【编译原理】第一章:引论
标签(空格分隔):【编译原理】
第一章:引论
我的微信公众号

文章目录
编译原理介绍的是设计和实现编译器的方法。其涉及的内容有:程序设计语言、计算机体系结构、形式语言理论、算法、软件工程。
1.1 语言处理器
- 编译器(compiler):将程序翻译成一种能够被计算机执行的形式。
- 翻译器(interpreter):解释器直接利用用户提供的输入执行源程序中的操作。
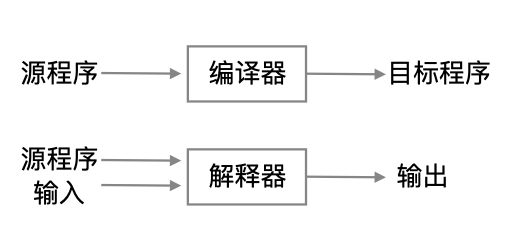
二者的区别:一个编译器产生的机器语言目标程序通常比一个解释器快的多;解释器的错误诊断效果要比编译器要好。
例如:Java语言处理器结合了编译和解释的过程。
一个java程序首先被编译成字节码的中间表示形式,然后由虚拟机对得到的字节码进行解释执行。
这样的好处之一是 在一台机器上编译得到的字节码可以在另一台机器上解释执行。通过网络就可以完成机器之间的迁移。
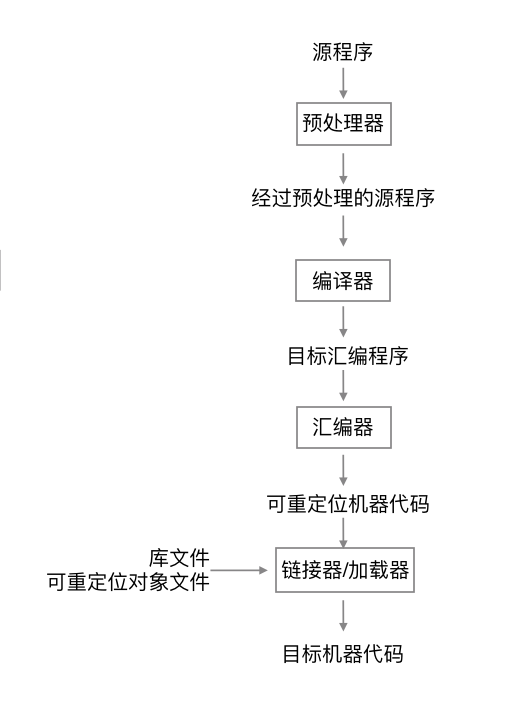
一个源程序可能被分割为多个模块,并存放于独立的文件中。
将源程序汇聚在一起的任务有时会由一个被称为预处理器(preprocessor)的程序处理完成。(预处理器还负责把宏的缩写形式转换为源语言的语句。)
然后,经过预处理的源程序作为输入传递给一个编译器。编译器可能产生一个汇编语言作为输出(因为汇编语言容易输出和调试)。
接着,这个汇编语言程序由汇编器(assembler)进行处理,并生成可重定位的机器代码。
大型程序经常被分割为多个部分进行编译,因此,可重定位的机器代码有必要和其他可重定位的目标文件以及库文件链接在一起,形成真正在机器上运行的代码。
一个文件中的代码可能只想另一个文件中的位置。链接器(linker)能够解决外部内存地址的问题。最终,加载器(loader)把所有可执行目标文件放在内存中执行。
1.2 一个编译器的结构
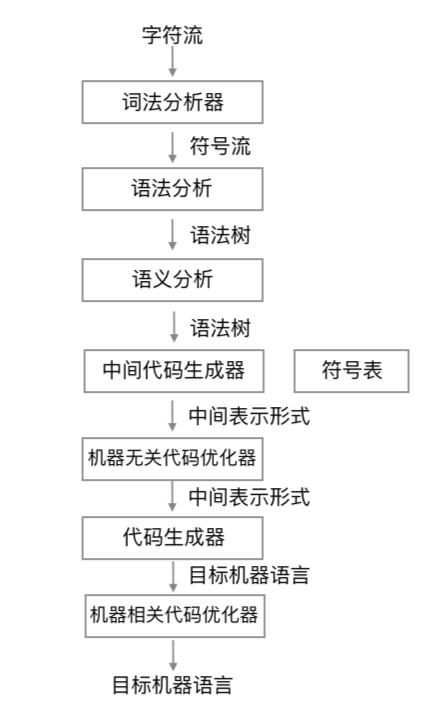
编译器的主要任务:将源程序映射为在语义上等价的目标程序。
其主要由两部分组成:分析部分和组合部分。
