百度API
百度API是百度提供的一套开放的应用程序接口,它允许开发者在百度的基础上构建应用程序,并通过百度的各种渠道进行推广和营销。百度API分为移动、Web、智能客服、数据、娱乐、传统IT六大类,共计200多个细分行业。
百度API的主要特点:
- 开放性:百度API不收取任何费用,开发者可以免费使用其中的功能,并可以根据自己的需求进行调用。
- 兼容性:百度API支持多种语言和框架,可以在多个平台上使用,包括Web、Android、iOS、Windows等。
- 安全性:百度API采用了多种安全措施,包括数据加密、身份验证等,保证了用户数据的安全性。
- 可靠性:百度API的稳定性和可靠性高,可以保证服务的持续性和稳定性。
- 灵活性:百度API提供了丰富的接口和功能,开发者可以根据自己的需求进行选择和组合,实现更加灵活和个性化的应用程序。
1.首先在百度智能云:https://cloud.baidu.com/注册开发者账号,然后如下图操作

2.点击立即使用进入控制台,然后去领取免费资源
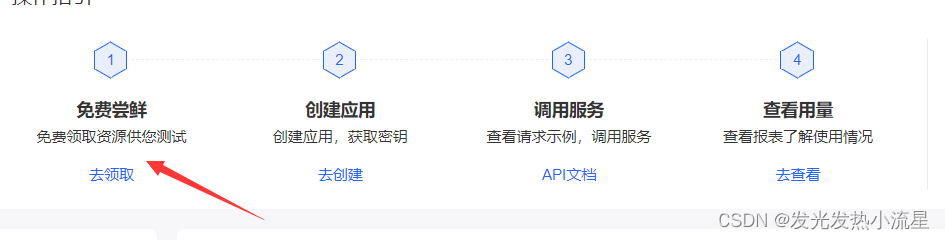
找到你想用的资源领取即可,这里我已经领过了

3.回到控制台点击去创建

4.然后按要求创建即可,这里注意之选你要用到的API

5.创建完成后可以在控制台公有云服务的应用列表里看到
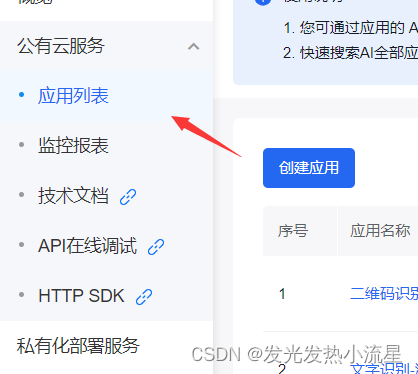
6.你可以在选择API在线调试,在这里我教大家在本地使用python调用API来识别图片文字
首先是获取鉴权认证机制,这里我们需要用到你创建的API的AK和SK,将其复制下来备用。
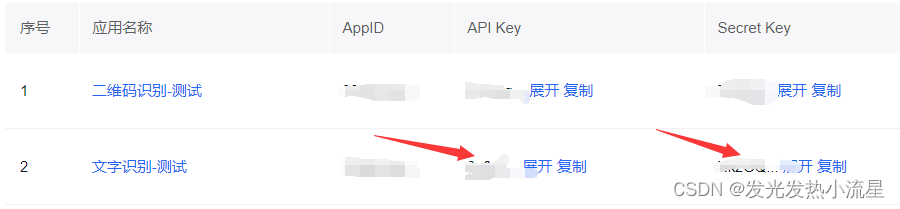
7. 将AK和SK输入到代码中***出,点击运行即可获得AccessToken
import requests
import json
def main():
url = "https://aip.baidubce.com/oauth/2.0/token?client_id=***&client_secret=***&grant_type=client_credentials"
payload = ""
headers = {
'Content-Type': 'application/json',
'Accept': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
print(response.json()['access_token'])
if __name__ == '__main__':
main()
8.另创一个文件,用于识别图片。将AccessToken代码中的*****。
import base64
import urllib
import requests
import os
def main():
#从鉴权人证获取access_token
url = "https://aip.baidubce.com/rest/2.0/ocr/v1/general_basic?access_token=******************"
img=get_file_content_as_base64('./a.jpg')
payload = {"image":img}
headers = {
'Content-Type': 'application/x-www-form-urlencoded',
'Accept': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
def get_file_content_as_base64(path, urlencoded=False):
"""
获取文件base64编码
:param path: 文件路径
:param urlencoded: 是否对结果进行urlencoded
:return: base64编码信息
"""
with open(path, "rb") as f:
content = base64.b64encode(f.read()).decode('utf-8')
if urlencoded:
content = urllib.parse.quote_plus(content)
return content
if __name__ == '__main__':
main()9.最后将你要识别的图片放到同级文档下,换一下名字即可识别文字
如果想要实现批量图片识别与保存,请一键三连后私聊发送。