1.前言
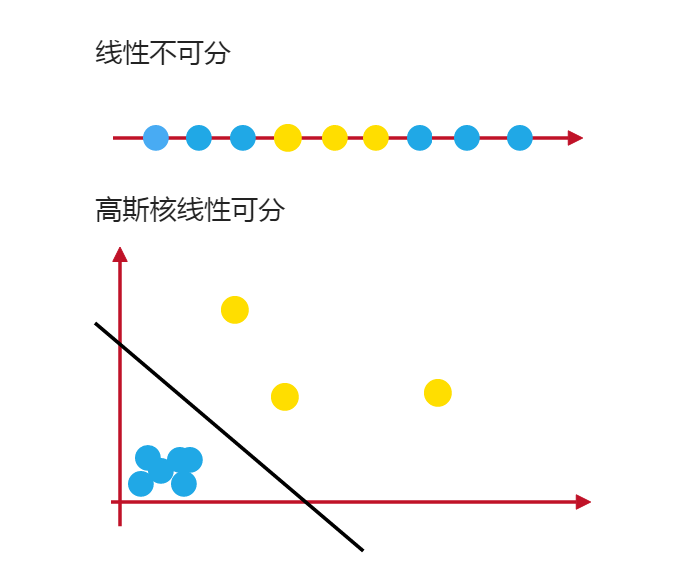
如图,对于一个给定的数据集,通过直线A或直线B(多维坐标系中为平面A或平面B)可以较好的将红点与蓝点分类。那么线A与线B那个更优呢?
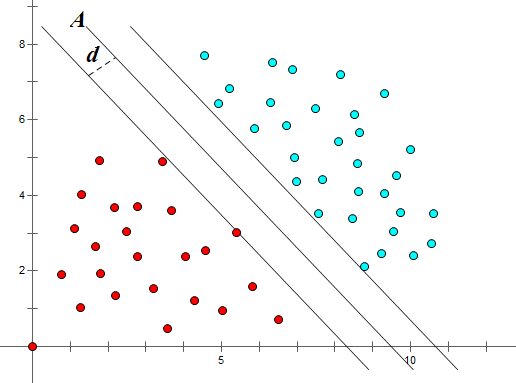
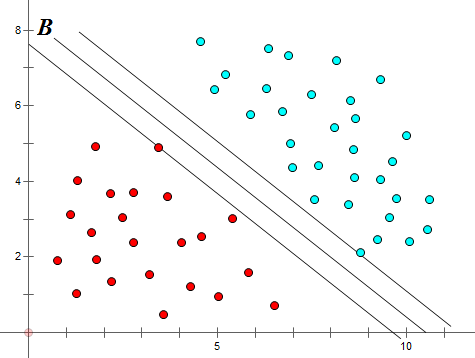
在SVM算法中,我们认为线A是优于线B的。因为A的‘分类间隔’大于B。
那么什么是分类间隔呢? 以A线所在图为例,平移直线A直到找到一个极限位置,越过该位置,就会产生分类错误的现象。如图,直线A左右两边的直线就是所谓的极限位置,再往左或者往右移动一下直线都会出现分类错误的情况。这2条直线之前的垂直距离就是分类间隔。(2d)
而这2条直线中间的分界线也是分类间隔中心所在的直线就是SVM的‘最优决策面’
而这两条直线上面的点,我们称之为‘支持向量’
通俗一点来说,SVM的分类目的就是找到最大的分类间隔即使得2倍的d最大。
2.SVM的最优化问题
首先回顾一下初中便开始接触的知识:
对于求坐标系中任意点到直线
的距离,我们很容易给出下面的式子:
把这个原理应用在N维的空间会怎样?首先N维空间的曲线我们可以用一个我们熟知的式子来表示:
那么空间中任意一点到曲线的距离可以表示为:
其中:。
我们令左侧的数据的类别为-1,及对应决策平面左侧的点。同理,右侧的点为+1,
。
你不用去在意为什么是-1和1,实质上你可以令其为任何你想的数,只是用1和-1会在之后的计算中更为简便一些。
那么决策平面A左右2侧的极限位置外的点我们就可以这样表示:
移项:
我们令
那么原式就可以转化为:
对于决策平面A我们也可以用同样的方式表示:
这里有个技巧性的办法,因为我们之前令。那么上式也可以转化为:
为了之后的便于书写,通常情况下,在这个时候,我们会直接设
*这里的与
与之前的
,
是不同的概念,相差了一个系数
的关系,这样做也是为了便于书写,这些是约定俗成的
*记住在这之后的与
都是
,
这样之后
就转化为了
所以我们求最大分割间隔的长度问题就可以表示为:
而我们知道决策平面平移的极限条件为,所以:
通常情况下我们不会去求而是转而去求
的值,这实质上也是为了计算方便,但是从理论上上两者结果并无差别。
我们梳理一下重点内容,通过上面的推到,我们把一个分类的问题转化为了一个最优化问题,
(
表示的是限定的条件)
3.解决SVM最优化问题
