堆是正例,另一堆是反例。但能够将数据集D分开的超平面存在很多个,如下图所示,我们应该如何选择最优超平面呢?
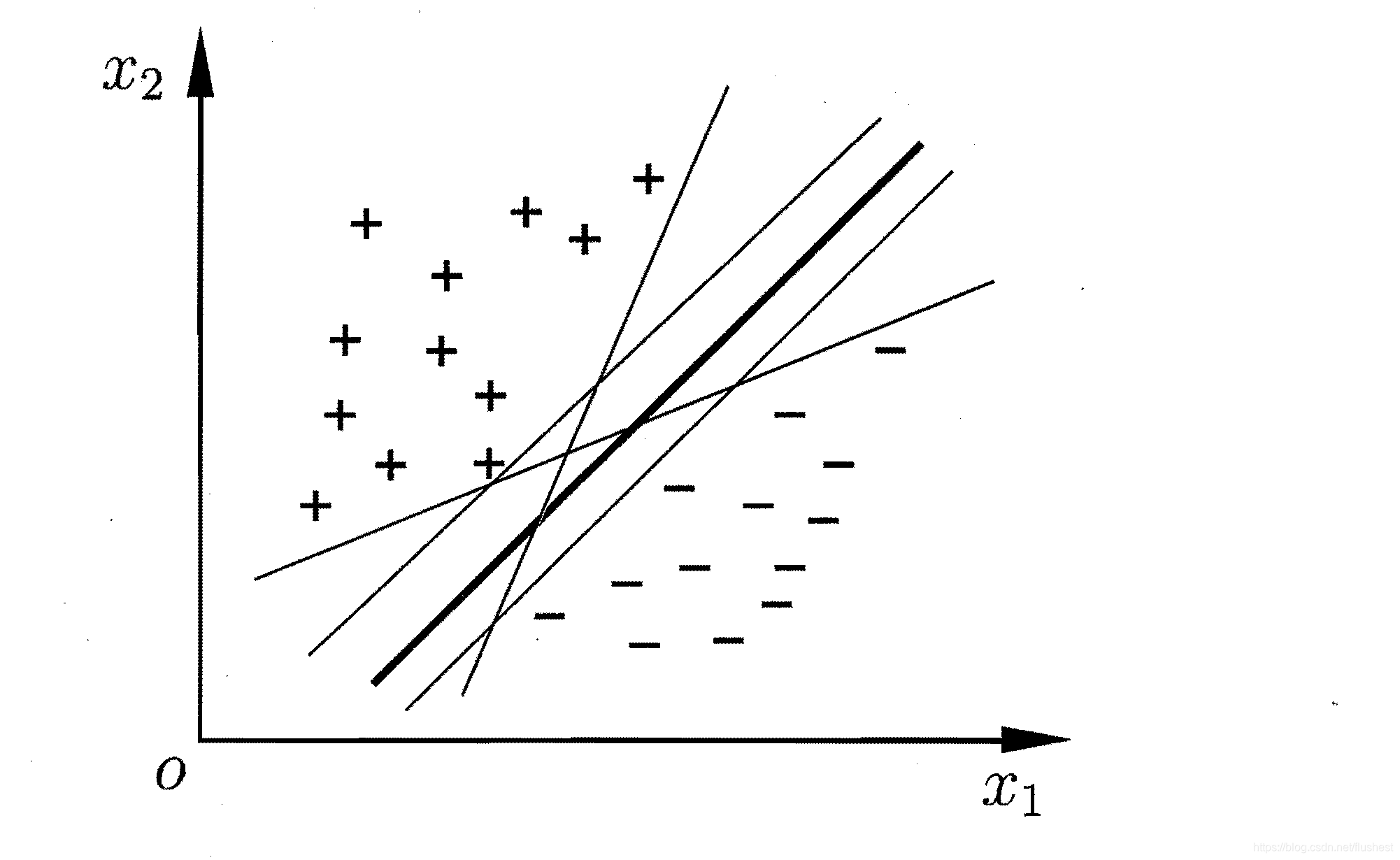
从直觉上看,粗线应该是最优超平面,因为正反例样本距离超平面最远、间隔最大。间隔越大,说明分类越准确,置信度越高。
在样本空间中,划分超平面可以通过如下线性方程来描述:
ωTx+b=0
其中,
ω=(ω1,ω2,...,ωk)为法向量,决定了超平面方向;b为位移项,决定了超平面与原点之间的距离。显然,正反例样本到超平面的距离与法向量、位移项有关。于是做出如下定义:
对于任意一点
(xi,yi)且
yi∈{−1.1},其到超平面
ωTx+b=0的距离可定义为
yi(ωTxi+b)。选择好划分超平面后,正反两类样本中到超平面距离最近的样本点被称为支持向量,其到超平面的距离被称为间隔,如下图。
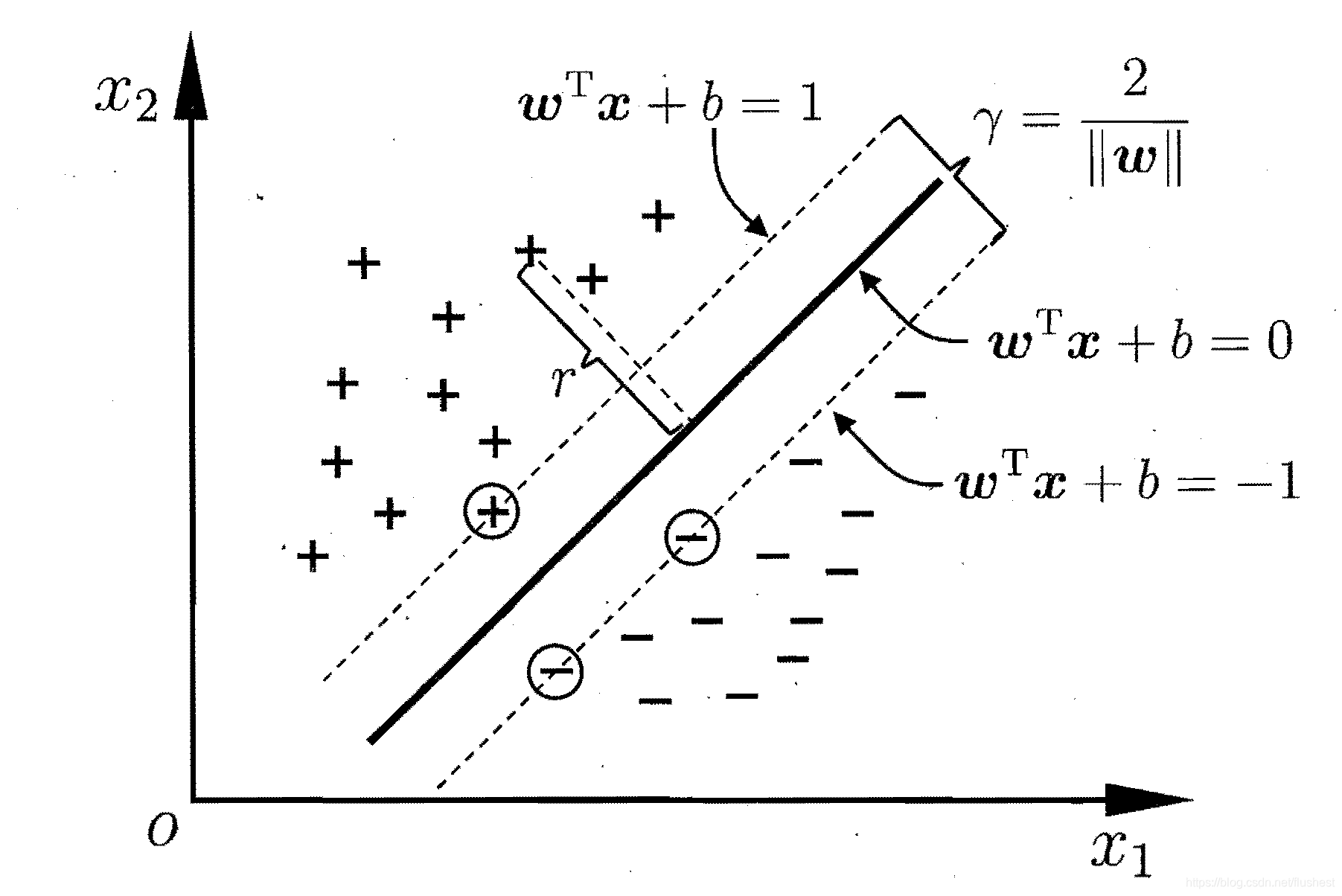
其中带圆圈的样本为支持向量,虚线之间的空白部分为间隔。间隔有两种定义:
函数间隔易受
∣∣ω∣∣影响,但超平面方程同除
∣∣ω∣∣,超平面不变,其间隔也应该不变,所以引入几何间隔来表示点到超平面距离。
2.线性可分支持向量机
线性可分是指一定存在某一个超平面使得数据集完全正确地分成正反两类,前言中图片展示的就是一个线性可分数据集。当然也存在一些数据集,比如异或关系的数据集,无法由一个平面来进行划分,可能需要曲面才能够划分,这样的数据集称为线性不可分。
线性可分支持向量机正是用来解决线性可分数据集分类问题的,其原始问题形式如下:
ω,bmax γ^s.t. yi(ωTxi+b)≥γ,i=1,2,...,n
又因为
γ^=∣∣ω∣∣γ,不妨取
γ=1,通过调整
ω来调整几何间隔。于是问题等价于
ω,bmax ∣∣ω∣∣1s.t. yi(ωTxi+b)≥1,i=1,2,...,n
将上式转化为最小值问题:
ω,bmin 21∣∣ω∣∣2s.t. yi(ωTxi+b)≥1,i=1,2,...,n
此时由于这是一个条件约束极值问题,转化为对偶问题:
-
拉格朗日函数
对于不等式约束条件下最小值拉格朗日函数通用形式为
xminf(x)s.t. hi(x)<0,gi(x)=0,i=1,...,n⇒L(x,a,λ)=f(x)+i=1∑naihi(x)+i=1∑nλigi(x) and ai≥0
于是原始问题拉格朗日函数为
L(ω,b,a)=21∣∣ω∣∣2+i=1∑nai[1−yi(ωTxi+b)], ai≥0
