一、快速排序(用的比较多)
(1) 递归对所有数据分成[a,b)b(b,d]两个区间,(b,d]区间内的数都是大于[a,b)区间内的数
(2) 对(b,d]重复(1)操作,直到最右边的区间个数小于1000个。注意[a,b)区间不用划分
(3) 返回上一个区间,并返回此区间的数字数目。接着方法仍然是对上一区间的左边进行划分,分为[a2,b2)b2(b2,d2]两个区间,取(b2,d2]区间。如果个数不够,继续(3)操作,如果个数超过1000的就重复1操作,直到最后右边只有1000个数为止。
二、分块查找
先把100w个数分成100份,每份1w个数。先分别找出每1w个数里面的最大的数,然后比较。找出100个最大的数中的最大的数和最小的数,取最大数的这组的第二大的数,与最小的数比较。。。。
三、堆排序(针对大数据使用较多)
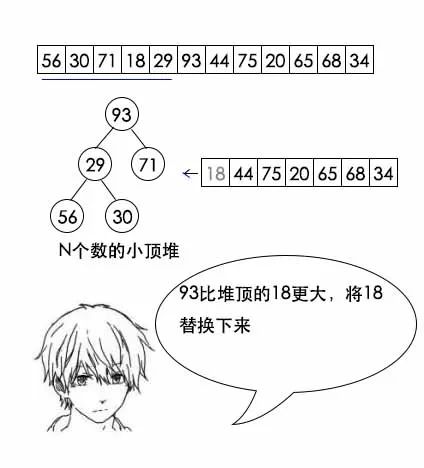
先取出前1000个数,维护一个1000个数的最小堆,遍历一遍剩余的元素,在此过程中维护堆就可以了。具体步骤如下:
- step1:取前m个元素(例如m=100),建立一个小顶堆。保持一个小顶堆得性质的步骤,运行时间为O(lgm);建立一个小顶堆运行时间为m*O(lgm)=O(m lgm);
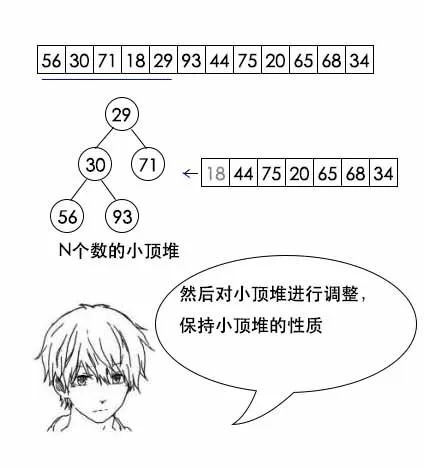
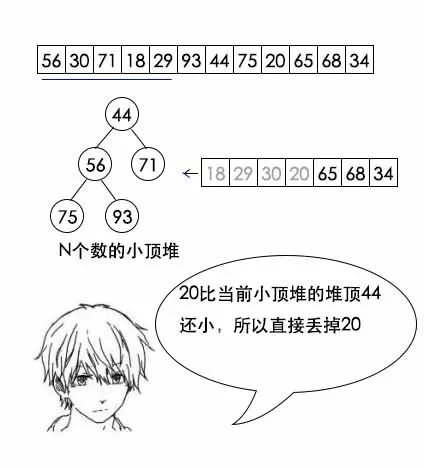
- step2:顺序读取后续元素,直到结束。每次读取一个元素,如果该元素比堆顶元素小,直接丢弃,如果大于堆顶元素,则用该元素替换堆顶元素,然后保持最小堆性质。最坏情况是每次都需要替换掉堆顶的最小元素,因此需要维护堆的代价为(N-m)*O(lgm);
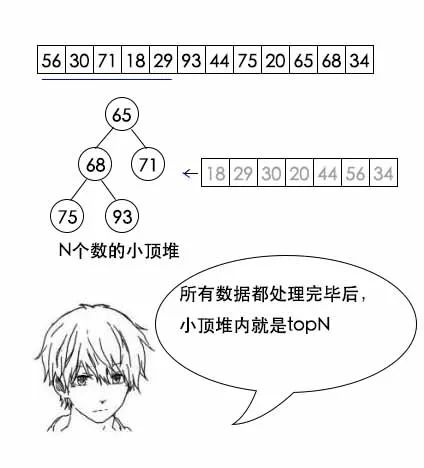
- 最后这个堆中的元素就是最大的1000个。时间复杂度为O(N lgm)。
补充:这个方法的说法也可以更简化一些:
假设数组arr保存1000个数字,首先取前1000个数字放入数组arr,对于第1001个数字k,如果k大于arr中的最小数,则用k替换最小数,对剩下的数字都进行这种处理。
排序一般都是拿空间换时间的。


题目:如何在10亿数中找出前1000大的数?







小史:我可以用分治法,这有点类似快排中partition的操作。随机选一个数t,然后对整个数组进行partition,会得到两部分,前一部分的数都大于t,后一部分的数都小于t。
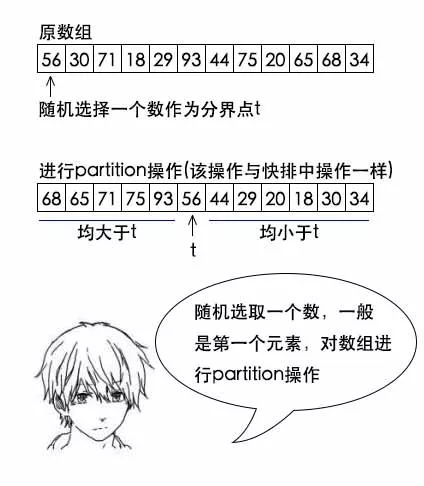

小史:如果说前一部分总数大于1000个,那就继续在前一部分进行partition寻找。如果前一部分的数小于1000个,那就在后一部分再进行partition,寻找剩下的数。
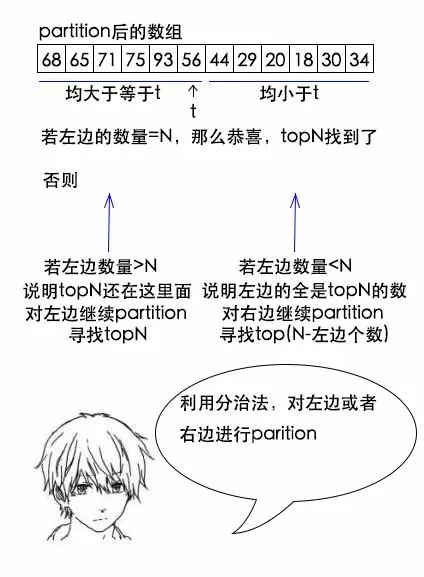




小史:首先,partition的过程,时间是o(n)。我们在进行第一次partition的时候需要花费n,第二次partition的时候,数据量减半了,所以只要花费n/2,同理第三次的时候只要花费n/4,以此类推。而n+n/2+n/4+...显然是小于2n的,所以这个方法的渐进时间只有o(n)

(注:这里的时间复杂度计算只是简化计算版,真正严谨的数学证明可以参考算法导论相关分析。)



半分钟过去了。






小史一时慌了神。

他回忆起了之前吕老师给他讲解bitmap时的一些细节。突然有了一个想法。



小史在纸上画了画。









推排序定义:
在描述算法复杂度时,经常用到O(1), O(n), O(logn), O(nlogn)来表示对应复杂度程度, 不过目前大家默认也通过这几个方式表示空间复杂度 。那么,O(1), O(n), O(logn), O(nlogn)就可以看作既可表示算法复杂度,也可以表示空间复杂度。
大O加上()的形式,里面其实包裹的是一个函数f(),O(f()),指明某个算法的耗时/耗空间与数据增长量之间的关系。其中的n代表输入数据的量。

推排序
堆排序是利用堆这种数据结构而设计的一种排序算法,堆排序是一种选择排序,它的最坏,最好,平均时间复杂度均为O(nlogn),它也是不稳定排序。首先简单了解下堆结构。
堆
堆是具有以下性质的完全二叉树:每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆;或者每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆。如下图:

堆排序从1亿个数中找到最小的100个数
package com.test;
import java.util.Date;
import java.util.Arrays;
import java.util.Random;
public class SortClass {
public static void main(String[] args) {
find();
}
public static void find() {//
int number = 100000000;// 一亿个数
int maxnum = 1000000000;// 随机数最大值
int i = 0;
int topnum = 100;// 取最大的多少个
Date startTime = new Date();
Random random = new Random();
int[] top = new int[topnum];
for (i = 0; i < topnum; i++) {
top[i] = Math.abs(random.nextInt(maxnum));// 设置为随机数
// top[i] = getNum(i);
}
buildHeap(top, 0, top.length);// 构建最小堆, top[0]为最小元素
for (i = topnum; i < number; i++) {
int currentNumber2 = Math.abs(random.nextInt(maxnum));// 设置为随机数
// int currentNumber2 = getNum(i);
// 大于 top[0]则交换currentNumber2 重构最小堆
if (top[0] < currentNumber2) {
top[0] = currentNumber2;
shift(top, 0, top.length, 0); // 构建最小堆 top[0]为最小元素
}
}
// System.out.println(Arrays.toString(top));
sort(top);
System.out.println("\n"+Arrays.toString(top)+"\n");
Date endTime = new Date();
System.out.println("用了" + (endTime.getTime() - startTime.getTime()) + "毫秒");
}
public static int getNum(int i) {
return i;
}
// 构造排序数组
public static void buildHeap(int[] array, int from, int len) {
int pos = (len - 1) / 2;
for (int i = pos; i >= 0; i--) {
shift(array, from, len, i);
}
}
/**
* @param array top数组
* @param from 开始
* @param len 数组长度
* @param pos 当前节点index
*/
public static void shift(int[] array, int from, int len, int pos) {
// 保存该节点的值
int tmp = array[from + pos];
int index = pos * 2 + 1;// 得到当前pos节点的左节点
while (index < len)// 存在左节点
{
if (index + 1 < len && array[from + index] > array[from + index + 1])// 如果存在右节点
{
// 如果右边节点比左边节点小,就和右边的比较
index += 1;
}
if (tmp > array[from + index]) {
array[from + pos] = array[from + index];
pos = index;
index = pos * 2 + 1;
} else {
break;
}
}
// 最终全部置换完毕后 ,把临时变量赋给最后的节点
array[from + pos] = tmp;
}
public static void sort(int[] array) {
for (int i = 0; i < array.length - 1; i++) {
// 当前值当作最小值
int min = array[i];
for (int j = i + 1; j < array.length; j++) {
if (min > array[j]) {
// 如果后面有比min值还小的就交换
min = array[j];
array[j] = array[i];
array[i] = min;
}
}
}
}
}