0. 前言:百度OCR文字识别简介
百度OCR文字识别是百度公司推出的一项智能化服务,通过使用人工智能技术,能够将图片中的文字内容识别出来并转化为可编辑的文字格式。
该服务可以应用在多个领域,例如身份证、银行卡、营业执照等各种证件的识别,车牌号码的识别,图片中的条形码和二维码的识别等等。
百度OCR文字识别具有以下特点:
-
高准确率:采用多层次深度神经网络,具有较高的文字识别准确率。
-
多语言支持:支持包括中文、英文、日文、韩文等多种语言的文字识别。
-
图片处理功能:对于拍摄环境较差、模糊或倾斜的图片,可以通过对图像的预处理来提高文字识别的准确率。
-
丰富的场景支持:支持不同领域的文字识别,包括证件、车牌、二维码、票据等。
-
多平台支持:提供基于 API 接口的服务,可以方便地集成到各种应用平台上,例如网页、移动端应用等。
百度OCR文字识别的应用场景非常广泛,可以应用在各行各业中。

在金融行业,可以用于快速识别银行卡、身份证等证件信息;
在物流行业,可以用于识别快递单上的运单号码;
在零售行业,可以用于识别商品条形码等。
通过文字识别技术,可以大大提高工作效率和准确性,减少了人工操作的成本和风险。
百度OCR文字识别是一项领先的人工智能技术,在文字识别和处理方面具有极高的准确性和可靠性,为各个行业的数字化转型和智能化应用提供了有力的支持。
操作系统:Windows10 家庭版
开发环境:Pycahrm Comunity 2022.3
Python解释器版本:Python3.8
1. 领取免费识别模型
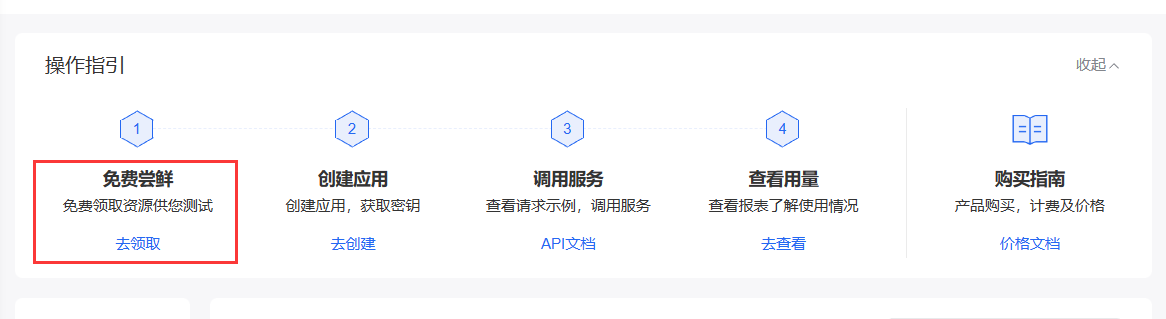
去这个地方注册免费账号
百度文字识别
点击立即使用
去领取
不要领取全部,有些是含有效期的,领完不一定用很浪费
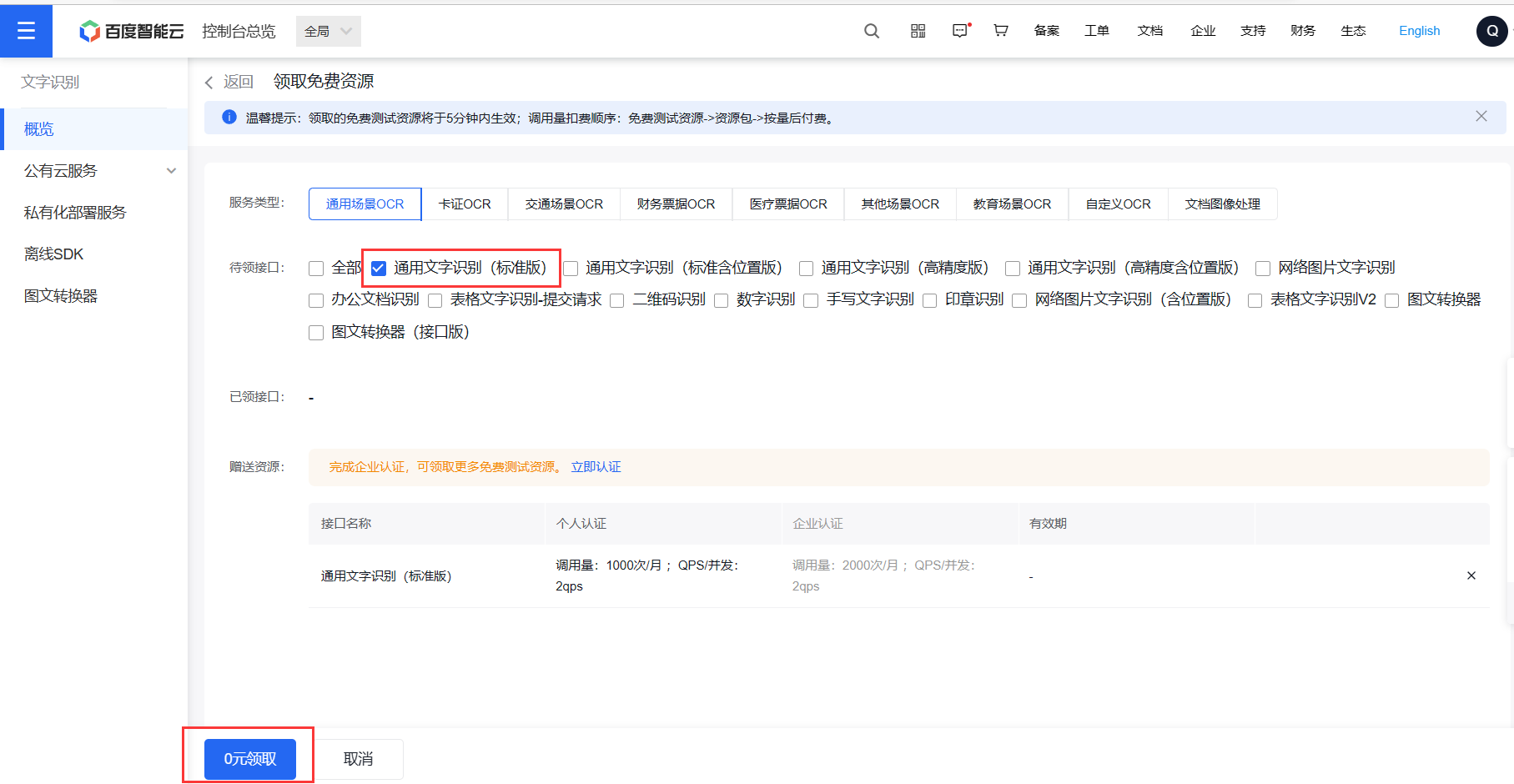
我剩下没有选择的都是365天使用限制的
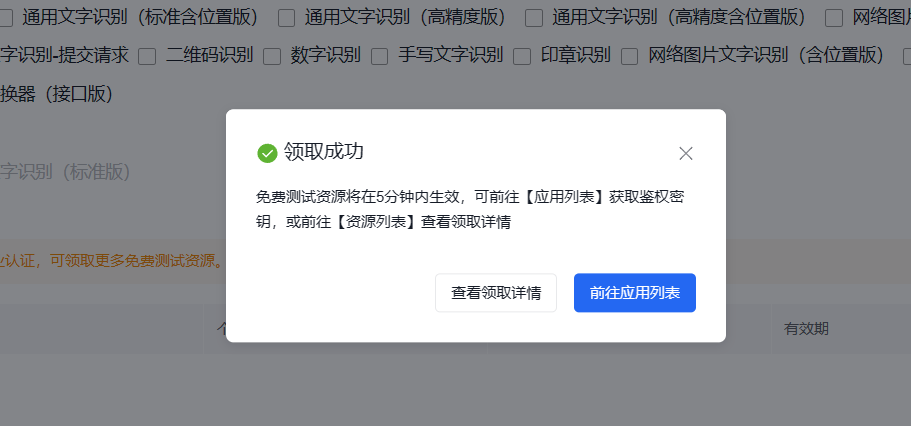
