大数据问题
Map-Reduce和Hadoop逐渐成为热门。
1介绍哈希函数
哈希函数又叫散列函数,哈希函数的输入域可以是非常大的范围,但是输出域是固定范围。假设为s。
哈希函数性质:
1:典型的哈希函数都拥有无限的输入值域;
2:输入值相同时,返回值一样;
3:输入值不同时,返回值可能一样,也可能不一样。
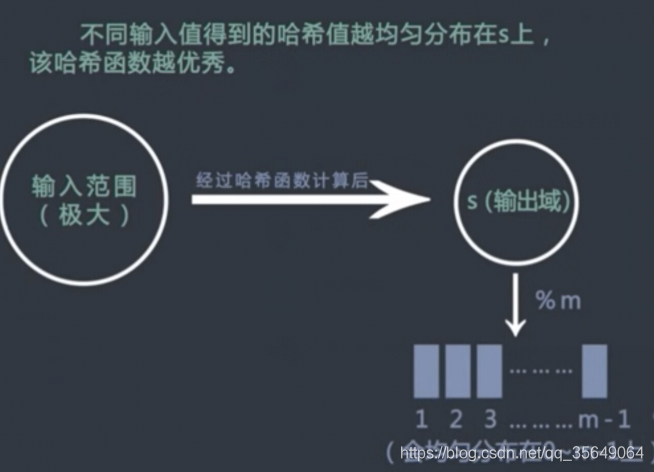
4:不同输入值得到的哈希值,整体均匀的分布在输出域s上。
1~3是哈希函数的哈希值,第4点是评价一个哈希函数优劣的关键。(并且这种分布与输入值是没有关系的;比如:aaa1,aaa2,aaa3,虽然相似,但是计算出的哈希值差异巨大)
MD5算法与SHA1算法都是经典的哈希函数算法,了解即可,面试时不需要掌握。
2:介绍Map-Reduce
第一步:Map阶段:通过哈希算法把大任务分成小任务;
第二步:Reduce阶段:子任务并发处理,然后合并结果。
难点:在于工程上的处理。
注意点:
1:备份的考虑,分布式存储的设计细节,以及容灾策略。
比如在一个大型的分布式系统中,每台计算机是一个计算节点,这么多机器,总会有坏的,一旦坏了,上面的数据怎么办呢,一个数据属于多少个备份才算合适呢?
MapReduce产生文件相等庞大,可能一个问文件就可能让一台机器的文件存不下,这么多文件,如何分布式存储呢?还有如何让这个系统对用户来说是透明的呢(就是用户在终端使用的时候感觉在一台电脑上是一样的),这种存储的核心是分布式文件系统,而分布式文件系统需要考虑软件,硬件,效率,灾难恢复等多方面的问题。这不是一个简单的工程问题。
2:任务分配策略与任务进度跟踪的细节设计,节点状态的呈现。
再比如说:MapReduce的Map阶段就是把任务分配给不同的机器,分布式系统的机器性能都是不同的,即便是机器性能相同,任务也不会分配的那么平均,必然会导致某些机器先完成,某些机器后完成,所以任务分配也需要考虑,均衡的策略也需要去设计。
还有分布式系统是多用户的,任务的执行是并行的,这就需要跟踪每个任务完成的进程,一旦有些任务失败,就要想办法重新执行该任务,所以就需要中心控制,而且既然要跟踪任务的执行,当然也要实时查询节点的状态,同时还得重新分配失败的任务。
3:多用户权限的控制。
再比如,任何一个系统都要设置不同的权限,防止用户修改删除,系统的重要文件,导致系统的奔溃,分布式系统也不例外,对多用户的安全控制也是需要考虑的条件之一。
3:用MapReduce解决的一个经典的统计问题
用MapReduce方法统计一篇文章中单词出现的个数。