上一节我们由分类间隔的思想得到一个最优化问题。这节将以纯数学的方式和大家一起解决这个最优化问题。
首先需要为大家介绍一下,拉格朗日算子。
百度百科:
在数学最优化问题中,拉格朗日乘数法(以数学家约瑟夫·路易斯·拉格朗日命名)是一种寻找变量受一个或多个条件所限制的多元函数的极值的方法。这种方法将一个有n 个变量与k 个约束条件的最优化问题转换为一个有n + k个变量的方程组的极值问题,其变量不受任何约束。这种方法引入了一种新的标量未知数,即拉格朗日乘数:约束方程的梯度(gradient)的线性组合里每个向量的系数。
拉格朗日算子的定义是生涩不易懂的,所以这里我将用一个例题来让对SVM中拉格朗日算子的作用有更深刻的认识:
例:给定椭球,求这个椭球的内接长方体的最大体积,即
的最大值
解:建立拉普拉斯算式,算式的偏导为0
对
的偏导结果为0
联立四个方程:
代入:
于是得到:
同样以拉格朗日的算子的原理来求解我们SVM分类的最优化问题:
(
表示的是限定的条件)
由拉格朗日算子定义可以转化成:
其中对
的偏导为0
得到结果:
将这2个结果代入:
所以我们的最优化问题就转化为了:
4.SVM的核函数
在第三节中,我们将最优化问题使用拉格朗日算子进行了转化,在这一小节要介绍的是SVM的核函数,了解SVM是怎么通过核函数减少欠拟合和过拟合现象的。
首先观察式子
发现这个式子会对每个进行点乘,现在我们将
添加上多项式特征使其得到更为复杂的分割曲线:
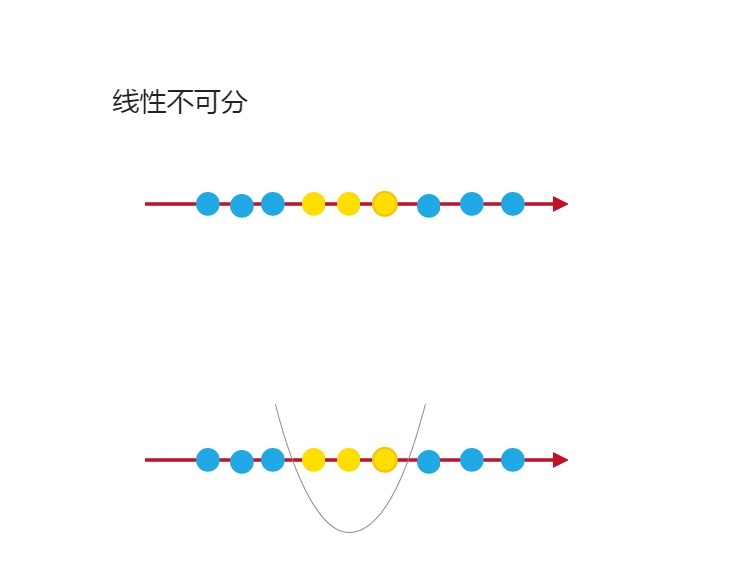
我们设具有多项式特征的表示为
,现在假设,我们找到一个函数使得:
那么求解具有多项式特征的SVM分类器的最优化问题就转化为:
而这个函数就是所谓的核函数:
如果不使用核函数,那么我们需要先将转化为
然后再将
代入最优化式子去求解。而设定这个核函数就是为了直接将
代入最优化式子求得多项式最优解。这样减少了部分计算机计算开销和存储开销。
从这一点可以看出核函数并不是SVM的专用方法,实质上在我们求解最优化问题上遇到点乘
的时候,我们都可以使用到核函数这种技巧。
4.0线性核函数:
4.1多项式核函数(poly):
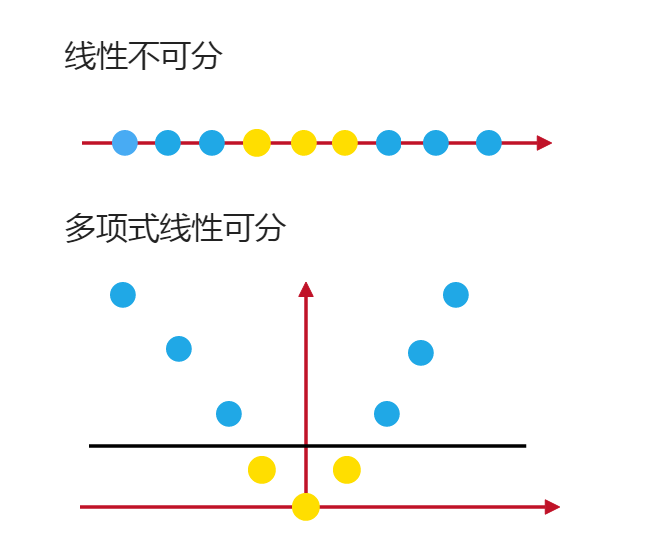
我们以2次项为例子,如果我们直接算,我们需要下面这个几个步骤:
通过上面这个式子,我们可以直接理解为我们将原来的转化成了
而使用到核函数这种方法,我们就直接将x,y带入,这种方式大大的降低了我们计算的复杂度。
