public class test01(){
public static void main(String[] args){
//创建一个自定义数组
int[] arr= new int[10];
//数组第一个值为1
arr[0]=1;
//数组第二个值为2
arr[1]=1
//每个值为前2数相加
for(int i=2;i<arr.length;i++){
arr[i]=arr[i-1]+a[i-2];
}
//输出第10个数的值
System.out.println(arr[10]);
}
}
快速排序
public static void quickSort(int[] array, int low, int high) {
/**
* 分析:
* 1.选定一个基准值,array[low]
* 2.右指针从右向左遍历high--,查找比基准值小的数据,左指针从左向右low++,查找比基准值大的数据
* 3.如果指针未相遇,交换左右两值位置,如果指针相遇,则替换基准值的位置
* 4.左递归,右递归
*/
// 方法退出条件,指针相遇或错过
if (low >= high) {
return;
}
// 1. 指定基准值和左右指针记录位置
int pivot = array[low];
int l = low;
int r = high;
int temp = 0;
// 2. 遍历条件,左右指针位置
while (l < r) {
// 2.1 右侧遍历
while (l < r && array[r] >= pivot) {
r--;
}
// 2.2 左侧遍历
while (l < r && array[l] <= pivot) {
l++;
}
// 2.3 l指针还在r指针左侧,尚未相遇
if (l < r) {
temp = array[l];
array[l] = array[r];
array[r] = temp;
}
}
// 3. 当左右指针相遇,交换基准值位置
array[low] = array[l];
array[l] = pivot;
// 4. 根据条件左侧递归遍历
if (low < l) {
quickSort(array, low, l - 1);
}
// 5. 根据条件右侧递归遍历
if (r < high) {
quickSort(array, r + 1, high);
}
}
此处用int数组实现,需要理解以下内容 理解左右指针暂停条件,保证基准数左侧都小于等于基准数,保证基准数右侧都大于等于基准数 函数退出条件,遍历操作退出条件 当指针相遇的时候,交换基准值与当前值位置 当指针相遇并交换基准值位置后,此时数组以基准值为界,逻辑上分为左右两个数组;左侧都小于等于基准值,右侧都大于等于基准值;此时使用递归思路,分别操作左右两个逻辑数组; 递归方法的左右指针以及基准值已经变动——通过校正左右指针边界,确保基准值不再次参与排序 理解条件判断的边界,画图辅助
分区表的作用
快速查询
静态分区和动态分区的区别
静态分区: 事先分区 动态分区: 事先不做准备
分桶的特点
根据hash函数抽样搞笑处理数据 分桶是个文件 分区是个文件夹
hive 操作
1 启动
sh zhh.sh start #启动shell脚本 hive service metastore #启动hive(独立窗口) hiveserver2 #启动hive(独立窗口) zeppelin-daemon.sh start # 网页zeppelin 192.168.64.210:8080 # 网页zeppelin 192.168.64.210:50070 # 网页hadoop
2.编写分桶
#创建一个分桶表
%hive
create table mydemo.stu{
id string,
name string,
age string
}
clustered by (id)
into 4 buckets
#
--set hive.enforce.bucketing=true
insert into mydemo.stu select * from mydemo.tmp
2.1分桶表抽样
%hive select * from mydemo.stu tablesample(bucket 2 out of 4) select * from mydemo.stu tablesample(4 rows)
2.1.1伪随机抽样
select * from mydemo.stu tablesample(bucket 1 out of 4 on rand(1024)) # rand(1024)数值代表伪随机数
3.侧视图
%hive create table mydemo.temp(words string) load data local inpath '/opt/dd.txt' overwrite into table mydemo.temp select * from mydemo.temp
3.1炸开..