分析部分被成为编译器的前端(front end),综合部分被称为后端(back end)。
- 分析(analysis)部分:将源程序分解为多个组成要素,并在这些要素上添加语法结构。然后,使用这个结构创建该源程序的一个中间表示。如果分析部分检查出源程序没有按照正确的语法构成,或者语义上不一致,则它必须提供错误信息,以帮助用户改正。另外,分析部分还会收集有关源程序的信息,并把信息存放在名为符号表(symbol table)的数据结构中。符号表将和中间表示形式一起传送给综合部分。
- 综合(synthesis)部分:根据中间表示和符号表中的信息来构造用户期待的目标程序。
1.2.1 词法分析
- 词法分析(lexical analysis):又称扫描(scanning),是编译器的第一个步骤。词法分析器读入组成源程序的字符流,并将它们组织为有意义的词素(lexeme)的序列。
对于每个词素,词法分析器产生形如 <token-name, attribute-value> 的词法单元(token). 其中,token-name是一个又语法分析步骤使用的抽象符号,attribute-value是指向符号表中关于词法单元的条目。符号表中条目的信息会被语义分析和代码生成步骤使用。
随后,该词法单元被传送给下一个步骤,即语法分析。
例:假设一个源程序中包含如下的赋值语句:
以上赋值语句中的字符可以组合成如下词素,并映射成相应的词法单元,后被传送语法分析阶段。
- $ postion $ 是一个词素,被映射为词法单元<id,1>. 其中 id是标识符(identifier)的抽象符号,'1’指向符号表中$ postion$对应的条目。 一个标识符对应的符号表条目存放该标识符相关的信息。
- 赋值符号 ‘=’ 是一个词素,被映射为词法单元< = >, 因为这个词法单元不需要属性,所以可以省略第二个分量。也可以使用assign这样的抽象符号作为词法单元的名字。
- 是一个词素,被映射成词法单元<id,2>.
- '+'是一个词素,被映射成词法单元< + >.
- $ rata $ 是一个词素,被映射成词法单元<id,3>.
- ‘*’ 是一个词素,被映射成词法单元< * >.
-
是一个词素,被映射成词法单元< 60 >.