-
原始问题可转化为极小极大问题
对于拉格朗日函数
L(x,a,λ)=f(x)+∑i=1naihi(x)+∑i=1nλigi(x) and ai≥0有,
ai≥0,λimaxL(x,a,λ)={f(x),∞,hi(x)>0 or gi(x)̸=0hi(x)≤0 and gi(x)=0
显然,当不满足约束条件时,拉格朗日函数第二部分或者第三部分最大值趋于无穷大;当满足约束条件时,拉格朗日函数最大值为函数值f(x),于是取其最小值得
ω,bminai≥0maxL(ω,b,a)
-
对偶问题极大极小问题
ai≥0maxω,bminL(ω,b,a)
令
ψ(a)=minω,bL(ω,b,a),拉格朗日函数求偏导得
∂ω∂L=ω−i=1∑naiyixi∂b∂L=−i=1∑naiyi
令偏导为0,可得
,ω=∑i=1naiyixi,∑i=1naiyi=0,带入
ψ(a)得
ψ(a)=−21i=1∑nj=1∑naiyi⋅ajyj⋅xixj+i=1∑nai
于是,问题转化为
amax ψ(a)s.t.i=1∑naiyi=0, ai≥0,i=1,2,...,n
将上述问题转化为最小值问题得
amin 21i=1∑nj=1∑naiyi⋅ajyj⋅xixj−i=1∑nais.t.i=1∑naiyi=0, ai≥0,i=1,2,...,n
由此,得出线性支持向量机的最终问题形式,这种形式的极值问题采用SMO算法求解,在后面会谈到。最终得到的决策规则形式为
f(x)=sign(i=1∑naiyixi⋅x+b)
其中,选择支持向量
0<αi<C,则
b=yi−∑j=1najyjxj⋅xi
3.线性支持向量机
对于线性不可分数据集,如果存在一个划分超平面使得大部分点都能正确划分,只有比较少的点错误,那么可以使用线性支持向量机解决这个问题。在前面线性可分支持向量机中讲过,数据集中所有点到超平面的距离都应该大于函数间隔,但对于线性不可分数据集而言,定义软间隔,在函数间隔的基础上设置松弛变量,使分类器能够接受一定的错误分类。如下图所示,红色圆圈中的样本点都是存在松弛变量的,用形式化公式表示
,yi(ωTxi+b)≥1−ξi,ξi≥0,其中
ξi为松弛变量。显然,我们希望松弛变量越小越好。
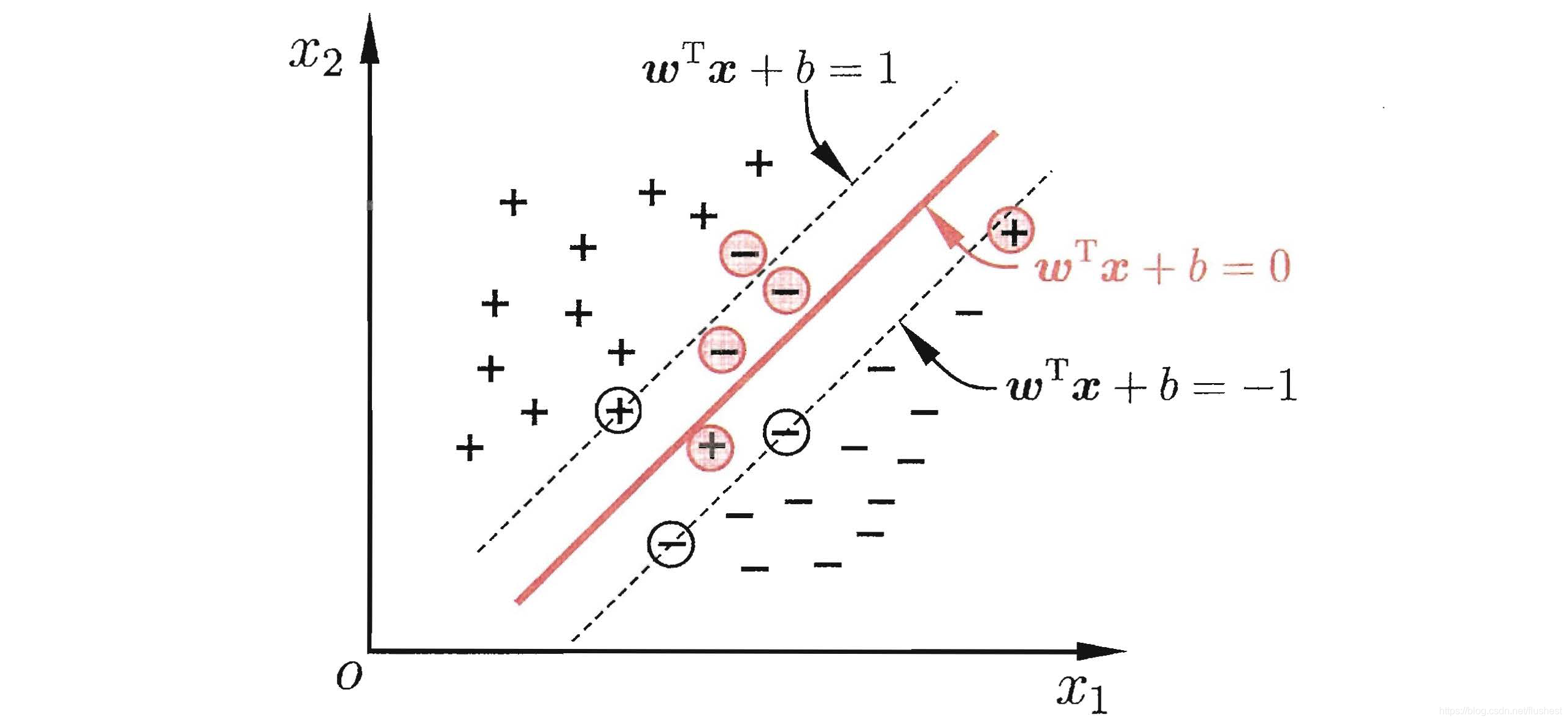
于是,线性支持向量机原始问题为
ω,b,ξmin 21∣∣ω∣∣2+Ci=1∑nξis.t. yi(ωTxi+b)≥1−ξi,ξi≥0,i=1,2,...,n and C>0