%hive select explode(split(words,' ')) from mydemo.temp
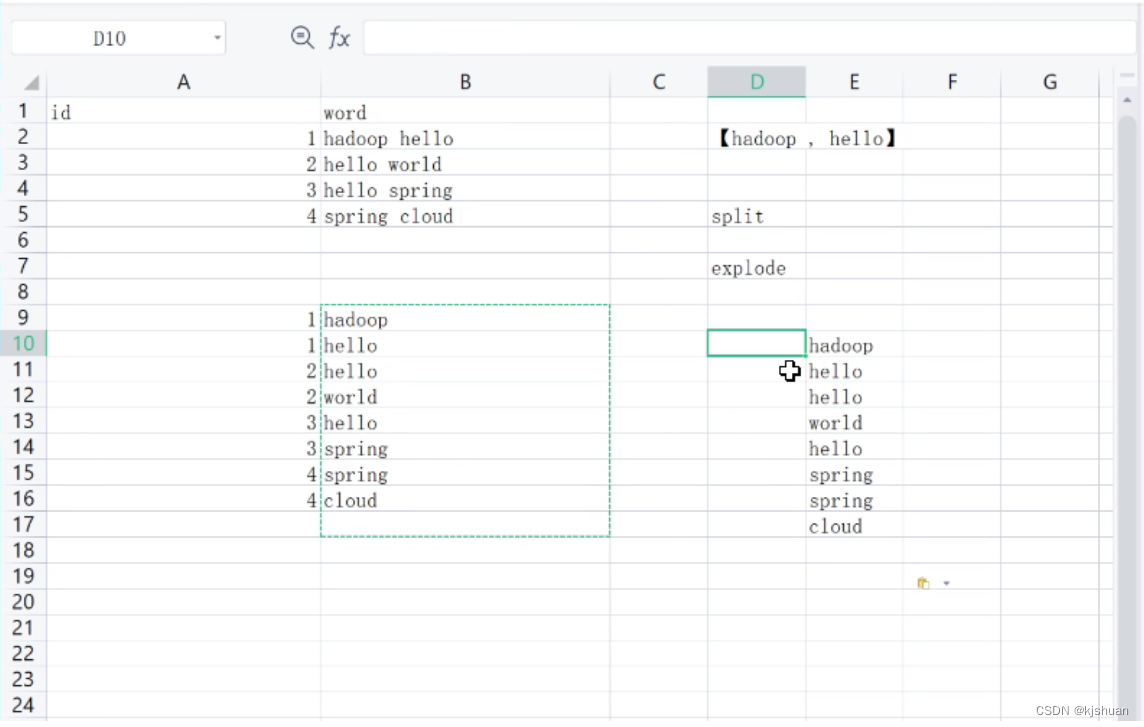
3.2 做一个count统计
%hive with t1 as ( select id ,res from mydemo.temp lateral view outer explode(split(words,' ')) a as res) select res,count(res) word_cnt from t1 group by res

hive高级查询
掌握Hive的数据查询 掌握Hive的数据加载和交换 掌握Hive的数据排序 理解Hive的聚合运算 理解Hive的窗口函数Hive查询- SELECT基础 SELECT用于映射符合指定查询条件的行 Hive SELECT是数据库标准SQL的子集使用方法类似于MySQL关键字和MySQL一样,不区分大小写limit子句where子句运算符、like, rlike group by子句 having子句
1.拖入文件
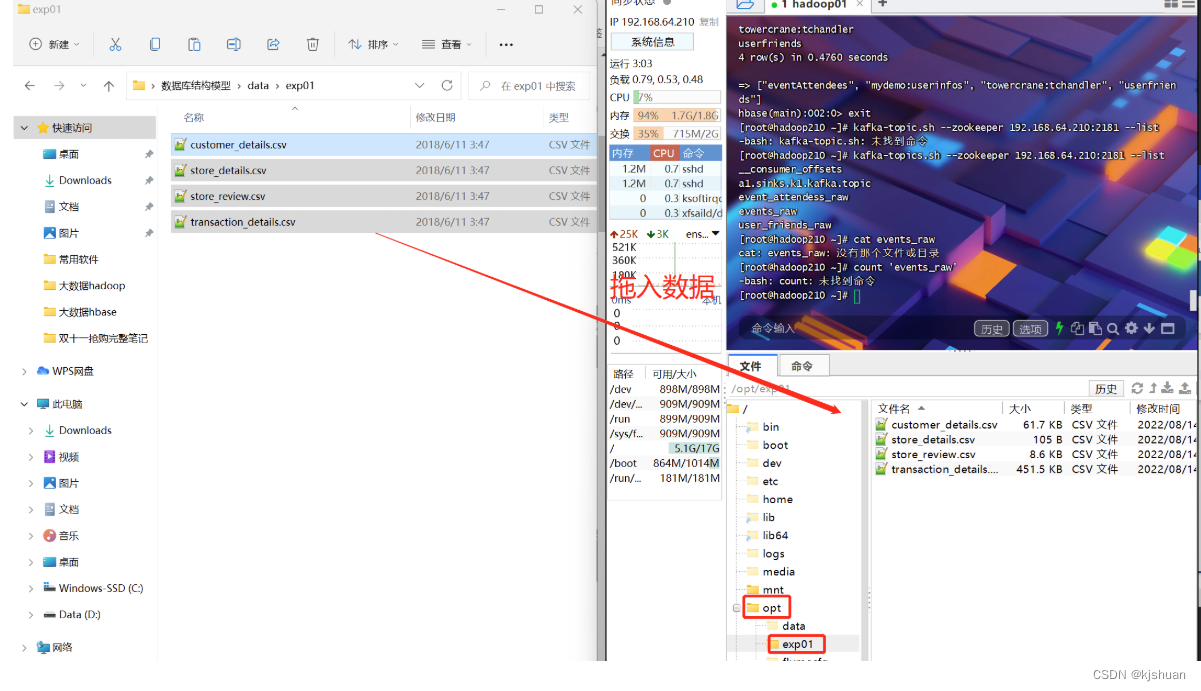
2.访问linux文件
cd /opt/exp01/ cat custoer_details
3.zeppelin创建表
1.創建練習數據庫exp01
create database exp01
2.创建用户表商店表 商店交易积分表交易信息表
%hive
create table exp01.customer(
custid string,
firstname string,
lastname string,
email string,
gender string,
address string,
country string,
language string,
job string,
credittype string,
creditno string
)
row format delimited fields terminated by ','
tblproperties("skip.header.line.count"="1")
3.商店报表
%hive
create table exp01.stores(
store_id string,
storename string,
empnumber string
)
row format delimited fields terminated by ','
tblproperties("skip.header.line.count"="1")
4.商店交易积分表
%hive
create table exp01.review(
tranid string,
store_id string,
review_score string
)
row format delimited fields terminated by ','
tblproperties("skip.header.line.count"="1")
5.交易信息表 #解决逗号分割数据乱序问题
%hive
create table exp01.trans(
tranid string,
custid string,
store_id string,
price string,
product string,
buydate string,
buytime string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' WITH SERDEPROPERTIES ( "separatorChar" = ",", "quoteChar" = "\"", "escapeChar" = "\\" )
