版权声明:原创文章转载需注明出处。 https://blog.csdn.net/qq_36607894/article/details/90112757
线性判别分析,Linear Discriminant Analysis,一种用于二分类的很经典的线性学习方法,1936年由Fisher 提出,so也称为Fisher判别分析。它和PCA一样,也是一种降维方法。
LDA方法属于模式识别领域。过拟合 ,模型无法适用于新数据。不必要的特征甚至可能带来不可预知的影响 。除此以外,过多的特征运算量也太大。因此,降维很必要。
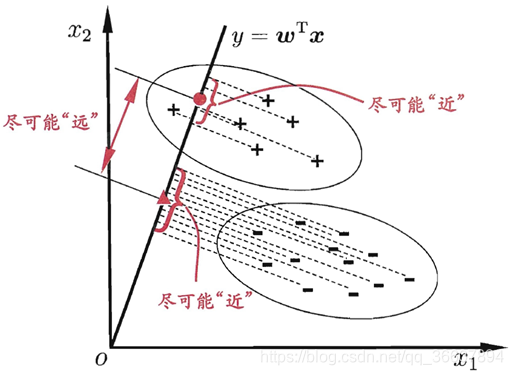
训练阶段:通过投影进行降维 ,把所有带标签的训练数据点投影到一个直线(or低维超平面),使得两类数据点投影后的位置满足,类内离差最小,类间离差最大 ,即同类样本的投影点尽可能接近 ,异类样本的投影点尽可能远离 。
贴一张周志华西瓜书的图:找这个投影方向 。分界线的方程为
y
=
w
T
x
y={\boldsymbol w}^T{\boldsymbol x}
y = w T x
w
\boldsymbol w
w
测试阶段:把新数据点也投影到同一个低维超平面,根据投影点的位置判断类别。
(不明白时结合上面的图去看)
假设样本分两类,第0类和第1类,对应两个子集
X
0
,
X
1
X_0,X_1
X 0 , X 1
N
0
,
N
1
N_0,N_1
N 0 , N 1
投影到的直线/低维超平面的方程是
y
=
w
T
x
y=\boldsymbol w^T\boldsymbol x
y = w T x
从核心思想的两个角度分别出发,建立部分的数学模型:
类间距离尽可能大 :
μ
0
,
μ
1
\boldsymbol{\mu_0},\boldsymbol{\mu_1}
μ 0 , μ 1
μ
0
=
1
N
0
∑
x
∈
X
0
x
\boldsymbol{\mu_0}=\frac{1}{N_0}\sum_{\boldsymbol x\in X_0 }\boldsymbol x
μ 0 = N 0 1 x ∈ X 0 ∑ x
μ
1
=
1
N
1
∑
x
∈
X
1
x
\boldsymbol{\mu_1}=\frac{1}{N_1}\sum_{\boldsymbol x\in X_1 }\boldsymbol x
μ 1 = N 1 1 x ∈ X 1 ∑ x
两个中心到直线上的投影分别为
w
T
μ
0
和
w
T
μ
1
\boldsymbol w^T\boldsymbol{\mu_0}和\boldsymbol w^T\boldsymbol{\mu_1}
w T μ 0 和 w T μ 1
为了使类间距离最大,则应最大化这两个投影点之间的距离:
∣
∣
w
T
μ
0
−
w
T
μ
1
∣
∣
2
2
||\boldsymbol w^T\boldsymbol{\mu_0}-\boldsymbol w^T\boldsymbol{\mu_1}||_2^2
∣ ∣ w T μ 0 − w T μ 1 ∣ ∣ 2 2
∣
∣
w
T
(
μ
0
−
μ
1
)
∣
∣
2
2
=
||\boldsymbol w^T(\boldsymbol{\mu_0}-\boldsymbol{\mu_1})||_2^2=
∣ ∣ w T ( μ 0 − μ 1 ) ∣ ∣ 2 2 =
w
T
(
μ
0
−
μ
1
)
[
w
T
(
μ
0
−
μ
1
)
]
T
=
\boldsymbol w^T(\boldsymbol{\mu_0}-\boldsymbol{\mu_1})[\boldsymbol w^T(\boldsymbol{\mu_0}-\boldsymbol{\mu_1})]^T=
w T ( μ 0 − μ 1 ) [ w T ( μ 0 − μ 1 ) ] T =
w
T
(
μ
0
−
μ
1
)
(
μ
0
−
μ
1
)
T
w
=
\boldsymbol w^T(\boldsymbol{\mu_0}-\boldsymbol{\mu_1})(\boldsymbol{\mu_0}-\boldsymbol{\mu_1})^T\boldsymbol w=
w T ( μ 0 − μ 1 ) ( μ 0 − μ 1 ) T w =
w
T
S
b
w
\boldsymbol w^TS_b\boldsymbol w
w T S b w
其中
S
b
S_b
S b 类间散布矩阵 :
S
b
=
(
μ
0
−
μ
1
)
(
μ
0
−
μ
1
)
T
S_b=(\boldsymbol{\mu_0}-\boldsymbol{\mu_1})(\boldsymbol{\mu_0}-\boldsymbol{\mu_1})^T
S b = ( μ 0 − μ 1 ) ( μ 0 − μ 1 ) T
S
b
S_b
S b
总结:最大化类间距离等同于最大化
w
T
S
b
w
\boldsymbol w^TS_b\boldsymbol w
w T S b w
类内距离尽可能小 :
X
0
和
X
1
X_0和X_1
X 0 和 X 1
x
x
x
w
T
x
\boldsymbol w^T\boldsymbol x
w T x 每个点到类的中心的距离的平方(一般都用距离的平方,不直接使用距离)之和 。
∑
x
∈
X
0
(
w
T
(
x
−
μ
0
)
)
2
=
∑
x
∈
X
0
w
T
(
x
−
μ
0
)
(
w
T
(
x
−
μ
0
)
)
T
=
\sum_{\boldsymbol x \in X_0}(\boldsymbol w^T(\boldsymbol x-\boldsymbol{\mu_0}))^2=\sum_{\boldsymbol x \in X_0}\boldsymbol w^T(\boldsymbol x-\boldsymbol{\mu_0})(\boldsymbol w^T(\boldsymbol x-\boldsymbol{\mu_0}))^T=
x ∈ X 0 ∑ ( w T ( x − μ 0 ) ) 2 = x ∈ X 0 ∑ w T ( x − μ 0 ) ( w T ( x − μ 0 ) ) T =
∑
x
∈
X
0
w
T
(
x
−
μ
0
)
(
x
−
μ
0
)
T
w
=
w
T
[
∑
x
∈
X
0
(
x
−
μ
0
)
(
x
−
μ
0
)
T
]
w
\sum_{\boldsymbol x \in X_0}\boldsymbol w^T(\boldsymbol x-\boldsymbol{\mu_0})(\boldsymbol x-\boldsymbol{\mu_0})^T\boldsymbol w=\boldsymbol w^T[\sum_{\boldsymbol x \in X_0}(\boldsymbol x-\boldsymbol{\mu_0})(\boldsymbol x-\boldsymbol{\mu_0})^T]\boldsymbol w
x ∈ X 0 ∑ w T ( x − μ 0 ) ( x − μ 0 ) T w = w T [ x ∈ X 0 ∑ ( x − μ 0 ) ( x − μ 0 ) T ] w
两个类总的类内距离的平方则是:
w
T
[
∑
x
∈
X
0
(
x
−
μ
0
)
(
x
−
μ
0
)
T
+
∑
x
∈
X
1
(
x
−
μ
1
)
(
x
−
μ
1
)
T
]
w
\boldsymbol w^T[\sum_{\boldsymbol x \in X_0}(\boldsymbol x-\boldsymbol{\mu_0})(\boldsymbol x-\boldsymbol{\mu_0})^T+\sum_{\boldsymbol x \in X_1}(\boldsymbol x-\boldsymbol{\mu_1})(\boldsymbol x-\boldsymbol{\mu_1})^T]\boldsymbol w
w T [ x ∈ X 0 ∑ ( x − μ 0 ) ( x − μ 0 ) T + x ∈ X 1 ∑ ( x − μ 1 ) ( x − μ 1 ) T ] w
定义类内散布矩阵 为:
S
w
=
S
0
+
S
1
S_w=S_0+S_1
S w = S 0 + S 1
其中
S
0
,
S
1
S_0,S_1
S 0 , S 1
S
0
=
∑
x
∈
X
0
(
x
−
μ
0
)
(
x
−
μ
0
)
T
S_0=\sum_{\boldsymbol x\in X_0 }(\boldsymbol x-\mu_0)(\boldsymbol x-\mu_0)^T
S 0 = x ∈ X 0 ∑ ( x − μ 0 ) ( x − μ 0 ) T
S
1
=
∑
x
∈
X
1
(
x
−
μ
1
)
(
x
−
μ
1
)
T
S_1=\sum_{\boldsymbol x\in X_1 }(\boldsymbol x-\mu_1)(\boldsymbol x-\mu_1)^T
S 1 = x ∈ X 1 ∑ ( x − μ 1 ) ( x − μ 1 ) T
总结起来,要最小化的两个类的总类内距离的平方 可进一步写为:
w
T
[
S
0
+
S
1
]
w
=
w
T
S
w
w
\boldsymbol w^T[S_0+S_1]\boldsymbol w=\boldsymbol w^TS_w\boldsymbol w
w T [ S 0 + S 1 ] w = w T S w w
有了前面两个概念作为基础,就可以进入最关键的能量函数推导了。
对(一)总结:
要最大化的类间距离:
w
T
S
b
w
\boldsymbol w^TS_b\boldsymbol w
w T S b w
w
T
S
w
w
\boldsymbol w^TS_w\boldsymbol w
w T S w w 能量函数 :
J
=
w
T
S
w
w
w
T
S
b
w
J=\frac{\boldsymbol w^TS_w\boldsymbol w}{\boldsymbol w^TS_b\boldsymbol w}
J = w T S b w w T S w w
看这个函数的形式,这就是广义瑞利商(genralized Rayleigh quotient),研一的矩阵理论课程里学的瑞利商的推广形式。所以LDA就转化为了
S
b
和
S
w
S_b和S_w
S b 和 S w
瑞利商定义:
R
(
A
,
x
)
=
x
H
A
x
x
H
x
R(A,x)=\frac{x^HAx}{x^Hx}
R ( A , x ) = x H x x H A x
A
H
=
A
A^H=A
A H = A
A
T
=
A
A^T=A
A T = A
λ
m
i
n
≤
x
H
A
x
x
H
x
≤
λ
m
a
x
λmin≤\frac{x^HAx}{x^Hx}≤λmax
λ m i n ≤ x H x x H A x ≤ λ m a x
x
H
x
=
1
x^Hx=1
x H x = 1
R
(
A
,
x
)
=
x
H
A
x
R(A,x)=x^HAx
R ( A , x ) = x H A x
广义瑞利商定义:
R
(
A
,
B
,
x
)
=
x
H
A
x
x
H
B
x
R(A,B,x)=\frac{x^HAx}{x^HBx}
R ( A , B , x ) = x H B x x H A x
x
=
B
−
1
/
2
y
,
x=B^{−1/2}y,
x = B − 1 / 2 y ,
x
H
B
x
=
y
H
(
B
−
1
/
2
)
H
B
B
−
1
/
2
y
=
y
H
B
−
1
/
2
B
B
−
1
/
2
y
=
y
H
y
x^HBx=y^H(B^{−1/2})^HBB^{−1/2}y=y^HB^{−1/2}BB^{−1/2}y=y^Hy
x H B x = y H ( B − 1 / 2 ) H B B − 1 / 2 y = y H B − 1 / 2 B B − 1 / 2 y = y H y
x
H
A
x
=
y
H
B
−
1
/
2
A
B
−
1
/
2
y
x^HAx=y^HB^{−1/2}AB^{−1/2}y
x H A x = y H B − 1 / 2 A B − 1 / 2 y
R
(
A
,
B
,
y
)
=
y
H
B
−
1
/
2
A
B
−
1
/
2
y
y
H
y
R(A,B,y)=\frac{y^HB^{−1/2}AB^{−1/2}y}{y^Hy}
R ( A , B , y ) = y H y y H B − 1 / 2 A B − 1 / 2 y
B
−
1
/
2
=
(
B
−
1
/
2
)
H
B^{−1/2}=(B^{−1/2})^H
B − 1 / 2 = ( B − 1 / 2 ) H
M
=
B
−
1
/
2
A
B
−
1
/
2
M=B^{−1/2}AB^{−1/2}
M = B − 1 / 2 A B − 1 / 2
R
(
A
,
B
,
y
)
=
y
H
M
y
y
H
y
R(A,B,y)=\frac{y^HMy}{y^Hy}
R ( A , B , y ) = y H y y H M y
B
−
1
/
2
B^{-1/2}
B − 1 / 2
B
1
/
2
B^{1/2}
B 1 / 2
B
−
1
A
B^{−1}A
B − 1 A
B
−
1
A
B^{−1}A
B − 1 A
B
−
1
A
B^{−1}A
B − 1 A
上面这段虽然长,但结论很简单 :
广义瑞利商
R
(
A
,
B
,
x
)
=
x
H
A
x
x
H
B
x
R(A,B,x)=\frac{x^HAx}{x^HBx}
R ( A , B , x ) = x H B x x H A x
B
−
1
A
B^{−1}A
B − 1 A
B
−
1
A
B^{−1}A
B − 1 A
so!!!
m
i
n
J
=
w
T
S
w
w
w
T
S
b
w
min\quad J=\frac{\boldsymbol w^TS_w\boldsymbol w}{\boldsymbol w^TS_b\boldsymbol w}
m i n J = w T S b w w T S w w
S
b
−
1
S
w
S_b^{-1}S_w
S b − 1 S w
w
w
w
所以还得继续想办法求
w
w
w
w
w
w
回到上面观察
S
b
,
S
w
S_b,S_w
S b , S w
w
w
w
再观察能量函数,分子分母都有
w
w
w
w
w
w
α
w
\alpha w
α w
J
J
J
w
w
w
那么比较技巧性的东西就来了。。。
w
w
w
m
i
n
J
=
w
T
S
w
w
,
s
.
t
.
