概述
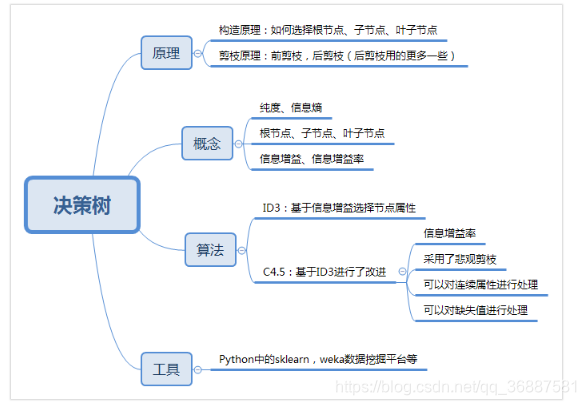
决策树是数据挖掘经典算法,既可以做分类,又可以做回归。下面介绍决策树的基本概念和相关术语,算法方面讲解ID3、C4.5、CART算法,并阐述各自的特点及其使用场景,最后用典型案例“泰坦尼克生存”作为实战,过程中会介绍模型评价机制和相关方法。
基本概念

一个完整的决策树会经历:构造、剪枝两个过程。
构造
构造的过程就是选择什么属性作为节点的过程,那么在构造过程中,会存在三种节点:根节点、节点、叶节点。
节点之间存在父子关系。比如根节点会有子节点,子节点会有子子节点,但是到了叶节点就停止了,叶节点不存在子节点。那么在构造过程中,你要解决三个重要的问题:
- 选择哪个属性作为根节点 。
- 选择哪些属性作为子节点 。
- 什么时候停止并得到目标状态,即叶节点。
实际上最重要的是选择根节点的方法,如果能有一种“方法“确定根节点,那么这个方法就可以应用到子节点。后面主要讲的就是这个“方法”也就是上面提到的三个算法。
剪枝
一个决策树构造出来并没有结束,还需要对其进行“修剪”,目的是防止过拟合,是使得模型拥有较好的泛化能力。
过拟合:模型的训练结果过好,以至于在实际应用的过程中,会存在“死板”的情况,导致分类错误,就像第三幅图一样,第一幅图是与之相反的欠拟合。跳出模型想一下,类别之间从大方向上是存在某种可以量化的区别的,那么他们之间的“区别=“区分曲线”是不会那么刁钻的,应该是相对比较“通用”或者说是相对“光滑圆润”

一般来说,剪枝可以分为“预剪枝”(Pre-Pruning)和“后剪枝”(Post-Pruning)。
预剪枝:在决策树构造时就进行剪枝。方法是在构造的过程中对节点进行评估,如果对某个节点进行划分,在验证集中不能带来准确性的提升,那么对这个节点进行划分就没有意义,这时就会把当前节点作为叶节点,不对其进行划分。应用比较少,一般在建模之前,我们会主观确定需要拟合的变量,把意义不大的或者数据质量不好的排除。
后剪枝:在生成决策树之后再进行剪枝,通常会从决策树的叶节点开始,逐层向上对每个节点进行评估。如果剪掉这个节点子树,与保留该节点子树在分类准确性上差别不大,或者剪掉该节点子树,能在验证集中带来准确性的提升,那么就可以把该节点子树进行剪枝。方法是:用这个节点子树的叶子节点来替代该节点,类标记为这个节点子树中最频繁的那个类。也就是把频率最高的情况当作是这个分类的唯一情况。
算法
C4.5是ID3的改进,应用很广泛,CART可以用于分离和回归,前两者只能应用于分类。
相关概念
熵:它表示了信息的不确定度
计算信息熵的数学公式:

p(i|t) 代表了节点 t 为分类 i 的概率,其中 log2 为取以 2 为底的对数。这里我们不是来介绍公式的,而是说存在一种度量,它能帮我们反映出来这个信息的不确定度。当不确定性越大时,它所包含的信息量也就越大,信息熵也就越高。不理解没关系,后面会带入数据。
ID3
ID3 算法计算的是信息增益,信息增益指的就是划分可以带来纯度的提高,信息熵的下降。它的计算公式,是父亲节点的信息熵减去所有子节点的信息熵。在计算的过程中,我们会计算每个子节点的归一化信息熵,即按照每个子节点在父节点中出现的概率,来计算这些子节点的信息熵。所以信息增益的公式可以表示为:
公式中 D 是父亲节点,Di 是子节点,Gain(D,a) 中的 a 作为 D 节点的属性选择。 比如针对图上这个例子,D 作为节点的信息增益为:
比如针对图上这个例子,D 作为节点的信息增益为:
假如我们的训练集数据如下:

我们基于 ID3 的算法规则,完整地计算下我们的训练集,训练集中一共有 7 条数据,3 个打篮球,4 个不打篮球,所以根节点的信息熵是:

如果你将天气作为属性的划分,会有三个叶子节点 D1、D2 和 D3,分别对应的是晴天、阴天和小雨。我们用 + 代表去打篮球,- 代表不去打篮球。那么第一条记录,晴天不去打篮球,可以记为 1-,于是我们可以用下面的方式来记录 D1,D2,D3:
D1(天气 = 晴天)={1-,2-,6+}
D2(天气 = 阴天)={3+,7-}
D3(天气 = 小雨)={4+,5-}
我们先分别计算三个叶子节点的信息熵:

那么作为子节点的归一化信息熵 = 3/70.918+2/71.0+2/7*1.0=0.965。
所以天气作为属性节点的信息增益为,Gain(D , 天气)=0.985-0.965=0.020。
同理我们可以计算出其他属性作为根节点的信息增益,它们分别为 :
Gain(D , 温度)=0.128
Gain(D , 湿度)=0.020
Gain(D , 刮风)=0.020
我们能看出来温度作为属性的信息增益最大。因为 ID3 就是要将信息增益最大的节点作为父节点,这样可以得到纯度高的决策树,所以我们将温度作为根节点。其决策树状图分裂为下图所示:

然后我们要将上图中第一个叶节点,也就是 D1={1-,2-,3+,4+}进一步进行分裂,往下划分,计算其不同属性(天气、湿度、刮风)作为节点的信息增益,可以得到:
Gain(D , 湿度)=1
Gain(D , 天气)=1
Gain(D , 刮风)=0.3115
我们能看到湿度,或者天气为 D1 的节点都可以得到最大的信息增益,这里我们选取湿度作为节点的属性划分。同理,我们可以按照上面的计算步骤得到完整的决策树,结果如下:

于是我们通过 ID3 算法得到了一棵决策树。ID3 的算法规则相对简单,可解释性强。同样也存在缺陷,比如我们会发现 ID3 算法倾向于选择取值比较多的属性。这样,如果我们把“编号”作为一个属性(一般情况下不会这么做,这里只是举个例子),那么“编号”将会被选为最优属性 。但实际上“编号”是无关属性的,它对“打篮球”的分类并没有太大作用。
所以 ID3 有一个缺陷就是,有些属性可能对分类任务没有太大作用,但是他们仍然可能会被选为最优属性。这种缺陷不是每次都会发生,只是存在一定的概率。在大部分情况下,ID3 都能生成不错的决策树分类。针对可能发生的缺陷,后人提出了新的算法进行改进。
C4.5
C4.5 在ID3的基础上进行了改进,避免了上述的情况。
- 采用信息增益率
因为 ID3 在计算的时候,倾向于选择取值多的属性。为了避免这个问题,C4.5 采用信息增益率的方式来选择属性。信息增益率 = 信息增益 / 属性熵,具体的计算公式这里省略。当属性有很多值的时候,相当于被划分成了许多份,虽然信息增益变大了,但是对于 C4.5 来说,属性熵也会变大,所以整体的信息增益率并不大。 - 采用悲观剪枝
ID3 构造决策树的时候,容易产生过拟合的情况。在 C4.5 中,会在决策树构造之后采用悲观剪枝(PEP),这样可以提升决策树的泛化能力。悲观剪枝是后剪枝技术中的一种,通过递归估算每个内部节点的分类错误率,比较剪枝前后这个节点的分类错误率来决定是否对其进行剪枝。这种剪枝方法不再需要一个单独的测试数据集。 - ※离散化处理连续属性
C4.5 可以处理连续属性的情况,对连续的属性进行离散化的处理。比如打篮球存在的“湿度”属性,不按照“高、中”划分,而是按照湿度值进行计算,那么湿度取什么值都有可能。该怎么选择这个阈值呢,C4.5 选择具有最高信息增益的划分所对应的阈值。 - 处理缺失值
针对数据集不完整的情况,C4.5 也可以进行处理。 假如数据集如下:
我们不考虑缺失的数值,可以得到温度 D={2-,3+,4+,5-,6+,7-}。温度 = 高:D1={2-,3+,4+} ;温度 = 中:D2={6+,7-};温度 = 低:D3={5-} 。这里 + 号代表打篮球,- 号代表不打篮球。比如 ID=2 时,决策是不打篮球,我们可以记录为 2-。
Gain(D′, 温度)=Ent(D′)-0.792=1.0-0.792=0.208
属性熵 =1.459, 信息增益率 Gain_ratio(D′, 温度)=0.208/1.459=0.1426。
D′的样本个数为 6,而 D 的样本个数为 7,所以所占权重比例为 6/7,所以:
Gain_ratio(D, 温度)=6/7*0.1426=0.122
前面我们讲了两种决策树分类算法 ID3 和 C4.5,了解了它们的数学原理。你可能会问,公式这么多,在实际使用中该怎么办呢?实际上,我们可以使用一些数据挖掘工具使用它们,比如 Python 的 sklearn,或者是 Weka(一个免费的数据挖掘工作平台),它们已经集成了这两种算法。