转化为对偶问题
-
拉格朗日函数
L(ω,b,ξ,a,μ)=21∣∣ω∣∣2+Ci=1∑nξi+i=1∑nai[1−ξi−yi(ωTxi+b)]−i=1∑nμiξi
-
原始问题极小极大问题
ω,b,ξminai≥0,μi≥0maxL(ω,b,ξ,a,μ)
-
对偶问题极大极小问题
ai≥0,μi≥0maxω,b,ξminL(ω,b,ξ,a,μ)
拉格朗日函数求偏导分别为
∂ω∂L=ω−i=1∑naiyixi∂b∂L=−i=1∑naiyi∂ξi∂L=C−ai−μi
令偏导为0,并带入原问题有
amin 21i=1∑nj=1∑naiyi⋅ajyj⋅xixj−i=1∑nais.t. i=1∑naiyi=0, 0≤ai≤C,i=1,2,...,n
从另一个角度看,原始问题中
21∣∣ω∣∣2表示第二范数,属于正则项,
C∑i=1mξi表示经验风险,其中
ξi=max{0,1−yi(ωTxi+b)}表示hinge损失函数。当然损失函数可以换成其他的,那么相应地转换为其他模型算法,后续再谈。
4.非线性支持向量机
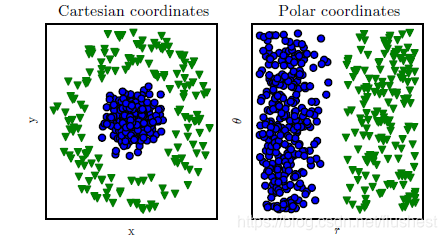
之前介绍的算法都不能解决真正的线性不可分数据集问题。考虑到机器学习算法效果是依赖于数据表现形式的,换个角度思考线性不可分问题,在原始维度空间无法找到超平面进行线性划分,但是当进行维度变换时,一定能够找到一个更高维度特征空间能够进行线性划分,这是由模式识别理论证明过的,如下图所示。数据集在直角坐标系中无法用直线完全正确地划分,但是当转换为极坐标系时,却能够进行线性划分。
那么如何进行维度变换呢?从之前导出的问题最终形式可以看出,样本数据通过
xi⋅xj形式整合到模型算法中。于是假设通过维度变换后样本数据整合形式为
ϕ(xi)⋅ϕ(xj),但是由于维度变换后特征向量维度不定,直接使用內积计算效率比较低。举例来说,原始样本空间中
x=[x1,x2,...,xn]T,经过维度变换后
ϕ(x)=[x1x1,x1x2,...,x1xn,...,xnx1,...,xnxn],于是
k(x,l)ϕ=(x)⋅ϕ(l)=∑i=1n∑j=1n(xixj)(lilj)=∑i=1n(xili)∑j=1n(xjlj)=(xTl)2。因此,核函数
K(x,l)时间复杂度为O(n)优于升维后內积。
(1)核函数定义
在举例中
k(x,l)=(xTl)2就是一个核函数,核函数指能够简化经过隐式维度变换后空间內积计算的函数。以下对核函数做出定义:
令
χ为输入空间,
k(⋅,⋅)是定义在
χ×χ上的对称函数,则K是核函数当且仅当对于任意数据
D={x1,x2,...,xm}有,“核矩阵”K始终是半正定的:
K=⎣⎢⎢⎢⎢⎢⎢⎡k(x1,x1)k(x2,x1)...k(xm,x1)k(x1,x2)k(x2,x2)...k(xm,x2)..................k(x1,xm)k(x2,xm)...k(xm,xm)⎦⎥⎥⎥⎥⎥⎥⎤
(2)常用核函数
在举例中先确定维度变换公式,再计算出核函数,但是在现实问题中往往不能够很容易地确定维度变换公式。所以人们常常从归纳总结出的常用核函数中,根据不同的问题和参数选择不同的核函数。常用核函数如下:
-
多项式核函数:适合正交归一化数据
k(x,z)=(x⋅z+1)p
-
高斯核函数:径向基核函数,适用性广,鲁棒性好,对参数敏感
k(x,z)=exp{−2δ2∣∣x−z∣∣2}
-
ANOVA核函数:适用于多维回归问题
k(x,z)=exp(−δ(xk−yk)2)d
-
sigmoid核函数:广泛应用于深度学习
k(x,z)=tanh(αx⋅z+c)
-
对数核:多用于图像分割
k(x,z)=−log(1+∣∣x−z∣∣d)
-
直方图交叉核:多用于图像分类
k(x,z)=k=1∑nmin{xk,zk}
5.SMO算法
SMO算法是一种启发式算法,用于快速解决凸二次优化问题。其基本思路是,如果所有变量都能够满足最优化问题KKT条件,那么最优化问题就能够求解出。选择所有变量中最不符合KKT条件的变量
α1,另一个变量
α2随着
α1的变化而变化,选择使
α1变化最大的
α2,其他所有变量固定不变。由此求解这个二次优化问题,不断逼近最优解。
算法推导过程:
令
K=∑i=3naiyi,并代入约束条件
∑i=1nαiyi=0得
α2y2=(−α1y1−K)
对偶问题展开可得
αmin21(α1y1x1+α2y2x2+i=3∑nαiyixi)(α1y1x1+α2y2x2+j=3∑nαjyjxj)−i=1∑nαi⇒αmin21[α12k(x1,x1)+2α1y1α2y2k(x1,x2)+α22k(x2,x2)+2(α1y1x1+α2y2x2)i=3∑nαiyixi+i=3∑nj=3∑nαiyi⋅αjyj⋅xixj]−i=1∑nαi
令
L=∑i=3n∑j=3nαiyi⋅αjyj⋅xixj, P=∑i=3nαiyixi,并代入对偶问题得
