这里讨论的问题是如何减少模型的过度拟合。一般地,对模型加上约束,也就是正则化,它的自由度越低,就越不容易过度拟合数据,比如对多项式模型来说,减低多项式模型的阶数就是一种正则化。正则化是一类方法,不是具体的某种方法。
对线性模型来说,通常通过约束模型的权重来实现正则化。对权重进行约束的方法有岭回归(Ridge Regression)、套索回归(Lasso Regression)和弹性网络(Elastic Net)。
在线性化模型中加入正则项![]() ,就是线性模型的正则化版,正则化模型不但要对数据进行拟合,还要使权重保持最小。正则项只能在训练时添加到成本函数中,一旦训练完成,就要使用不同的性能指标对模型进行评价。训练和和测试时使用不同的性能指标是很常见的事,比如训练时使用的是成本函数,测试时却是精度/召回率指标,一个原因是测试用的性能指标要尽可能地接近终极目标。
,就是线性模型的正则化版,正则化模型不但要对数据进行拟合,还要使权重保持最小。正则项只能在训练时添加到成本函数中,一旦训练完成,就要使用不同的性能指标对模型进行评价。训练和和测试时使用不同的性能指标是很常见的事,比如训练时使用的是成本函数,测试时却是精度/召回率指标,一个原因是测试用的性能指标要尽可能地接近终极目标。
超参数α控制的是对模型进行正则化的程度,α等于0,就得到线性模型;α非常大则每个权重都非常接近于0,得到是一条穿过数据平均值的直线。
岭回归成本函数
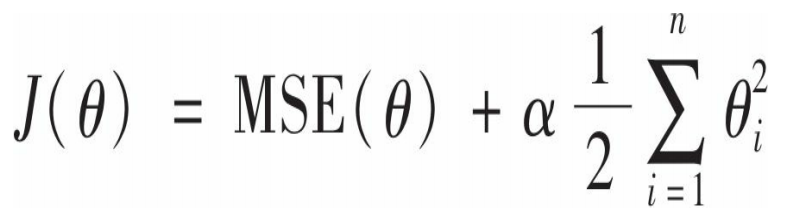
注意这里从i= 1开始而不是i=0,因此theta 0 没有正则化。并且,在执行岭回归之前必须对特征进行缩放,因为它对输入特征的大小非常敏感,大多数正则化模型都是如此。
也可以在计算闭式方程或梯度下降中使用正则化:
![]()
其中A是一个单位矩阵,当然左上角的元素为0,因为偏置项不应当被正则化。
套索回归--最小绝对收缩和选择算子回归
其与岭回归的区别在于正则项是L1范数
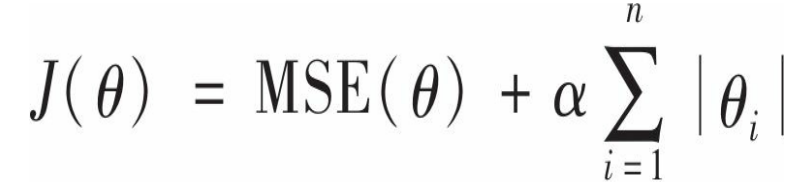
Lasso回归的一个重要特性是,它倾向于完全消除最不重要的特征,就是说将对应的权重设置为0.这也就是说Lasso回归会自动执行特征选择并输出一个稀疏矩阵,只有很少部分的特征有非零权重。

左图是直接对数据lasso回归,右图是先对数据特征进行扩展,使用用PolynomialFeatures(degree=10),然后对数据进行缩放StandardScaler,再执行lasso回归。从右图可以看出虚线看起来像是二次的,却接近直线,因为正则项使得不重要的权重为0。下图是岭回归执行于经过相同处理的数据集上的结果:
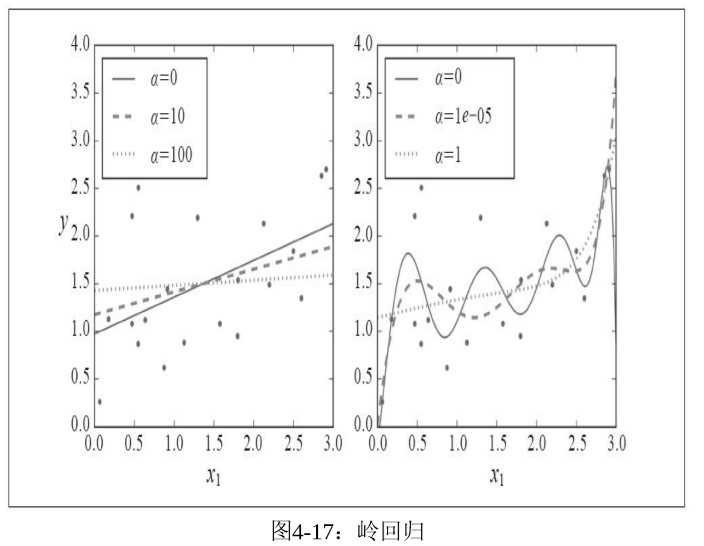
两幅图的左子图差别不大,右子图差别最大的就是黑线段,lasso回归的中的黑线段更接近线性,这是因为高阶的权重被置为0.