另外,分割词素的空格将被词法分析器忽略。
经过词法分析之后,上述复试值语句会被表示成如下的词法单元序列。
1.2.2 语法分析
- 语法分析(syntax analysis):又称为解析(parsing),是编译器的第二个步骤。语法分析器使用词法分析器生成的各个词法单元的第一个分量来创建树形的中间表示。该中间表示给出了词法分析产生的词法单元流的语法结构。
- 语法树(syntax tree):一种语法分析的表示方法,树中的每一个内部结点表示一个运算,而该结点的子结点表示该运算的分量。
还是上例:
经过词法分析之后,依照运算符优先级,我们可以生成如下语法树:
=
/ \
<id,1> +
/ \
<id,2> *
/ \
<id,3> 60
1.2.3 语义分析
- 语义分析器(semantic analyzer):使用语法树和符号表中的信息来检查源程序是否和语言定义的语义一致。同时也收集类型信息,并把这些信息存放在语法树或符号表中,以供使用。
- 类型检查(type checking):语义分析的另外一个重要步骤是类型检查。编译器检查每一个运算符是否匹配运算分量。
- 自动类型转换(coercion):例如在上例中,如果其他的postion、initial、rate均为浮点数,则整数60会转化为浮点数。
1.2.4 中间代码生成
语法分析和语义分析结束之后,编译器会生成一个明确的低级/类机器语言的中间表示。中间表示的两个重要性质:易于生成,易于翻译。
把一个源程序翻译成目标代码的过程中,一个编译器可能构造出一个或者多个中间表示。这些中间表示可以又多种形式。语法树是一种中间表示形式,通常在语义分析和语法分析中使用。
- 三地址代码(three-address code):每个指令具有三个运算分量,每个运算分量都像一个寄存器。三地址赋值指令的右部最多只有一个运算符;编译器应该生成一个临时名字存放一个三地址指令计算得到的值;三地址指令的运算分量可以少于三个。
在上例中,中间代码生成器的输出如下:
t1 = inttofloat(60)
t2 = id3 * t1
t3 = id2 + t1
id1 = t3
1.2.5 代码优化
机器无关的代码优化步骤试图改进中间代码,以便生成更好的目标代码。
上例中,优化器可以转化为更短的指令序列:
t1 = id3 * 60.0
id1 = id2 + t1
1.2.6 代码生成
代码生成器以源程序的中间表示形式作为输入,并把它映射到目标语言。如果目标语言是机器代码,则必须为程序使用的每个变量选择寄存器或内存位置。然后,中间指令被翻译成为能够完成相同任务的机器指令序列。
编译器在中间代码生成或代码生成阶段作出有关存储分配的决定。
上例中,假设使用寄存器 R1和 R2,则中间代码可以被翻译成如下的机器代码:
LDF R2, id3
MULF R2, R2, #60.0
LDF R1, id2
ADDF R1, R1, R2
STF id1, R1
1.2.7 符号表管理
编译器的重要功能之一是记录源程序中使用的变量的名称,并收集相关的属性。这些属性可以提供一个名字的存储分配、类型、作用域等信息。对于过程名字,还应包括参数的数量和类型、参数的传递方法、返回类型等。
符号表数据结构应该为每个变量名字创建一个记录条目。记录的字段就是名字的各个属性。这个数据结构应该允许编译器迅速查找每个名字的记录,并向记录中快速存放和获取记录中的数据。
1.2.8 将多趟步骤组合成趟
1.2.9 编译器的构造工具
与软件开发相同,编译器开发者可以利用软件开发环境。这些环境中包含了诸如语言编辑器、调试器、版本管理、程序描述器、测试管理等工具。
一些常用的编译器构造工具包括:1. 语法分析器的生成器。2. 扫描器的生成器。3. 语法制导的翻译引擎。4. 代码生成器的生成器。5. 数据流分析引擎。6. 编译器构造工具。
1.3 程序设计语言的发展历史
1.3.1 分类
第一种分类方式:按照语言的代。
第一代语言:机器语言
第二代语言:汇编语言
第三代语言:高级程序设计语言:如C/C++、Java、C#、Cobol、Lisp、Fortran
第四代语言:为特定应用设计的语言,如SQL、NOMAD、Postscript
第五代语言:基于逻辑和约束的语言。如Prolog、OPS5
第二种分类方式:按照执行方式
强制式(imperative)语言:程序中指明如何完成一个计算任务的语言。例如C、C++、C# 和Java.
声明式(declarative)语言:程序中指明要进行那些计算的语言。例如ML、Hakell、Prolog.
- 冯诺伊曼语言:以冯诺伊曼计算机体系结构为计算机模型的程序设计语言。如Fortran和C.