αmin21{α12k(x1,x1)−2(α12+Kα1y1)k(x1,x2)+(α1y1+K)2k(x2,x2)+2[α1y1(x1−x2)−Kx2]P+L}−i=1∑nαi⇒αmin21{α12[k(x1,x1)−2k(x1,x2)+k(x2,x2)]+α1[−2Ky1k(x1,x2)+2Ky1k(x2,x2)+2y1(x1−x2)⋅P−2(1−y1/y2)]}
对
α1求导可得
α1new=k(x1,x1)−2k(x1,x2)+k(x2,x2)Ky1k(x1,x2)−Ky1k(x2,x2)−y1(x1−x2)⋅P+(1−y1/y2)=k(x1,x1)−2k(x1,x2)+k(x2,x2)−y1(α1y1+α2y2)[k(x1,x2)−k(x2,x2)]−y1(x1−x2)∑i=1nαiyixi+y1(x1−x2)(α1y1x1+α2y2x2)+1−y1y2=k(x1,x1)−2k(x1,x2)+k(x2,x2)α1[k(x1,x1)−2k(x1,x2)+k(x2,x2)]−y1[∑i=1nαiyik(x1,xi)−∑i=1nαiyik(x2,xi)]+1−y1y2=α1−k(x1,x1)−2k(x1,x2)+k(x2,x2)yi[∑i=1nαiyik(x1,xi)−∑i=1nαiyik(x2,xi)]−1+y1y2
进一步地,因为
,k(x1−x2,x1−x2)=k(x1,x1)−2k(x1,x2)+k(x2,x2),y12=1有
α1new=α1−k(x1−x2,x1−x2)y1[∑i=1nαiyik(x1,xi)−∑i=1nαiyik(x2,xi)]−(y12−y1y2)=α1−k(x1−x2,x1−x2)y1{[∑i=1nαiyik(x1,xi)+b−y1]−[∑i=1nαiyik(x2,xi)+b−y2]}
令
,η=k(x1−x2,x1−x2),Ei=g(xi)−yi=∑j=1nαjyjk(xi,xj)+b−yi,其中
Ei表示预测值与真实值之间误差。于是
α1new=α1old−ηy1(E1−E2)
α2new=y2[(α1old−α1new)y1+α2oldy2]=α2old+y1y2(α1old−α1new)
进一步地,
α1,α2应该满足约束条件
0≤α1,α2≤C,于是优化后的
α1new,α2new在二维空间中图像表示如下:
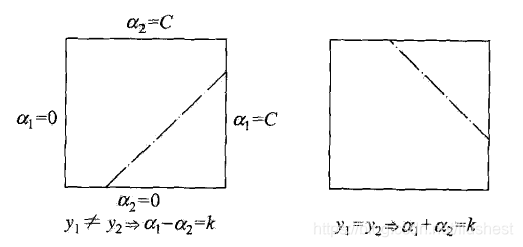
故,取L与H分别为
α1new约束下界和上界,当
y1̸=y2时
L=max{0,α1old−α2old}, H=min{C,C+α1old−α2old}