tblproperties("skip.header.line.count"="1")
#解决逗号分割数据乱序问题 ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' WITH SERDEPROPERTIES ( "separatorChar" = ",",
"quoteChar" = "\"",
"escapeChar" = "\\"
)
6.加载数据
%hive load data local inpath '/opt/exp01/customer_details.csv' overwrite into table exp01.customer load data local inpath '/opt/exp01/store_details.csv' overwrite into table exp01.stores load data local inpath '/opt/exp01/store_review.csv' overwrite into table exp01.review load data local inpath '/opt/exp01/transaction_details.csv' overwrite into table exp01.trans
7.查看数据
%hive select * from exp01.customer select * from exp01.stores select * from exp01.review select * from exp01.trans

8.查询订单表中共有多少不同顾客下过订单
%hive select count(*) from (select custid exp01.trans group by custid) a
9.查询商品表中前5个商品
select product from exp01.trans group by product limit 5
10使用正则表达式匹配顾客表中ID、姓名与所在城市列
%hive select * from exp01.customer where firstname rlike '.*[cC].*'
11.使用关联查询获取没有订单的所有顾客
select c.custid,concat(firstname,'-',lastname) name from exp01.customer c left join ( select custid,max(tranid) tranid from exp01.trans group by custid) d on c.custid=d.custid where d.tranid is null
12.利用insert導出數據
%hive insert overwrite local directory 'opt/tmp' select c.custid,concat(firstname,'-','lastname') name from exp01.customer c -- cd tmp -- cat 000000_0 | head -3
13导出表
%hive export table exp01.customer to '/opt/tmp01' -- 在hadoop 中去找
14排序
%hive select * from( select * from exp01.trans distribute by store_id sort by cast(price as BIGINT) desc) a where store_id=2