堆排序和快速排序的比较
堆排序是接近nlgn的下界,而快排有性能坏的情况,为何还是快排表现更优秀呢?
1.堆排序是处理数组中相隔较远的数据,快速排序是根据两个 指针按序遍历的,根据寄存器、高速缓存的热cache、 局部性原理,快排更好
2.快排的极端情况太难复现,而且可以 用随机基准数
3.快排还有各种优化的方案
基数排序的性能
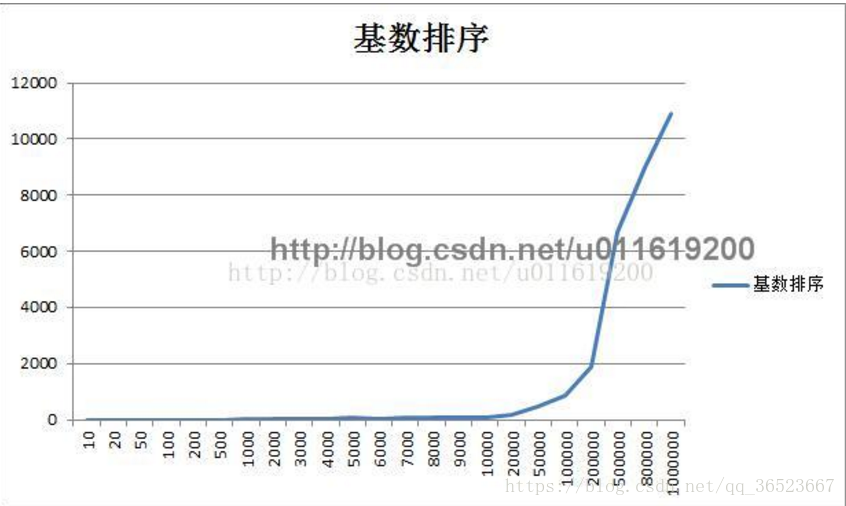
在低数据量的时候,性能很不错;但是非常占内存。一般我们不会采取高内存换空间的算法(数据量大的时候就太恐怖了)
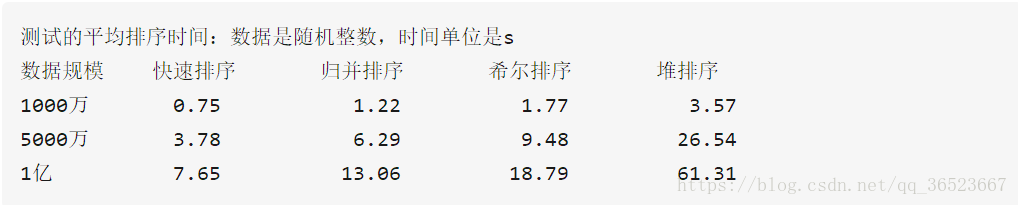
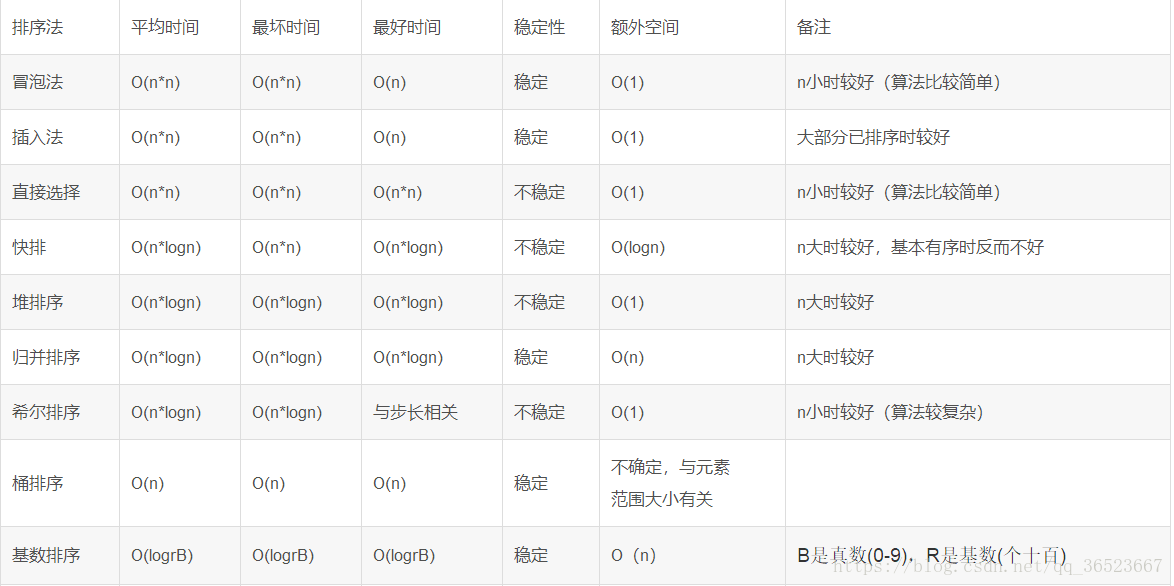
综合性能
数据多到内存装不下怎么办?
(假设内存有100M容量)比如1G的数据,分10份,每份100M。先用快排让每一份各自排好序,然后写到文件中。这10份100M的 文件这个时候已经有序了。这10份每份取9M,一共90M,使得他们合并。合并后的结果放到10M的缓存区中,满了就clear,IO到 文件中。
一百、一万、一亿选取什么算法最好?
100可以基数、桶,这些很占内存,而且有一些限制条件,但是很快!
10000可以快排
一亿只能快排(因为热cache,所以比堆排序好)+归并(数据太大装不下)
大部分数据有序的情况下,用什么 算法比较好?
插入+二分。
从大量数据中取出前100个
第一反应是开始做题吗?no,大量数据,内存肯定是装不下的。那我们就假设所有数据被分成了N份吧。
先看第一份,排序前100个,然后后面的数都插入+二分去修改前100个数。
一份读完,就clear后面的数, 加载新的文件进来。
这样一次遍历就解决了。
https://blog.csdn.net/ztkhhhhhd/article/details/53138631
https://blog.csdn.net/zhushuai1221/article/details/51781002
这两篇待学习