当
y1=y2时,
L=max{0,α1old+α2old−C}, H=min{C,α1old−α2old}
因此,
α1new=⎩⎪⎨⎪⎧H,α1new,L,α1new>HL≤α1new≤Hα1new<L
α2new=y2[(α1old−α1new)y1+α2oldy2]=α2old+y1y2(α1old−α1new)
接下来,问题关键是如何选取变量
α1,α2,先选取违反KKT条件的变量作为
α1,再选取
∣E1−E2∣最大的变量作为
α2。其中KKT条件为
αi=00<αi<Cαi=C⇒⇒⇒yig(xi)≥1yig(xi)=1yig(xi)≤1
更新
α1,α2后,需要同时更新b,分以下情况:
-
α1,α2中至少存在一个支持向量:
b=yi−∑j=1najyjxj⋅xi,其中
xi表示支持向量
-
α1,α2均不是支持向量:令
bi=yi−∑j=1najyjxj⋅xi,则
b=(b1+b2)/2
6.算法实现
import numpy as np
from math import *
class SVM(object):
def __init__(self, C, kernel):
self.C = C
self.kernel = kernel
def g(self, x, alpha, b, trainMat, trainLabels):
n = trainMat.shape()[0]
return np.sum([alpha[i]*trainLabels[i]*self.kernel(x,trainMat[i]) for i in range(n)]) + b
def train(self, trainMat, trainLabels):
n,m = trainMat.shape()
alpha = np.zeros((n,1))
b = np.sum(trainLabels)/n
while True:
G = np.array([self.g(trainMat[i], alpha, b, trainMat, trainLabels) for i in range(n)])
dis = np.multiarray(G, trainLabels)
status = [ 1 if alpha[i]==0 and dis[i] < 1 or 0< alpha[i] < self.C and dis[i] != 1 or alpha[i]==self.C and dis[i] > 1 else 0 for i in range(n)]