回到这个我们最优化问题中:
我们只用将替换成
,就为其添加了多项式的特征。其实应该为
这个C为正则化的系数。
4.2高斯核函数(rbf):
首先我们介绍下高斯函数:
高斯核的转化方式如上图:双曲线与坐标轴的交点为
关于高斯核函数的解释我使用可视化的方式我觉得这样可以方便理解:使用工具python的numpy和matpoltlib
import numpy as np
import matplotlib.pyplot as plt#定义一个从-4到5分布的数值,分割间隔为1
In [1]:x=np.arange(-4,5,1)
Out[1]: array([-4, -3, -2, -1, 0, 1, 2, 3, 4])
#将-2到2之间的点归为一类,类别为1,将小于-2和大于2的点归为一类,类别为0
In [2]:y=np.array((x>=-2)&(x<=2),dtype='int')
Out[2]: array([0, 0, 1, 1, 1, 1, 1, 0, 0])#可视化一下
plt.scatter(x[y==0],[0]*len(x[y==0]))
plt.scatter(x[y==1],[0]*len(x[y==1]))
plt.show()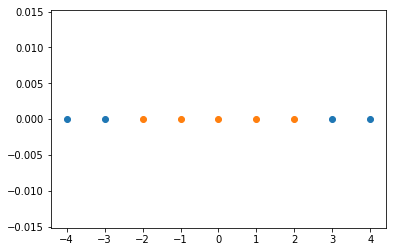
#定义高斯核的公式:
def gaussian(x,l):
gamma=1.0
return np.exp(-gamma * (x-l)**2)
#定义L1和L2的值,即分类的边界点
l1 , l2 = -1, 1
#开辟一个新的空间,用于存放之后计算出来的额高斯值
new_x = np.empty((len(x),2))
#将x中的每个值代入高斯核函数中
for i,data in enumerate(x):
new_x[i,0] = gaussian(data, l1)
new_x[i,1] = gaussian(data, l2)#可视化一下代入高斯核函数后的x分布情况
plt.scatter(new_x[y==0,0],new_x[y==0,1])
plt.scatter(new_x[y==1,0],new_x[y==1,1])
plt.show() 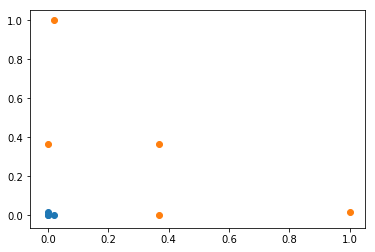
从可视化的图形可以看出,经过高斯核函数后的x变得线性可分了。
打赏一下作者:
