本文将会介绍如何使用百度AI开放平台中的文字识别服务来识别图片中的文字。百度AI开放平台的访问网址为:http://ai.baidu.com/ ,为了能够使用该平台提供的AI服务,你需要事先注册一个百度账号。
创建百度AI文字识别应用
在百度AI开放平台中,登录自己的百度账号,点击“文字识别”服务中的“通用场景文字识别”,选择“创建应用”,填好应用名称,选择应用类型,填好应用描述,这样就创建好了“通用场景文字识别”服务,如下图:
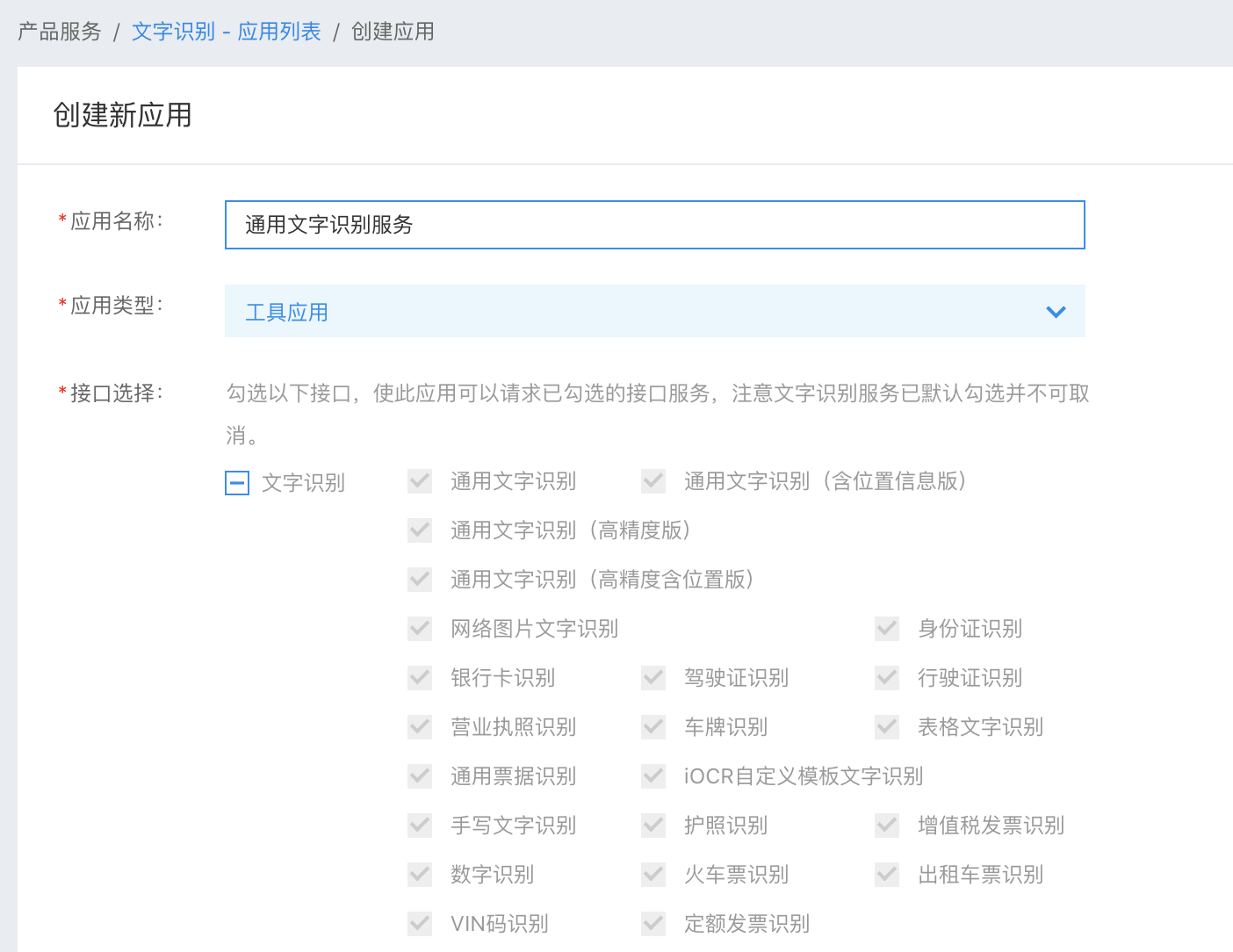
在应用列表中,能够看到自己刚刚创建好的文字识别服务了,记住,这个应用中的“AppID”,“API Key”,“Secret Key”很重要,是你这个应用的唯一识别。

OK,创建好这个应用后,我们就能使用该应用来识别图片中的文字了~
利用创建的应用来识别图片中的文字
接下来,我们将使用刚刚创建好的文字识别应用来识别图片中的文字,大致的步骤如下:
- 获取该应用的access_token;
- 利用access_token来创建HTTP请求;
- 解析请求成功后的json文件,获取识别后的结果。
具体的参考文档可以参考网址:https://ai.baidu.com/docs#/OCR-API/top, 本文将不再具体讲述。
我们需要识别的图片为含有两个汉字的图片验证码,图片名称为test.png,如下:
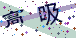
参考该应用的官方文档说明,我们写下如下的Python脚本,即可识别图片中的文字,完整的代码如下:
import json
import requests
import base64
import urllib.parse
APP_ID = '你的APP_ID'
API_KEY ='你的API_KEY'
SECRECT_KEY = '你的SECRECT_KEY'
# 获取token
url = 'https://aip.baidubce.com/oauth/2.0/token'
body = {'grant_type': 'client_credentials',
'client_id': API_KEY,
'client_secret': SECRECT_KEY
}
req = requests.post(url=url, data=body)
token = json.loads(req.content)['access_token']
# 获取百度api识别结果
ocr_url = 'https://aip.baidubce.com/rest/2.0/ocr/v1/general_basic?access_token=%s'%token
headers = {'Content-Type': 'application/x-www-form-urlencoded'}
# 读取图片并进行base64加密
body = base64.b64encode(open('./test.png' ,'rb').read())
# 进行urlencode
data = urllib.parse.urlencode({'image': body})
# post请求
r = requests.post(url=ocr_url, headers=headers, data=data)
# 输出请求结果
print('请求码为: %s' %r.status_code)
res_words = json.loads(r.content)['words_result'][0]['words']
print('识别结果为: %s' % res_words)输出的结果如下:
请求码为: 200
识别结果为: 高吸可以看到,对于这张图片,百度的文字识别功能很好地识别出了图片中的文字。
利用Python的百度文字识别第三方模块来识别图片中的文字
上面我们参照了百度文字识别的官方文档来实现文字识别功能,但过程有点复杂,需要先获取access_token,再构建HTTP请求才能使用。幸运的是,在Python的第三库中,已经有了能实现该功能的第三方模块,即baidu-aip,安装方式如下:
pip install baidu-aip利用这个第三方模块,我们能简洁快速地实现文字识别功能,示例的Python代码如下:
# 利用aip进行识别
from aip import AipOcr
APP_ID = '你的APP_ID'
API_KEY ='你的API_KEY'
SECRECT_KEY = '你的SECRECT_KEY'
client = AipOcr(APP_ID, API_KEY, SECRECT_KEY)
img = open('./test.png','rb').read()
message=client.basicGeneral(img)
res = message['words_result']
print('识别结果为: %s' % res[0]['words'])总结
本文并没有讲述如何从AI模型来识别图片中的文字,而是利用百度AI平台中的文字识别服务来完成文字识别任务。看上去并没有什么新意,只是讲解使用使用API来识别图片中的文字罢了。
那么,本文的意义在哪?其实,在使用模型识别文字前,一个很重要的过程便于标注,标注费时费力,这时候我们借助第三方文字识别API能够减轻标注的工作量,让我们的标注量能减少点。
当然,如果你把这篇文章看作是一个学习如何利用百度文字识别API识别图像中的文字的机会,那也未尝不可!
注意:本人现已开通微信公众号: Python爬虫与算法(微信号为:easy_web_scrape), 欢迎大家关注哦~~