if 0 == sum(status):
break
i = status.index(1)
E = G - trainLabels
delta = [fabs(E[j] - E[i]) for j in range(n)]
j = delta.index(max(delta))
eta = self.kernel(trainMat[i]-trainMat[j], trainMat[i]-trainMat[j])
aiNew = alpha[i] - trainLabels[i]*(E[i]-E[j])/eta
if trainLabels[i] == trainLabels[j]:
L = max(0, alpha[i]+alpha[j]-self.C)
H = min(self.C, alpha[i]-alpha[j])
else:
L = max(0, alpha[i]-alpha[j])
H = min(self.C, self.C+alpha[i]-alpha[j])
if aiNew > H:
aiNew = H
elif aiNew < L:
aiNew = L
ajNew = alpha[j] + trainLabels[i]*trainLabels[j]*(alpha[i]-aiNew)
alpha[i] = aiNew
alpha[j] = ajNew
if 0<aiNew<self.C:
b = trainLabels[i] - G[i] + b
elif 0<ajNew<self.C:
b = trainLabels[j] - G[j] + b
else:
b = (trainLabels[i] - G[i] + trainLabels[j] - G[j])/2 + b
self.alpha = alpha
self.b = b
self.trainMat = trainMat
self.trainLabels = trainLabels
def predict(self, x):
if self.g(x, self.alpha, self.b, self.trainMat, self.trainLabels) > 0:
return 1
else:
return 0
参考资料
github代码地址https://github.com/flushest/machine-learning-practice