简介
这篇论文是MIT周博磊于2018年发表在ECCV上的一篇论文,这篇论文通过挖掘视频中多帧之间的时序关系来推理视频中的行为。我个人认为这篇论文从视频帧之间的关系入手,丰富了行为在时序上的依赖性,更符合目前的研究对于行为的理解。我将从以下几个方面讲解这篇论文,也是对自己阅读这篇论文的记录。
1.论文思想
从人类的角度来思考的话,视频所记录的行为的发生是有一定顺序的,比如一个起跑的动作,一定是这样的过程:蹲伏->在跑道上跑->冲刺到终点,而这个过程被打乱的话我们就很难快速的看出这一行为是什么,所以我们可以认为行为的顺序性对行为的识别来说是有很大影响的。
目前的行为识别方法往往是基于多模态的行为表达:RGB视频帧和光流,编码行为的表象和动态性,而且往往两者是单独进行分类的,相当于两者“协商”共同决策行为所属的类别(关于行为识别方法的综述请看这篇博客)。本文从推理视频帧之间的因果关系的角度,考虑了视频帧的表象顺序,提出了一个时序推理网络:在视频帧中进行了稀疏采样,采样单独的帧然后通过MLP来学习他们之间的因果关系。
2.实验方法
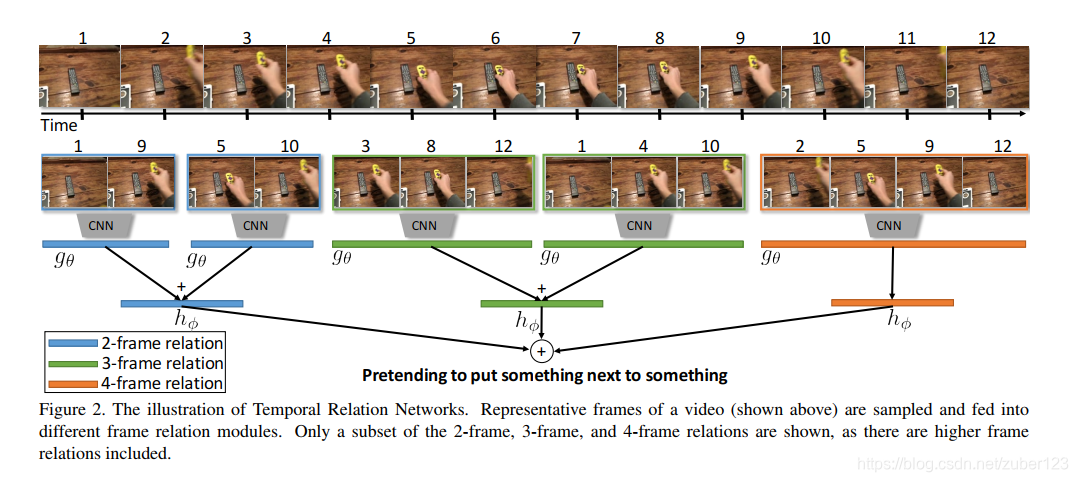
图1 多帧关系聚合
如上图所示,TRN网络通过对视频帧进行稀疏采样,随机选取存在一定间隔的任意多帧图像(可以是2帧,3帧,4帧等等),计算它们之间的关系。对于每一组视频帧之间的关系,在采样后都会对它们进行顺序排序。
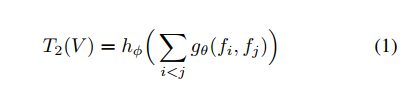
如公式(1)所示,fi和fj分别表示的是两帧图像送入到CNN中提取特征后的特征向量,gθ()在本文中代表的是对第i帧和第j帧特征的拼接,hΦ()表示的是对每两帧聚合后的结果的激活。
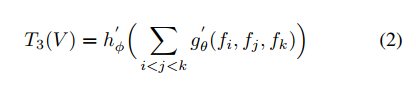
公式(2)表示的是对三帧图像的聚合,在代码中,利用多层感知机来实现对帧间关系的提取,θ和Φ分别表示的是多层感知机的参数。
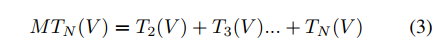
公式(3)表示的是对不同尺度帧间关系的聚合,Td表示的是d帧之间关系聚合的结果,把多尺度帧间关系的结果进行叠加得到的最终结果表示的内容应当是该视频帧中,任意多帧之间关系的融合的结果。
3.实验结果
本文在something-something数据集、charades数据集、Jester数据集上分别做了实验,我只跑了在something-somethingv2数据集上的实验,故在此实验结果图仅放something-something数据集上的结果。

在该论文中有一个实验比较有意思,作者将something-something数据集中的视频帧做了顺序和乱序,送入TRN网络中,实验结果表明something-something数据集中顺序的准确率比乱序的准确率高很多,而在UCF101上采用完全相同的实验条件和实验流程,发现顺序和乱序的实验效果相差不多,这表明UCF101中youtube类型视频的活动识别并不一定需要时间推理能力,因为与已经在进行的活动没有太多的偶然关系。

4.总结
总体来说这篇论文的思路很巧妙,很简单,该论文是被17年一篇做视觉问答的cvpr所inspired,用MLP实现因果推理并将其用在了视频帧的因果关系推理上,这样可以大范围的考虑一个视频中的多帧,比简单的分段选取帧更能综合考虑视频帧中的行为动态性。有错误还请评论指出!