这里还有一些问题,当时θi=0(i=1,2,…,n),Lasso成本函数是不可微的,但 是,当任意θi=0时,如果使用次梯度向量作为替代,依旧可以让 梯度下降正常运转

这里不作深入讨论,当实际使用碰到问题时在深入研究吧。
弹性网络
这是岭回归和lasso回归的中间地带,结合体。这种策略在很多地方都会出现,这是一个好的想法,只要在数学理论上有了坚实的基础,便会能够有它自己的一席之地。
显而易见,它的正则项就是岭回归的正则项和lasso正则项的混合:
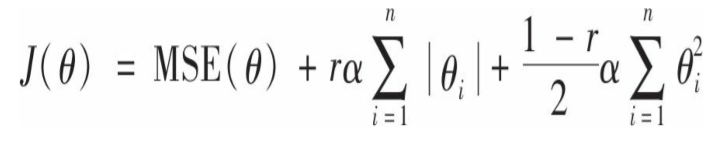
这里所有的权重之和应当为1,这就是最后一项的系数的来由。
那么,聪明的人们应当如何选择这三种方法呢?一般来说,有正则总比没有正则化好,因此,应当尽量避免使用纯线性回归。岭回归通常是个不错的默认选择。但是,当你认为只用到少数的几个特征时,应当选择lasso,因为它将无用的特征的权重降为0.一般而言,弹性网络优于lasso,尤其是当特征数大于实例数量或是几个特征强相关时,lasso可能非常不稳定。
美丽的免费午餐
早期停止法 对于梯度下降这一类学习算法,有一个常用又好用的方法,就是在训练误差达到最小的时候停止训练。随着迭代的进行,模型在训练集上的预测误差越来越小,其在验证集上的预测误差也随之下降。但是,经过一轮又一轮的训练后,模型的验证误差不再下降反而上升,这是模型开始过度拟合的信号,我们应当在这时候停止训练,这就是早期停止法。有大牛也称之为“美丽的免费午餐”。虽然这样做并没有绝对的理论基础来保证绝对正确,但它在大多数情况下还是非常实用的技巧。
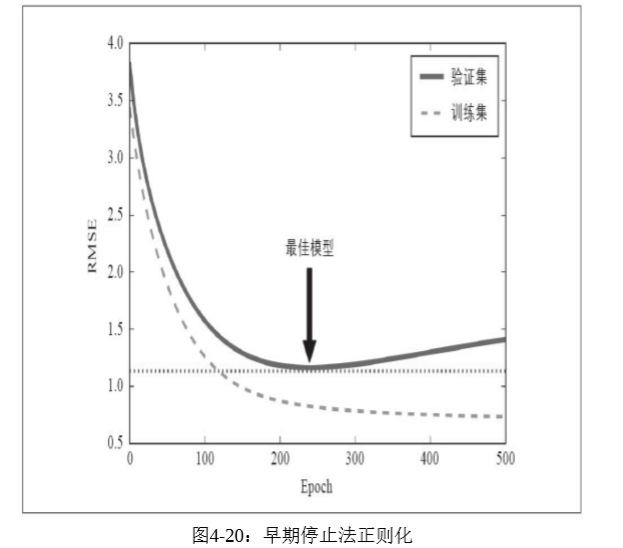
对于随机梯度和小批量下降来说,曲线不会这么平滑,会有一些震荡,所以很难知道是否已经到达最小值,此时可以在超过最小误差之后一段时间再停止,然后回滚到验证误差最小的位置。
逻辑回归(logistic回归)
不要别这个名字本身骗了,它和逻辑没啥关系。逻辑回归在前面是被用来作为回归预测的,现在也可以用来作为分类预测,要达到这样的效果,只需要进行一些转换。在逻辑回归模型中,我们输入特征数据,输出的是权重与特征乘积之和(加上偏置项),现在,我们得到这个和之后,并不直接输出,而是用以下函数进行概率估算:
![]()
这是向量形式,theta是权重向量,x是特征向量。这样我们就得到了每个实例对应的一个概率值,这个概率值用来做什么呢?假如我们认为一个实例为正类时,它对应的概率值为1,负类为0(理性情况),但既然是概率我们就应当允许有中间地带,而不是非0即1.那么一个正类的概率应当尽量接近1,负类的概率尽量接近0,有了这样的想法,一些聪明人就用以下的sigmoid函数来实现这样的想法:
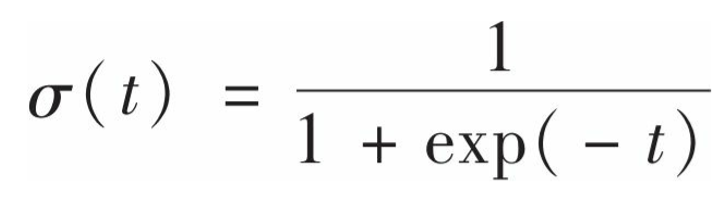
它的图像是这样的:
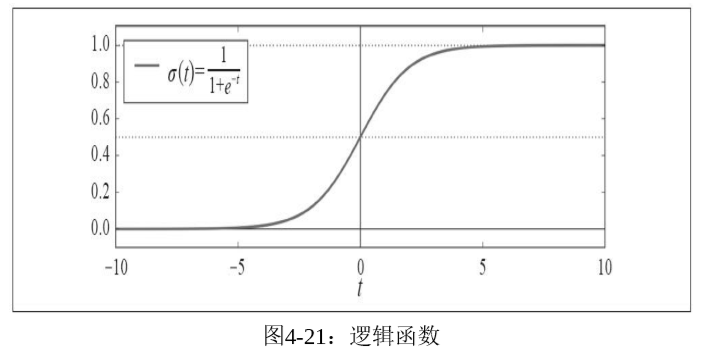
逻辑函数的参数t对应的就是权重与特征乘积之和(加上偏置项),或者说就是预测输出值。将预测值作为参数输入逻辑函数,函数的输出就是概率。根据上面的想法,我们定义出最终输出结果的规则:
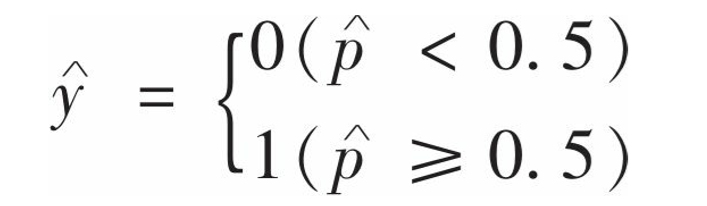
当概率小于0.5时,将实例归为负类,否则归为正类,但模型输出的是1或0,1表示正类,0表示负类,所以有需求要的时候还需要转换正类别。
那么,该如何训练这个模型呢?所谓训练模型就是该如何设置theta的值呢?合理的theta应当是使得对正类作出高概率估算,负类则相反。考虑一下单个实例的成本函数:
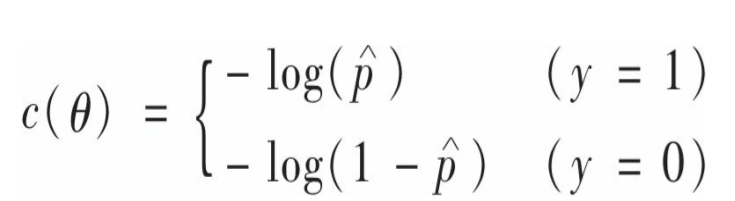
当p接近于0是,-log(p)非常大,也就是说如果模型将一个正类的概率估算为0时,成本函数会非常大;当p接近于1时-log(1-p)非常大,也就是说模型将负类作出高概率估算时,也会导致成本函数很大。因此,错误的分类会被惩罚。相反地,当正类的p接近于1时,成本接近于0,当负类的p接近于0时,成本也为0.这正是我们想要的。注意,计算模型的成本函数是,其实是和实例原始类别相联系的,并且类比不同,成本计算不同,其实是个分段函数。基于以上单个实例的成本函数,可以得到以下整个训练集的成本函数:

这里实现的是一个分段函数的功能,当y=1时,取左侧。