CART
ID3 是基于信息增益做判断,C4.5 在 ID3 的基础上做了改进,提出了信息增益率的概念。实际上 CART 分类树与 C4.5 算法类似,只是属性选择的指标采用的是基尼系数。ID3 和 C4.5 算法可以生成二叉树或多叉树,而 CART 只支持二叉树。同时 CART 决策树比较特殊,既可以作分类树,又可以作回归树。
在经济学中,基尼系数是用来衡量一个国家收入差距的常用指标。当基尼系数大于 0.4 的时候,说明财富差异悬殊。基尼系数在 0.2-0.4 之间说明分配合理,财富差距不大。
基尼系数本身反应了样本的不确定度。当基尼系数越小的时候,说明样本之间的差异性小,不确定程度低。分类的过程本身是一个不确定度降低的过程,即纯度的提升过程。所以 CART 算法在构造分类树的时候,会选择基尼系数最小的属性作为属性的划分。
假设 t 为节点,那么该节点的 GINI 系数的计算公式为:

这里 p(Ck|t) 表示节点 t 属于类别 Ck 的概率,节点 t 的基尼系数为 1 减去各类别 Ck 概率平方和。
通过下面这个例子,我们计算一下两个集合的基尼系数分别为多少:
集合 1:6 个都去打篮球;
集合 2:3 个去打篮球,3 个不去打篮球。
针对集合 1,所有人都去打篮球,所以 p(Ck|t)=1,因此 GINI(t)=1-1=0。
针对集合 2,有一半人去打篮球,而另一半不去打篮球,所以p(C1|t)=0.5,p(C2|t)=0.5,GINI(t)=1-(0.50.5+0.50.5)=0.5。
通过两个基尼系数你可以看出,集合 1 的基尼系数最小,也证明样本最稳定,而集合 2 的样本不稳定性更大。
CART 分类树
# encoding=utf-8
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import cross_val_score
import numpy as np
# 准备数据集
iris=load_iris()
# 获取特征集和分类标识
features = iris.data
labels = iris.target
# 随机抽取33%的数据作为测试集,其余为训练集
train_features, test_features, train_labels, test_labels = train_test_split(features, labels, test_size=0.33, random_state=0)
# 创建CART分类树
clf = DecisionTreeClassifier(criterion='gini')
# 拟合构造CART分类树
clf = clf.fit(train_features, train_labels)
# 用CART分类树做预测
test_predict = clf.predict(test_features)
# 预测结果与测试集结果作比对
score = accuracy_score(test_labels, test_predict)
print("CART分类树准确率 %.4lf" % score)
# 使用K折交叉验证 统计决策树准确率
print(u'cross_val_score准确率为 %.4lf' % np.mean(cross_val_score(clf, features, labels, cv=10)))
- 创建 CART 分类树,可以直接使用 DecisionTreeClassifier 这个类。创建这个类的时候,默认情况下 criterion 这个参数等于 gini,也就是按照基尼系数来选择属性划分,即默认采用的是 CART 分类树。
- train_test_split 可以帮助我们把数据集抽取一部分作为测试集,这样我们就可以得到训练集和测试集。
CART 回归树
CART 回归树划分数据集的过程和分类树的过程是一样的,只是回归树得到的预测结果是连续值,而且评判“不纯度”的指标不同。在 CART 分类树中采用的是基尼系数作为标准,在 CART 回归树中要根据样本的混乱程度,也就是样本的离散程度来评价“不纯度”。
我们假设 x 为样本的个体,均值为 u。为了统计样本的离散程度,我们可以取差值的绝对值,或者方差。
其中差值的绝对值为样本值减去样本均值的绝对值:
方差为每个样本值减去样本均值的平方和除以样本个数: 所以这两种节点划分的标准,分别对应着两种目标函数最优化的标准,即用最小绝对偏差(LAD),或者使用最小二乘偏差(LSD)。这两种方式都可以让我们找到节点划分的方法,通常使用最小二乘偏差的情况更常见一些。
所以这两种节点划分的标准,分别对应着两种目标函数最优化的标准,即用最小绝对偏差(LAD),或者使用最小二乘偏差(LSD)。这两种方式都可以让我们找到节点划分的方法,通常使用最小二乘偏差的情况更常见一些。
这里我们使用到 sklearn 自带的波士顿房价数据集,该数据集给出了影响房价的一些指标,比如犯罪率,房产税等,最后给出了房价。
# encoding=utf-8
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_boston
from sklearn.metrics import r2_score,mean_absolute_error,mean_squared_error
from sklearn.tree import DecisionTreeRegressor
# 准备数据集
boston=load_boston()
# 探索数据
print(boston.feature_names)
# 获取特征集和房价
features = boston.data
prices = boston.target
# 随机抽取33%的数据作为测试集,其余为训练集
train_features, test_features, train_price, test_price = train_test_split(features, prices, test_size=0.33)
# 创建CART回归树
dtr=DecisionTreeRegressor()
# 拟合构造CART回归树
dtr.fit(train_features, train_price)
# 预测测试集中的房价
predict_price = dtr.predict(test_features)
# 测试集的结果评价
print('回归树二乘偏差均值:', mean_squared_error(test_price, predict_price))
print('回归树绝对值偏差均值:', mean_absolute_error(test_price, predict_price))
- 使用 dtr=DecisionTreeRegressor() 初始化一棵 CART 回归树。
- 我们能看到 CART 回归树的使用和分类树类似,只是最后求得的预测值是个连续值。
- 不能用K折交叉检验,因为那是检查分类树的正确率的,这是回归。
CART 决策树的剪枝
CART 决策树的剪枝主要采用的是 CCP 方法,它是一种后剪枝的方法,英文全称叫做 cost-complexity prune,中文叫做代价复杂度。这种剪枝方式用到一个指标叫做节点的表面误差率增益值,以此作为剪枝前后误差的定义。用公式表示则是:

其中 Tt 代表以 t 为根节点的子树,C(Tt) 表示节点 t 的子树没被裁剪时子树 Tt 的误差,C(t) 表示节点 t 的子树被剪枝后节点 t 的误差,|Tt|代子树 Tt 的叶子数,剪枝后,T 的叶子数减少了|Tt|-1。
所以节点的表面误差率增益值等于节点 t 的子树被剪枝后的误差变化除以剪掉的叶子数量。因为我们希望剪枝前后误差最小,所以我们要寻找的就是最小α值对应的节点,把它剪掉。这时候生成了第一个子树。重复上面的过程,继续剪枝,直到最后只剩下根节点,即为最后一个子树。
泰坦尼克生存预测
import pandas as pd
import numpy as np
from sklearn.feature_extraction import DictVectorizer
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score
import graphviz
train_data = pd.read_csv('./train.csv')
test_data = pd.read_csv('./test.csv')
#train_data.info()
#train_data.describe()
#train_data.describe(include=['O'])
#train_data.tail()
#train_data.head()
# 数据清洗
train_data['Age'].fillna(train_data['Age'].mean(),inplace = True)
test_data['Age'].fillna(test_data['Age'].mean(),inplace = True)
train_data['Fare'].fillna(train_data['Fare'].mean(),inplace = True)
test_data['Fare'].fillna(test_data['Fare'].mean(),inplace = True)
#print(train_data['Embarked'].value_counts())
train_data['Embarked'].fillna('S',inplace = True)
test_data['Embarked'].fillna('S',inplace = True)
# 特征选择
features = ['Pclass','Sex','Age','SibSp','Parch','Fare','Embarked']
train_features = train_data[features]
train_labels = train_data['Survived']
test_features = test_data[features]
dvec=DictVectorizer(sparse=False)
train_features=dvec.fit_transform(train_features.to_dict(orient='record'))
#print(dvec.feature_names_)
# 构造 ID3 决策树
clf = DecisionTreeClassifier(criterion='entropy')#ID3
#决策树训练
clf.fit(train_features, train_labels)
test_features=dvec.transform(test_features.to_dict(orient='record'))
# 决策树预测
pred_lables = clf.predict(test_features)
# 得到决策树准确率,因为测试集没有结果,只能用训练集
acc_decision_tree = round(clf.score(train_features,train_labels),6)
print(u'score 准确率为 %.4lf' %acc_decision_tree)
# 使用K折交叉验证 统计决策树准确率
print(u'cross_val_score准确率为 %.4lf' % np.mean(cross_val_score(clf, train_features, train_labels, cv=10)))
dot_data = tree.export_graphviz(clf, out_file=None)
graph = graphviz.Source(dot_data)
graph.view()
生成的决策树如下:

需要用到graphviz包,通过在anaconda prompt界面输入 conda install python-graphviz 可以直接安装graphviz。
- clf = DecisionTreeClassifier(criterion=‘entropy’);entropy: 基于信息熵,也就是 ID3 算法,实际结果与 C4.5 相差不大;gini:默认参数,基于基尼系数。CART 算法是基于基尼系数做属性划分的,所以 criterion=gini 时,实际上执行的是 CART 算法。
- 创建分类树的参数:
DecisionTreeClassifier(class_weight=None, criterion='entropy', max_depth=None,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False, random_state=None,
splitter='best')
这些参数代表的含义:

生存预测的关键流程
总结
- ID3 算法,基于信息增益做判断。
优点:算法简单,通俗易懂
缺陷:无法处理缺失值;只能处理离散值,无法处理连续值;用信息增益作为划分规则,存在偏向于选择取值较多的特征。因为特征取值越多,说明划分的越细,不确定性越低,信息增益则越高;容易出现过拟合 - C4.5 算法,基于信息增益率做判断。
优点:能够处理缺省值 ;能对连续值做离散处理;使用信息增益比,能够避免偏向于选择取值较多的特征。因为信息增益比=信息增益/属性 。属性熵是根据属性的取值来计算的,一相除就会抵消掉;在构造树的过程中,会剪枝,减少过拟合。
缺点:构造决策树,需要对数据进行多次扫描和排序,效率低 - CART 算法,分类树是基于基尼系数做判断。回归树是基于偏差做判断。
- 特征选择是分类模型好坏的关键。选择什么样的特征,以及对应的特征值矩阵,决定了分类模型的好坏。通常情况下,特征值不都是数值类型,可以使用 DictVectorizer 类进行转化。
- 模型准确率需要考虑是否有测试集的实际结果可以做对比,当测试集没有真实结果可以对比时,需要使用 K 折交叉验证 cross_val_score;
- Graphviz 可视化工具可以很方便地将决策模型呈现出来,帮助你更好理解决策树的构建。