一.分桶表数据存储
分区针对的是数据的 存储路径;分桶针对的是 数据文件。
分区提供一个隔离数据和优化查询的便利方式,不过并非所有的数据集都能形成合适的分区,特别是之前提到过的要确定合适的划分大小这个顾虑。
分桶是将数据集分解成更容易管理的若干个部分。
- 先创建分桶表,通过直接导入数据文件的方式
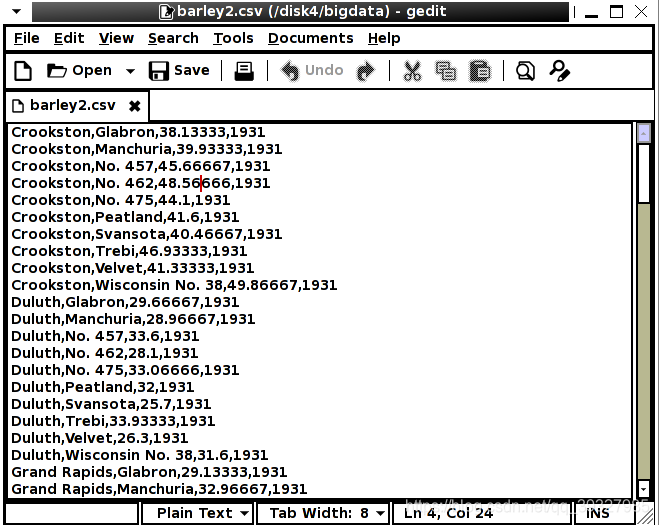
(1)数据准备
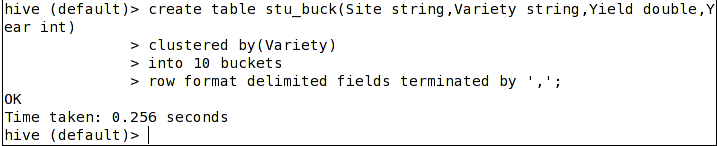
(2)创建分桶表
(3)加载数据

数据如下:
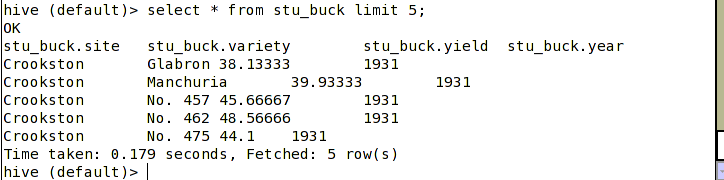
但像这样直接把文件load到指定目录是不能给你分成四个文件的,想想都不可能,这是加载方式的问题。 - 通过
select *一张表来插入数据
(1)我这里又创建了一张表用来那什么
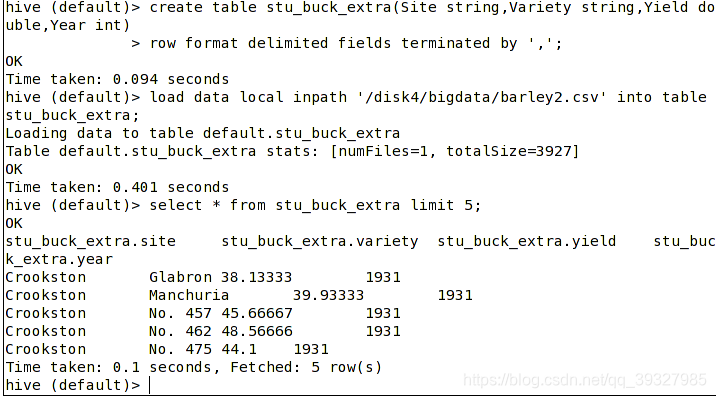
然后把 stu_buck_extra 中的数据 select * 之后插入到 stu_buck 中,前提是要加入以下参数:

然后就成功了哈:
当然你也可以直接设置全局设置,下次就直接插就完事了。
tip:你 select * 这个文件,它是按照上图文件顺序依次读的。
二.分桶表抽样查询
分桶表自然不能像分区表一样通过 where 语句来查询,因为分桶表分的是数据文件,分区表分的是文件目录。
语句如下:
select * from tablename tablesample(bucket x out of y);
其中,x 代表你从哪个桶开始取数据,hive 根据 y 的大小来决定抽样的比例。


这里思考为什么 x 的值必须小于等于 y?