版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u012292754/article/details/82350529
1 注意
- order by 会对输入做全局排序,因此只有一个reducer,会导致当输入规模较大时,需要较长的计算时间。
- sort by不是全局排序,其在数据进入reducer前完成排序。因此,如果用sort by进行排序,并且设置mapred.reduce.tasks>1,则sort by只保证每个reducer的输出有序,不保证全局有序。
- distribute by(字段)根据指定的字段将数据分到不同的reducer,且分发算法是hash散列。
- Cluster by(字段) 除了具有Distribute by的功能外,还会对该字段进行排序。
因此,如果分桶和sort字段是同一个时,此时,cluster by = distribute by + sort by
分桶表的作用:最大的作用是用来提高join操作的效率;
2 新建分桶表
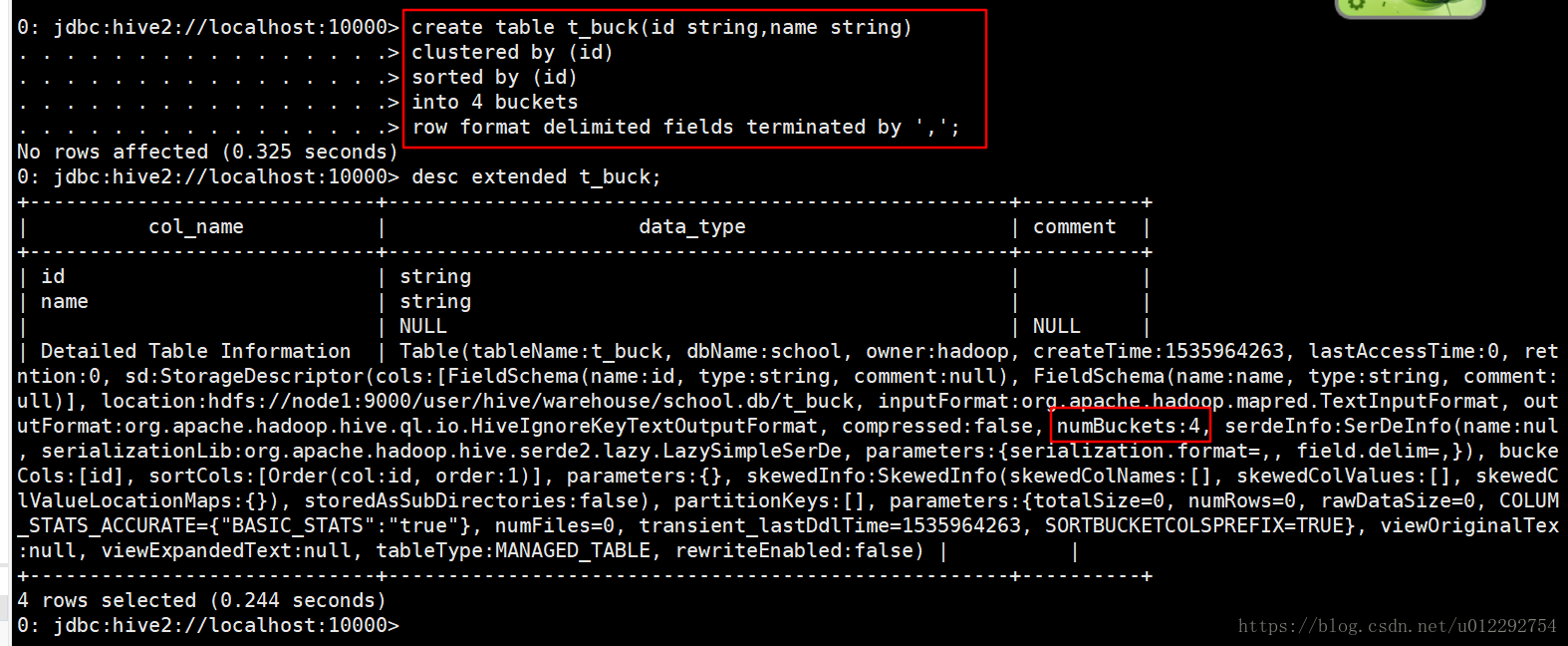
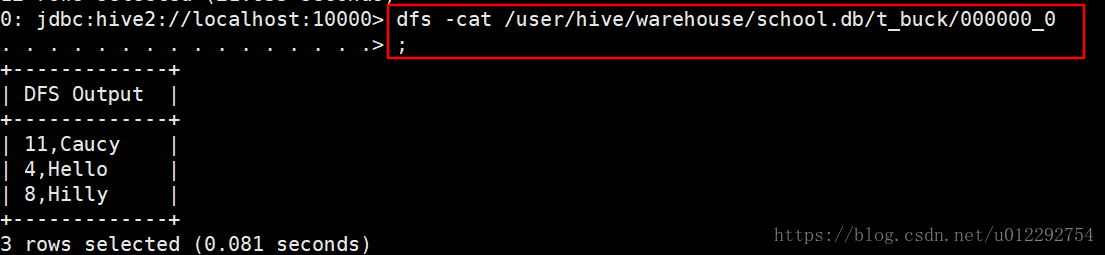
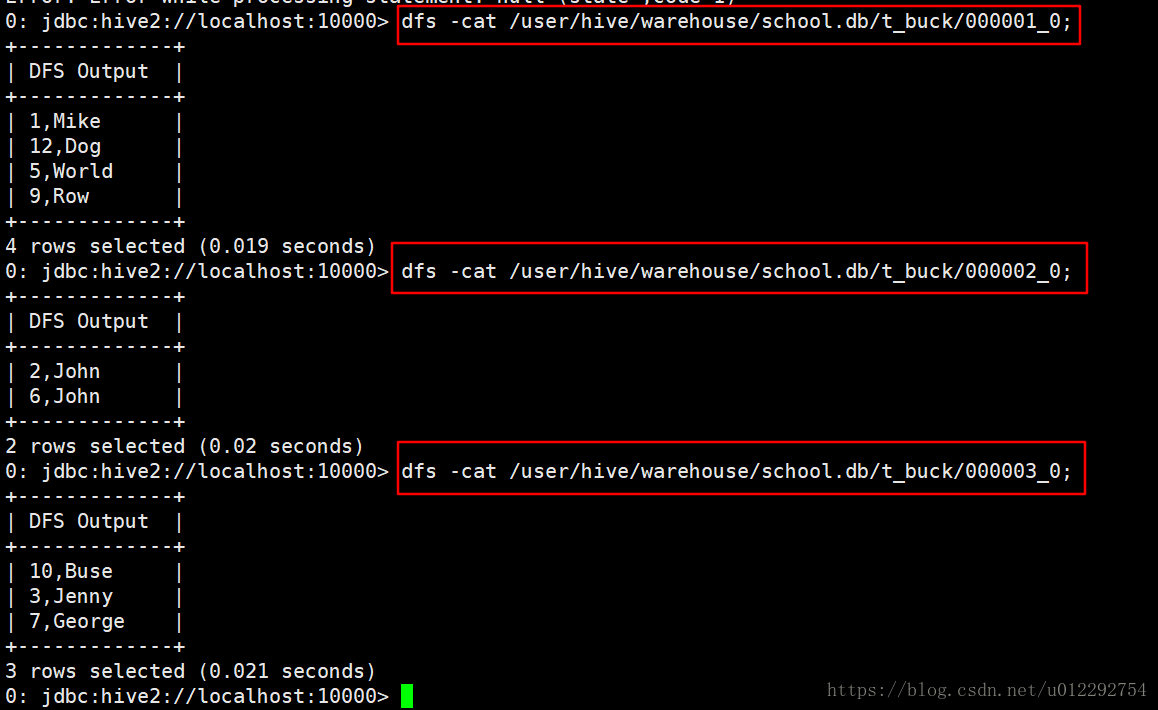
数据文件
导入数据发现报错,原来分桶表不支持 load 这种操作,解决方法是新建一个临时表,导入数据,再把数据从临时表导入分桶表;
解决方案参考链接 分桶表导入数据

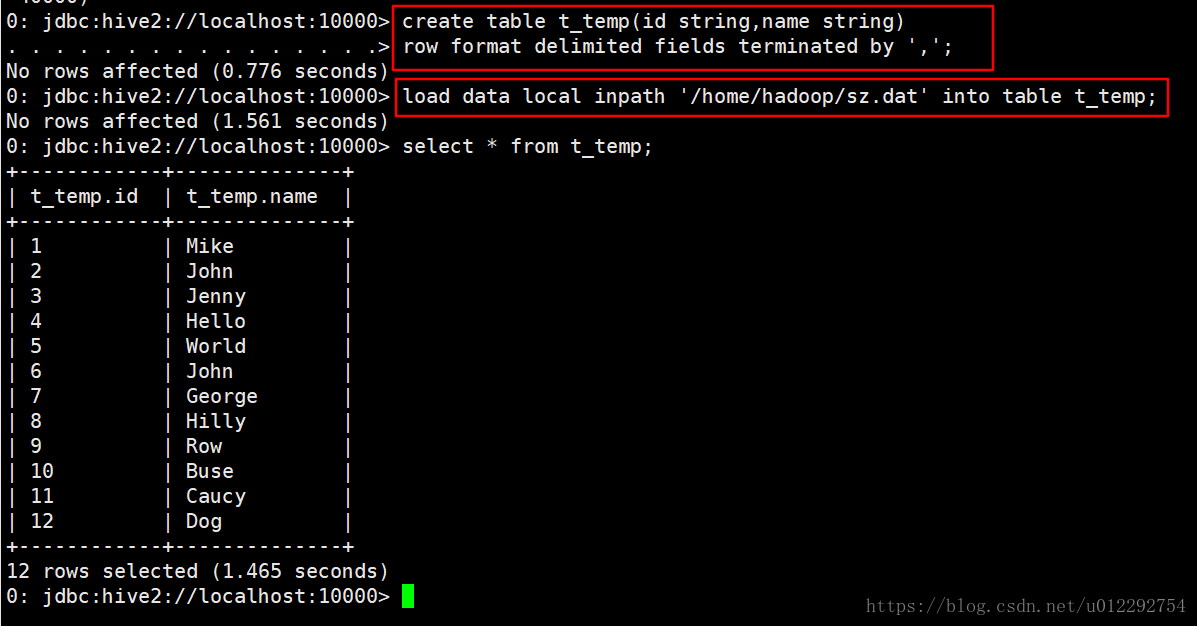
hive 分桶开关:hive.enforce.bucketing = true
set mapred.reduce.tasks=4(等于分桶数量)
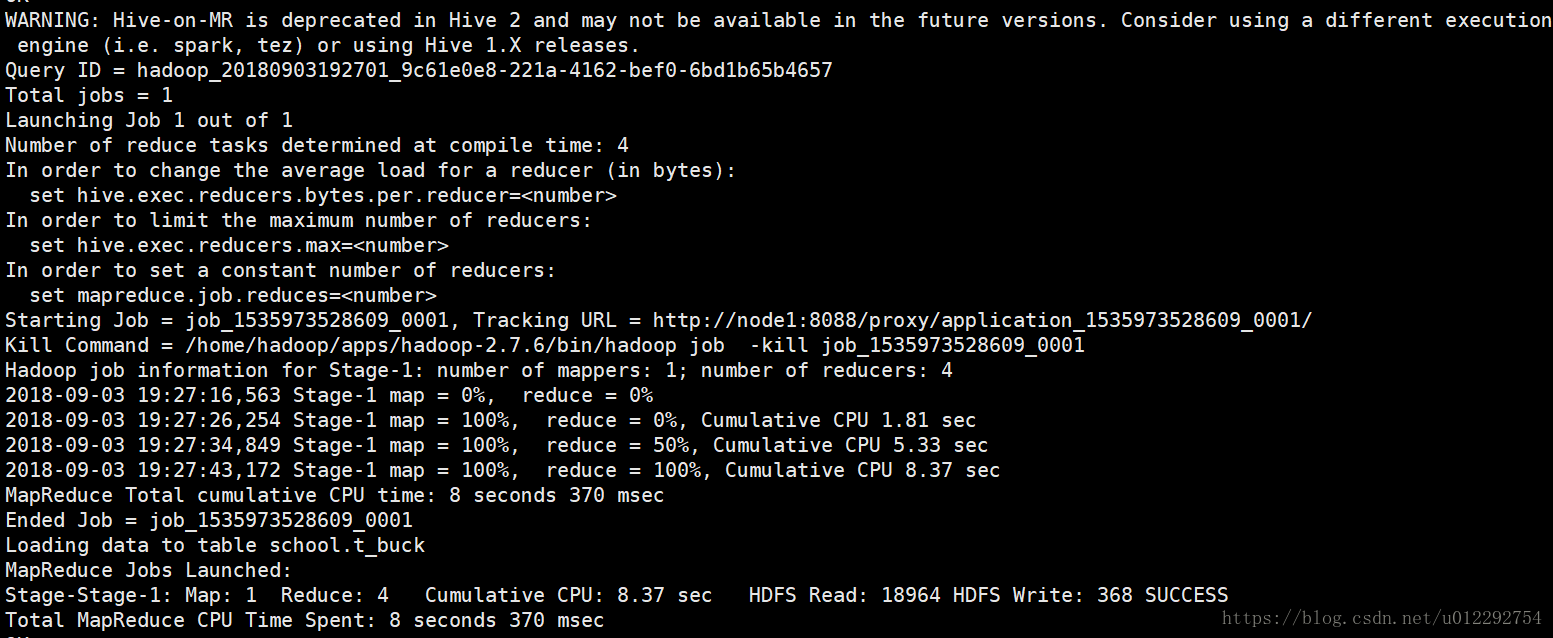
insert overwrite table t_buck select id,name from t_temp;

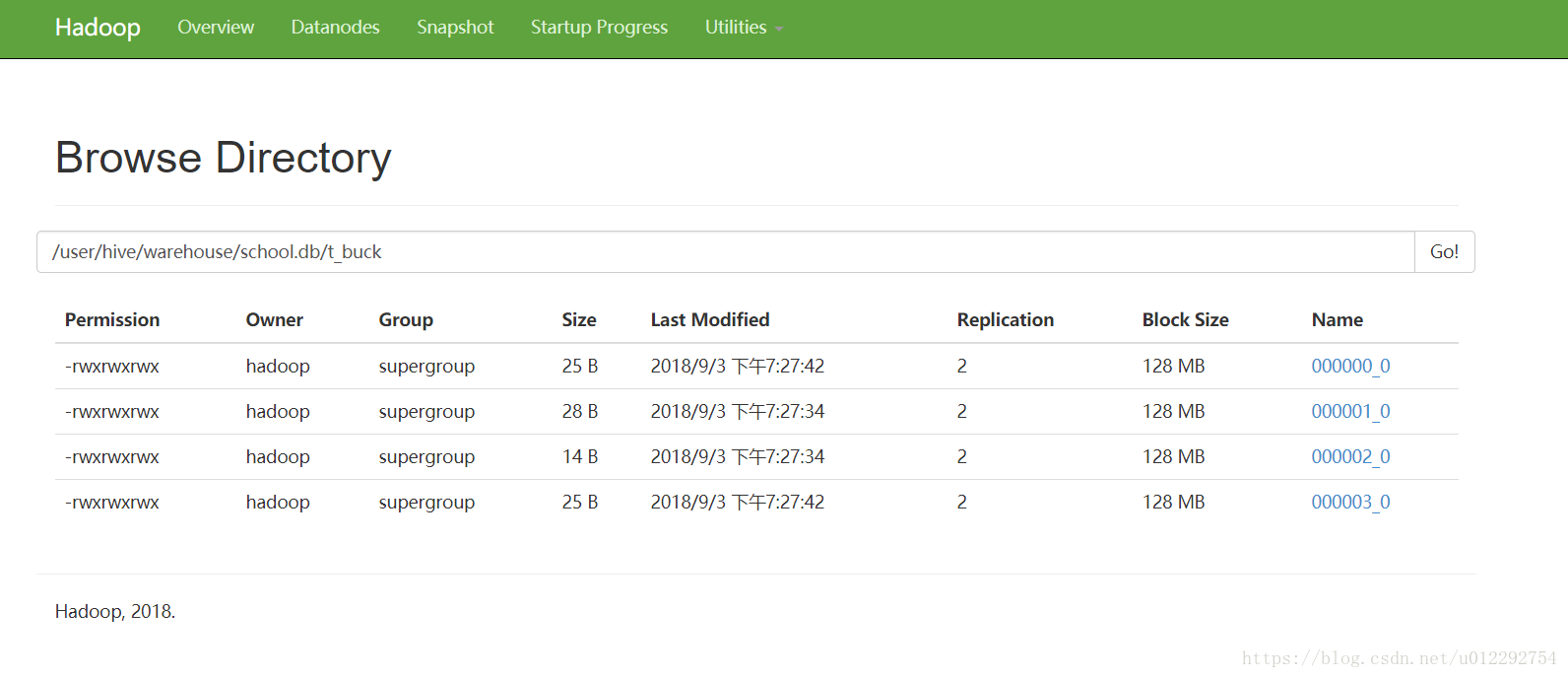
服务器端输出的信息
3 INSERT 语法
INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1 FROM from_statement- Multiple inserts:
FROM from_statement
INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1
[INSERT OVERWRITE TABLE tablename2 [PARTITION ...] select_statement2] ...
- Dynamic partition inserts:
INSERT OVERWRITE TABLE tablename PARTITION (partcol1[=val1], partcol2[=val2] ...) select_statement FROM from_statement