领取成功
2. 创建实例
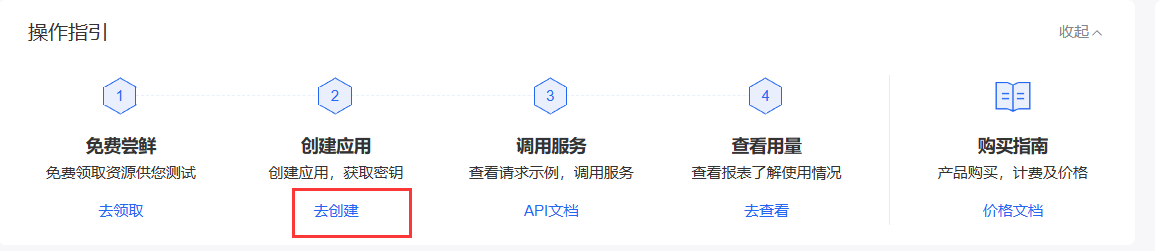
去创建
选择个人归属,然后立即创建
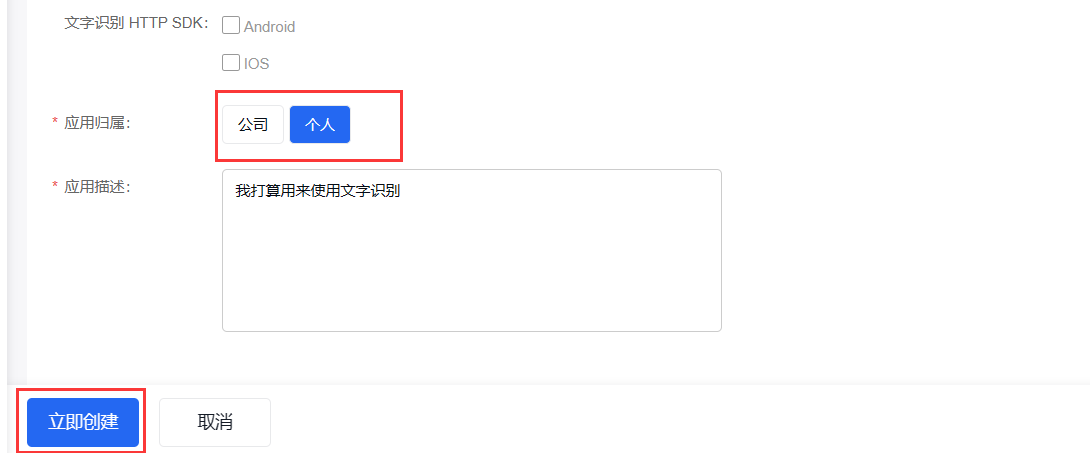
然后这个页面先不要关,到时候有用

你可以在这查看API文档,学习如何使用

3. 代码测试
现在我们来进行使用,以下是官方Demo,你只需要替换自己的APIkey和Secretkey就好了:
main.py
# coding=utf-8
import sys
import json
import base64
# 保证兼容python2以及python3
IS_PY3 = sys.version_info.major == 3
if IS_PY3:
from urllib.request import urlopen
from urllib.request import Request
from urllib.error import URLError
from urllib.parse import urlencode
from urllib.parse import quote_plus
else:
import urllib2
from urllib import quote_plus
from urllib2 import urlopen
from urllib2 import Request
from urllib2 import URLError
from urllib import urlencode
# 防止https证书校验不正确
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
API_KEY = '换成你自己的'
SECRET_KEY = '换成你自己的'
OCR_URL = "https://aip.baidubce.com/rest/2.0/ocr/v1/accurate_basic"