- 面向对象语言:指支持面向对象编程的语言。面向对象编程指用一组相互作用的对象组成程序的编程风格。例如C++、Java等。
- 脚本语言:指具有高层次运算符的解释型语言,它通常被用于把多个计算过程粘合在一起。例如Awk、JavaScript、PHP、python等。
1.3.2 对编译器的影响
语言的设计与编译器是密切相关的。
1.4 构建一个编译器的相关科学
使用抽象方法解决问题:接受一个问题,抓住其关键特征的数学抽象表示,用数学技术解决它。
1.4.1 编译器设计和实现中的建模
对编译器的研究主要是有关如何设计正确的数学模型和选择正确的算法的研究。另外,还需要考虑通用型及功能的要求与简单性及有效性之间的平衡。
1.4.2 代码优化的科学
优化一词并不恰当,因为没办法保证一个编译器生成的代码比完成相同任务的其他代码更快
优化,更直观的理解指:编译器为了生成比浅显直观的代码更加高效的代码而做的工作。
编译器优化必须满足以下目标:1. 正确性。不能改变程序的含义。2. 必须改善程序的性能。3. 优化花费的时间必须在合理范围之内。4. 保障编译系统的可管理性。
1.5 编译技术的应用
- 高级程序设计语言的实现。
- 针对计算机体系结构的优化:并行、内存层次结构
- 新计算机体系结构的设计:RISC、专用体系结构
- 程序翻译:二进制翻译、硬件合成、数据查询解释器、编译后模拟
- 软件生产率工具:类型检查、边界检查、内存管理工具
1.6 程序设计语言基础
1.6.1 静态和动态的区别
- 静态(static)策略:在编译时刻(compile time)决定。
- 动态(dynamic)策略:在运行时刻(runtime)决定。
- 作用域(scope):程序的一个区域。
- 静态作用域(static scope):又可称为词法作用域(lexical scope),仅可以通过阅读程序就确定一个声明的作用域。
- 动态作用域(dynamic scope):当程序运行时,同一个对x的使用会指向x的声明中的一个。对一个名字x的使用指向的是最近被调用但还没有终止且声明了x的过程的这个声明。
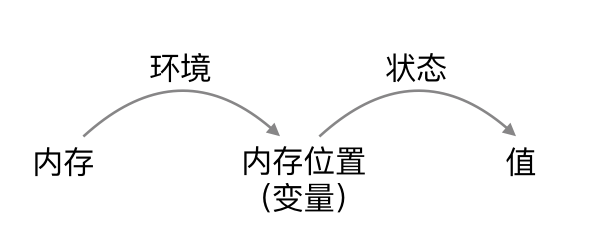
1.6.2 环境与状态
- 环境(environment):从名字到存储位置的映射。
- 状态(state):从内存位置到值的映射。
1.6.3 静态作用域 和 块结构
大多数语言,例如C语言和其同类,使用静态作用域。
C语言的作用域规则是基于程序结构的,一个声明的作用域由该声明在程序中出现的位置隐含地决定。
- 块(block):声明和语句的一个组合。C中用{}来界定一个块。
1.6.4 显示访问控制
类和结构为它们的成员引入了新的作用域,和块结构类似,类C的一个成员声明x的作用域可以扩展到所有子类C’,除非C’又一个本地的对同一个名字的声明。
封装:
private:
public:
protected:
声明 与 定义 的不同:例如:int i;是一个声明,i=1;是i的定义。
1.6.5 动态作用域
- 多态过程:对同一个名字根据参数类型具有两个或多个定义的过程。
动态作用域的解析对多态过程是必不可少的。
1.6.6 参数传递机制
- 值传递:当是表达式时,会对 实在参数 求值;当是变量时,则进行拷贝。被调用过程所做的有关形式参数的计算都局限于这个过程,相应的实在参数本身不会变化。
- 引用调用:实在参数的地址作为相应的形式参数的值被传递给被调用者。例如C中可以传递指针、C/C++,Java传递数组名字(相当于首地址)。
- 名调用:在Algol语言中使用。当今已经不再使用。
1.6.7 别名
-
别名(alias):引用调用或其他类似的方法,可能会导致两个形式参数指向同一个位置。此时一个变量的修改同时会修改另一个变量的值。