利用决策树预测泰坦尼克号乘客的生存率
数据集来源:https://github.com/cystanford/Titanic_Data
主要包括两部分数据:训练集train.csv 和测试集 test.csv
运用sklearn中运用DecisionTreeClassifier 分类器来进行预测
到目前为止,sklearn 中只实现了 ID3 与 CART决策树,
在构造 DecisionTreeClassifier 类时,其中有一个参数是 criterion,意为标准。它决定了构造的分类树是采用 ID3 分类树,还是 CART分类树,对应的取值分别是 entropy 或者 gini:
- entropy: 基于信息熵,也就是 ID3 算法实际结果与 C4.5 相差不大;
- gini:默认参数,基.于基尼系数。CART 算法是基于基尼系数做属性划分的,所以criterion=gini 时,实际上执行的是 CART决策树
在这里创建的是 ID3 分类树。
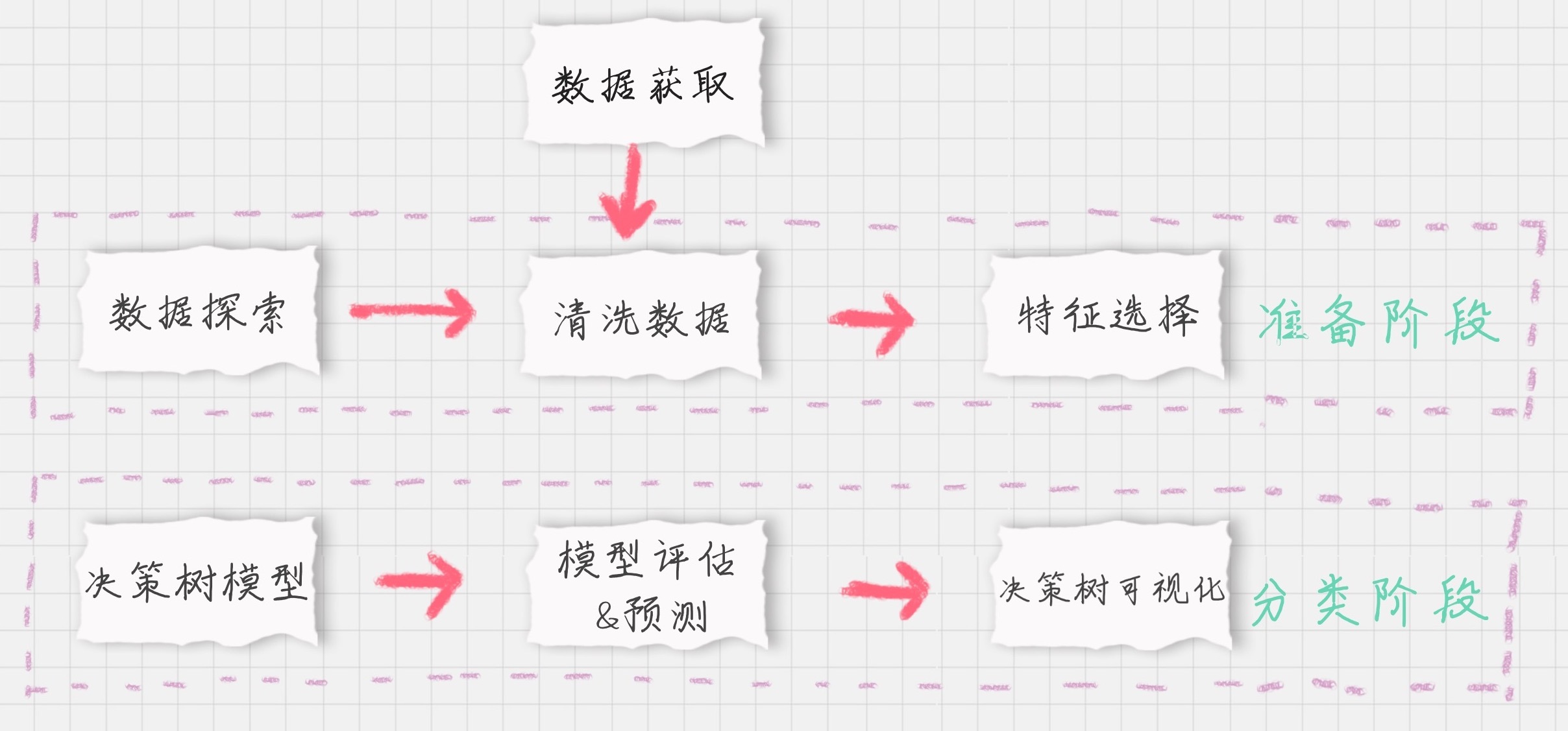
该预测模型预测过程可用下图进行描述
# -*- coding: utf-8 -*-
"""
Created on Thu Mar 14 14:33:16 2019
@author: Administrator
"""
#利用决策树的方法预测泰坦尼克号乘客的生存率
from sklearn.tree import DecisionTreeClassifier
import pandas as pd
from sklearn.feature_extraction import DictVectorizer
#1 数据探索
#读取CSV 文件
train_data=pd.read_csv(r'F:\lhy\train.csv')
test_data=pd.read_csv(r'F:\lhy\test.csv')
#查看数据表的基本信息
print('-'*30)
print(test_data)
print('-'*100)
print(train_data.describe()) # 查看数据表的基本信息包括总和,平均值,标准差,最大值和最小值
print('-'*100)
print(train_data.info()) #查看属性信息
print('-'*100)
print(train_data.head()) #输出前五
print('-'*100)
print(train_data.tail())#输出后五
print('-'*100)
print(train_data.describe(include=['O'])) #查看数据表中的字符串类型的情况
#2 清晰数据,把属性缺失的项用均值或最大值进行填充
train_data['Age'].fillna(train_data['Age'].mean(),inplace=True) #true 表示在原来的基础上填补
test_data['Age'].fillna(test_data['Age'].mean(),inplace=True) #true 表示在原来的基础上填补
train_data['Fare'].fillna(train_data['Fare'].mean(),inplace=True) #true 表示在原来的基础上填补
test_data['Fare'].fillna(test_data['Fare'].mean(),inplace=True) #true 表示在原来的基础上填补
print(train_data['Embarked'].value_counts())
train_data['Embarked'].fillna('S',inplace=True) #true 表示在原来的基础上填补
test_data['Embarked'].fillna('S',inplace=True) #true 表示在原来的基础上填补
# 3特征选择,选择影响乘客生存率的特征组成特征向量
features=['Pclass','Sex','Age','SibSp','Parch','Fare','Embarked']
train_features=train_data[features]
train_labels=train_data['Survived']
test_features=test_data[features]
#转换成特征矩阵
dvec=DictVectorizer(sparse=False)
train_features=dvec.fit_transform(train_features.to_dict(orient='record'))
print(dvec.feature_names_)
#4 创建ID3决策树
clf=DecisionTreeClassifier(criterion='entropy')
test_features=dvec.fit_transform(test_features.to_dict(orient='record'))
clf.fit(train_features,train_labels)
test_predict=clf.predict(test_features)
# 5得到决策树准确率
acc_decision_tree = clf.score(train_features, train_labels)
print('score 准确率为 %.4lf' % acc_decision_tree)
print(test_predict)
#k折交叉验证,统计决策树准确率,提高正确率
from sklearn.model_selection import cross_val_score
import numpy as np
print(u'cross_val_score 准确率为 %.4lf' % np.mean(cross_val_score(clf, train_features, train_labels, cv=10)))
from sklearn import tree
#6 实现决策树的可视化
import graphviz
dot_data = tree.export_graphviz(clf, out_file=None)
graph = graphviz.Source(dot_data)
graph.view()