w
T
S
b
w
=
1
min\quad J=\boldsymbol w^TS_w\boldsymbol w,s.t.\quad\boldsymbol w^TS_b\boldsymbol w=1
m i n J = w T S w w , s . t . w T S b w = 1
λ
\lambda
λ
L
(
w
,
λ
)
=
w
T
S
w
w
−
λ
(
w
T
S
b
w
−
1
)
L(w,\lambda)=\boldsymbol w^TS_w\boldsymbol w-\lambda(\boldsymbol w^TS_b\boldsymbol w-1)
L ( w , λ ) = w T S w w − λ ( w T S b w − 1 )
对
w
w
w
2
S
w
w
−
2
λ
S
b
w
=
0
2S_ww-2\lambda S_bw=0
2 S w w − 2 λ S b w = 0
S
w
w
=
λ
S
b
w
S_ww=\lambda S_bw
S w w = λ S b w 也就是说,矩阵
S
w
S_w
S w
S
b
S_b
S b
w
w
w
S
b
w
=
(
μ
0
−
μ
1
)
(
μ
0
−
μ
1
)
T
w
S_b\boldsymbol w=(\boldsymbol{\mu_0}-\boldsymbol{\mu_1})(\boldsymbol{\mu_0}-\boldsymbol{\mu_1})^T\boldsymbol w
S b w = ( μ 0 − μ 1 ) ( μ 0 − μ 1 ) T w
μ
0
−
μ
1
\boldsymbol{\mu_0}-\boldsymbol{\mu_1}
μ 0 − μ 1
S
w
w
S_ww
S w w
μ
0
−
μ
1
\boldsymbol{\mu_0}-\boldsymbol{\mu_1}
μ 0 − μ 1
S
w
S_w
S w
w
w
w
μ
0
−
μ
1
\boldsymbol{\mu_0}-\boldsymbol{\mu_1}
μ 0 − μ 1
S
w
−
1
S_w^{-1}
S w − 1
μ
0
−
μ
1
\boldsymbol{\mu_0}-\boldsymbol{\mu_1}
μ 0 − μ 1
w
w
w
不管
w
w
w
w
=
S
w
−
1
(
μ
0
−
μ
1
)
\boldsymbol w=S_w^{-1}(\boldsymbol{\mu_0}-\boldsymbol{\mu_1})
w = S w − 1 ( μ 0 − μ 1 )
求解完毕!!!!!开心!!
投影的方向只由
S
w
S_w
S w
在实际求解中,由于矩阵求逆很难,所以通常对
S
w
S_w
S w
S
w
=
U
Σ
V
T
S_w=U\Sigma V^T
S w = U Σ V T
S
w
−
1
=
V
Σ
−
1
U
T
S_w^{-1}=V\Sigma^{-1} U^T
S w − 1 = V Σ − 1 U T
这就很简单了。。
x
∗
x^*
x ∗
w
T
x
∗
\boldsymbol w^Tx^*
w T x ∗
判别数据点属于第0类还是第1类的阈值:
w
0
=
w
T
μ
0
+
w
T
μ
1
2
w_0=\frac{w^T\mu_0+w^T\mu_1}{2}
w 0 = 2 w T μ 0 + w T μ 1
或者
w
0
=
N
0
w
T
μ
0
+
N
1
w
T
μ
1
N
0
+
N
1
w_0=\frac{N_0w^T\mu_0+N_1w^T\mu_1}{N_0+N_1}
w 0 = N 0 + N 1 N 0 w T μ 0 + N 1 w T μ 1
我觉得第二种更加准确,毕竟考虑了两类样本数目的影响。
若
w
T
x
∗
>
w
0
\boldsymbol w^Tx^*>w_0
w T x ∗ > w 0
w
T
x
∗
<
w
0
\boldsymbol w^Tx^*<w_0
w T x ∗ < w 0
附注:
很多博客,包括老师课件都是把能量函数写成
J
=
w
T
S
b
w
w
T
S
w
w
J=\frac{\boldsymbol w^TS_b\boldsymbol w}{\boldsymbol w^TS_w\boldsymbol w}
J = w T S w w w T S b w
m
i
n
J
=
−
w
T
S
b
w
,
s
.
t
.
w
T
S
w
w
=
1
min \quad J=-\boldsymbol w^TS_b\boldsymbol w,\quad s.t.\boldsymbol w^TS_w\boldsymbol w=1
m i n J = − w T S b w , s . t . w T S w w = 1
再用拉格朗日乘子法,虽然和我的过程略有不同,但思想和结果是完全一样的。我仔细想了想,觉得两种应该都可以,大家在LDA问题都习惯于用最大化的能量函数可能因为从最开始就这样,不是因为我那样做是错的,因为根据物理意义,能量函数的分子分母都不可能为0,所以两种都正确。