坏消息是这个成本函数没有已知的闭式方程来求解,也就是说没有相等的标准方程与之对应。好消息是它是一个凸函数,意味着可以使用梯度下降的方法来迭代求解。偏导数为:
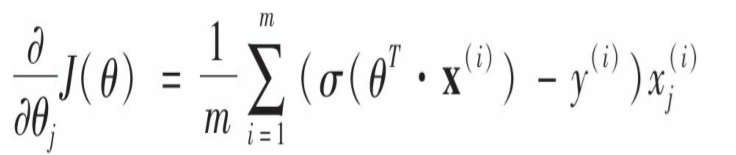
它计算每个实例的预测误差,并简单地乘以第j个特征,然后求平均值。有了偏导数就可以使用梯度下降了。
决策边界
在决策边界的两侧,实例被划分为不同的类别,在这里,决策边界就是就是程θ0+θ1x1+θ2x2=0的点x的集合(假设有2个特征)。
Softmax回归
逻辑回归的推广形式,可以支持多元分类,不过要注意的是它每次只能输出一个类别。多元逻辑回归的原理:对于每个实例x,softmax首先计算 每个类别k的分数sk:
![]()
这里,每个类比都有自己的theta。得到实例在每个类别k的分数后,用softmax计算分数:计算每个分数的指数,然后除以进行归一化处理,其含义是实例属于类别k的概率。
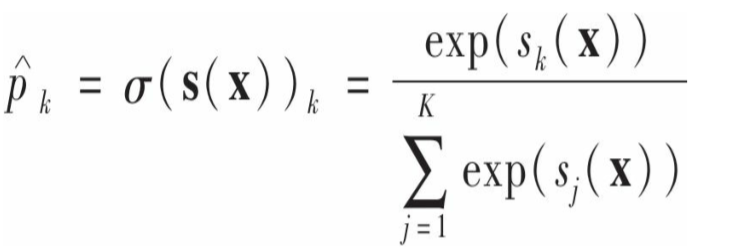
softmax回归分类器也是将估算概率最高的类别作为预测类别:
![]()
argmax()返回使得分数最大的k。
softmax是多类别但不是多输出,因此只能用于类别互斥的场合 。
接下来,训练模型,定义交叉熵:
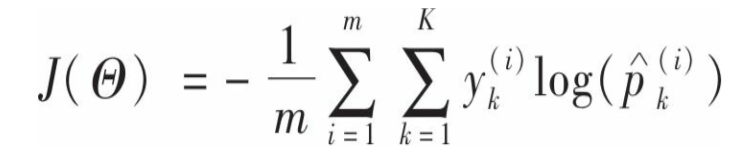
当第i个实例的目标类别(也就是原始类别)为k是 y才为0,否则为0.m是实例个数,k为类别数。当k=2时,也就是只有两个类别时,这个成本函数与logistic成本函数等价(差个系数)。交叉熵对于类别k的偏导数:
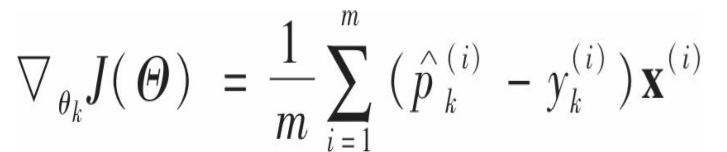
有了偏导数就可以使用梯度下降方法来迭代训练。
对于softmax多类别分类器,其决策边界都是线性的,因为有多个类别,因此在类别之间存在多个决策边界,在所有边界交汇处,所有类别的概率都相等,这个概率是有可能小于50%的,(当k=3时,交汇处属于每个类别的概率都是33%),这时有别于logistic回归分类的。