Tensorflow+RNN实现新闻文本分类
- 加载数据集
数据集cnew文件夹中有4个文件:
1.训练集文件cnews.train.txt
2.测试集文件cnew.test.txt
3.验证集文件cnews.val.txt
4.词汇表文件cnews.vocab.txt
新闻文本共有10个类别,65000个样本数据,其中训练集50000条,测试集10000条,验证集5000条。
输入:从txt文本中输入的数据为新闻类别、新闻内容,进行词和ID的映射后,所有的词变为词向量。
输出: 预测结果y为一个10维数组,数组中值的取值范围为[0,1],使用tf.argmax(y,1),取出数组中最大值的下标,再用独热表示以及模型输出转换成数字标签。
加载训练集函数:

加载词文件函数:

2.词和ID的映射
将词汇表中的词映射到对应的ID,再把训练文本中的每一条新闻中所有词转换成对应ID。使用测试集验证模型预测准确度时,对测试集中的文本做同样操作。
1) 使用列表推导式得到词汇及其id对应的列表,并调用dict方法将列表强制转换为字典。代码为:word2id_dict = dict([(b, a) for a, b in enumerate(vocabulary_list)]),将1中的词汇列表数组做了词和ID的映射,格式为:{'<PAD>': 0, ',': 1, '的': 2, '。': 3,...}。
2) 使用列表推导式和匿名函数定义函数content2idlist,函数作用是将文章中的每个字转换为id,代码为:content2idList = lambda content : [word2id_dict[word] for word in content if word in word2id_dict]。
3) 使用列表推导式得到的结果是列表的列表,总列表train_idlist_list中的元素是每篇文章中的字对应的id列表;代码为:train_idlist_list = [content2idList(content) for content in train_content_list],格式为:[[387, 1197, …, 3], …,[199, 964, …,3, 24]]
3.构建RNN网络
1) 设置循环神经网络的超参数

2) 将每个样本统一长度为seq_length,train_X = kr.preprocessing.sequence.pad_sequences(train_idlist_list, sequence_length)。
3) 调用LabelEncoder对象的fit_transform方法做标签编码,代码为:train_y = labelEncoder.fit_transform(train_label_list),格式为: [0 0 0 ... 9 9 9],将训练数据的类别标签转换成整型。
4) 调用keras.untils库的to_categorical方法将标签编码的结果再做Ont-Hot编码,将整型标签转换成onehot,代码为:train_Y = kr.utils.to_categorical(train_y, num_classes),格式为:[[1. 0. 0. 0. 0. 0. 0. 0. 0. 0.] … [1. 0. 0. 0. 0. 0. 0. 0. 0. 0.]]。
5) 调用tf库的get_variable方法实例化可以更新的模型参数embedding,矩阵形状为vocabulary_size*embedding_size,即5000*64。代码为embedding = tf.get_variable('embedding', [vocabolary_size, embedding_size])。
6) 使用tf.nn库的embedding_lookup方法将输入数据做词嵌入,代码为:embedding_inputs = tf.nn.embedding_lookup(embedding, X_holder)。X_holder中已经设置了序列长度为150/600。得到新变量embedding_inputs的形状为batch_size*sequence_length*embedding_size。
7) RNN层的搭建:将上述六步中处理好的数据输入到LSTM网络中,调用的是tf.nn.rnn_cell.BasicLSTMCell 函数,代码为:lstm_cell = tf.contrib.rnn.BasicLSTMCell(num_hidden_units), num_hidden_units为隐藏层神经元的个数,实验中设置为了128/256。还要设置一个 dropout 参数,避免过拟合,代码为:lstm_cell = tf.contrib.rnn.DropoutWrapper(cell=lstm_cell, output_keep_prob=0.75)。
8) 将 LSTM cell 和三维的数据输入到 tf.nn.dynamic_rnn ,目的为展开整个网络并构建一整个 RNN 模型,代码为:outputs, state = tf.nn.dynamic_rnn(lstm_cell, embedding_inputs,dtype=tf.float32)。
9) 获取最后一个细胞的h,即最后一个细胞的短时记忆矩阵,代码为:last_cell = outputs[:, -1, :]。
10) 添加第一个全连接层:调用tf.layers.dense方法,将结果赋值给变量full_connect1,形状为batch_size*num_fc1_units,词向量大小与全连接层神经元一致。
11) 调用tf.contrib.layers.dropout方法,防止过拟合,代码为:full_connect1_dropout = tf.contrib.layers.dropout
(full_connect1, dropout_keep_probability)。
12) 调用tf.nn.relu方法,即激活函数,增强拟合复杂函数的能力,代码为:full_connect1_activate = tf.nn.relu(full_connect1_dropout)。
13) 添加第二个全连接层:操作类似于第一个全连接层,但全连接层的神经元个数为10(对应新闻的10种类别),然后使用Softmax函数,将结果转化成10个类别的概率。
14) 使用交叉熵作为损失函数,调用tf.train.AdamOptimizer方法定义优化器optimizer 学习率设置为了0.001。代码为:

所以该文本识别模型为:输入数据-->RNN层(LSTM模型)-->全连接层1-->全连接层2 -->输出
4.使用训练数据迭代训练模型
模型迭代运行5000/10000次,从训练集中选取batch_size大小,即64个样本做批量梯度下降;每训练100次模型,从测试集中随机选取200个样本,验证一下模型的预测能力。
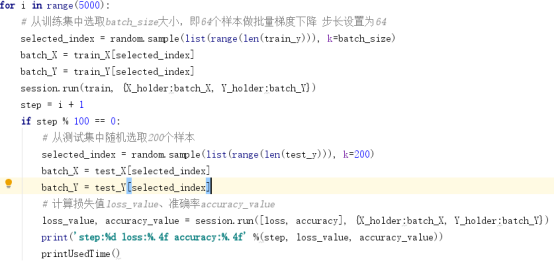
5.在测试集上进行准确率评估
如5中所示每训练100次模型,在测试集中随机选取200个样本,验证训练的模型预测能力。
实验结果记录:
实验中使用了门限循环单元(GRU)、长短期记忆神经网络(LSTM)做对比。
长短期记忆LSTM是一种和GRUs不同的复杂的激活单元,作用与GRUs相似,但是在单元的结构上不一样,最终记忆产生融合了输入门与遗忘门的结果,且输出门是GRUs中没有显性存在的门,目的为从隐层状态分离最终的记忆。
GRU则是LSTM的一个变体, GRU保持了LSTM的效果同时又使结构更加简单。
BasicLSTMCell实验结果:
| 模型方法 |
BasicLSTMCell |
BasicLSTMCell |
BasicLSTMCell |
BasicLSTMCell |
| 训练次数 |
5000 |
5000 |
10000 |
10000 |
| 序列长度 |
150 |
150 |
600 |
600 |
| 隐藏层神经元 |
128 |
256 |
128 |
256 |
| 每次测试样本数 |
200 |
200 |
200 |
200 |
| 准确度(5000/10000次训练) |
0.8700 |
0.8950 |
0.9250 |
0.9350 |
| 准确度(最大) |
0.9150 |
0.9100 |
0.9250 |
0.9800 |
GRUCell实验结果:
| 模型方法 |
GRUCell |
GRUCell |
GRUCell |
GRUCell |
| 训练次数 |
5000 |
5000 |
10000 |
10000 |
| 序列长度 |
150 |
150 |
600 |
600 |
| 隐藏层神经元 |
128 |
256 |
128 |
256 |
| 每次测试样本数 |
200 |
200 |
200 |
200 |
| 准确度(5000/10000次训练) |
0.9400 |
0.9300 |
0.9500 |
0.9500 |
| 准确度(最大) |
0.9550 |
0.9300 |
0.9800 |
0.9750 |
实验对比可知:
1) 在训练次数、序列长度、隐藏层神经元相同的条件下,BasicLSTMCell的预测准确度,均低于GRUCell,原因为:TensorFlow中的BasicLSTMCell是一种参考或者标准实现,解决实际问题中不是首选;GRU 参数相对少更容易收敛。
2) 增加训练次数(5000à1000),模型的预测准确度有提升,因为随着训练次数的增多,有用的信息在 LSTM 中进行了保存。
3) LSTM单元的数量很大程度上取决于输入文本的平均长度,更多的单元数量可以帮助模型存储更多的文本信息,但模型的训练时间就会增加很多。