""" TOKEN start """
TOKEN_URL = 'https://aip.baidubce.com/oauth/2.0/token'
"""
获取token
"""
def fetch_token():
params = {
'grant_type': 'client_credentials',
'client_id': API_KEY,
'client_secret': SECRET_KEY}
post_data = urlencode(params)
if (IS_PY3):
post_data = post_data.encode('utf-8')
req = Request(TOKEN_URL, post_data)
try:
f = urlopen(req, timeout=5)
result_str = f.read()
except URLError as err:
print(err)
if (IS_PY3):
result_str = result_str.decode()
result = json.loads(result_str)
if ('access_token' in result.keys() and 'scope' in result.keys()):
if not 'brain_all_scope' in result['scope'].split(' '):
print ('please ensure has check the ability')
exit()
return result['access_token']
else:
print ('please overwrite the correct API_KEY and SECRET_KEY')
exit()
"""
读取文件
"""
def read_file(image_path):
f = None
try:
f = open(image_path, 'rb')
return f.read()
except:
print('read image file fail')
return None
finally:
if f:
f.close()
"""
调用远程服务
"""
def request(url, data):
req = Request(url, data.encode('utf-8'))
has_error = False
try:
f = urlopen(req)
result_str = f.read()
if (IS_PY3):
result_str = result_str.decode()
return result_str
except URLError as err:
print(err)
if __name__ == '__main__':
# 获取access token
token = fetch_token()
# 拼接通用文字识别高精度url
image_url = OCR_URL + "?access_token=" + token
text = ""
# 读取测试图片
file_content = read_file('./text.png')
# 调用文字识别服务
result = request(image_url, urlencode({
'image': base64.b64encode(file_content)}))
# 解析返回结果
result_json = json.loads(result)
for words_result in result_json["words_result"]:
text = text + words_result["words"]
# 打印文字
print(text)
这个是我的图片:
text.png
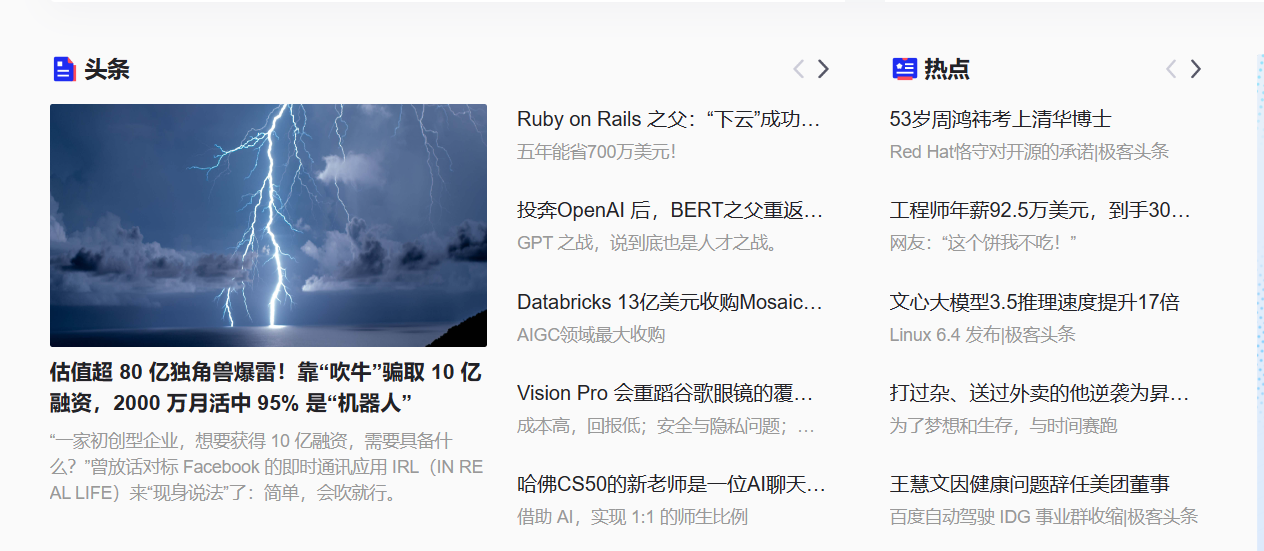
4. 识别结果
下面我们来看识别结果,就这样咯:
