一、分桶及抽样查询
1.分桶表数据存储
分区针对的是数据存储路径(HDFS中表现出来的便是文件夹),分桶针对的是数据文件。分区提供一个隔离数据和优化查询的便利方式。不过,并非所有的数据集都可形成合理的分区,特别是当数据要确定合适的划分大小的时候,分区便不再合适。分桶是将数据集分解成更容易管理的若干部分的技术。
2.先创建分桶表,通过直接导入数据的方式插入数据
创建分桶表
create table stu_buck(id int,name string)
clustered by(id)
into 4 buckets
row format delimited fields terminated by '\t';查看表结构
desc formatted stu_buck;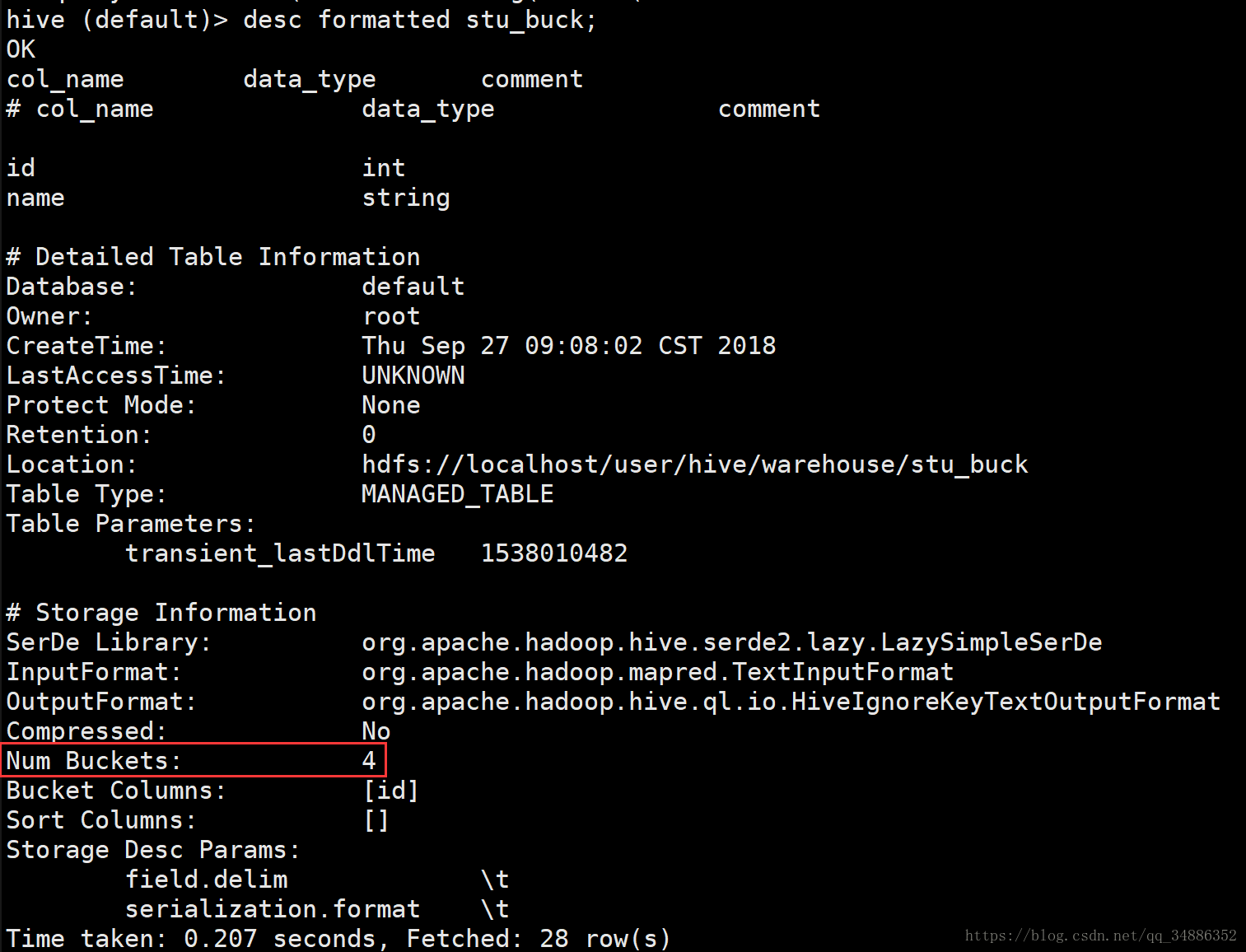
红色标记出来的地方便是分桶的数量
将分桶功能开启(默认为false)
set hive.enforce.bucketing = true;设置reduce个数(设置成不限制)
set mapreduce.job.reduces=-1;通过文件导入数据
load data local inpath '/opt/student.txt' into table stu_buck;通过子查询方式导入数据(这里的时候抛出一个异常,重启服务器之后异常消失)
insert into table stu_buck select id,name from stu;查看hdfs目录是否已经分桶

3.分桶采样查询
对于非常大的数据集,有时用户需要使用的是一个具有代表性的查询结果而不是全部结果。Hive可以通过对表进行抽样来满足这个需求。
select * from stu_buck TABLESAMPLE(bucket 1 out of 4 on id);tablesample便是抽样语句,语法:
TABLESAMPLE(BUCKET x OUT OF y);y必须是table总bucket数的倍数或者是因子。hive会根据y的大小,决定抽样的比例。例如:table总共被分了4份,当y=2时,抽取(4/2=)2个bucket的数据,当y=8时,抽取(4/8=)1/2个bucket的数据。
x则表示从哪个bucket开始抽样。例如:table总bucket数为4,tablesample(bucket4 out of 4),表示总共抽取(4/4=)1个bucket的数据,抽取第4个bucket的数据。
这里x的值必须小于等于y的值,否则会抛出异常。
FAILED:SemanticException[Error 10061]:Numerator should not be bigger than denonminator in sample clause for table stu_buckhive还提供了另外一种按照百分百进行抽样的方式,这种事基于行数的,按照输入路径下的数据块百分比进行的采样。
select * from stu tablesample(0.1 percent);这种抽样方式不一定适合于所有的文件格式。另外,这种抽样的最小抽样单元是一个HDFS数据。因此,如果这个表数据大小小于普通的的块大小(128m)的话,那么将会返回所有行。
二、函数
1.查询系统中自带的函数
show functions;2.显示自带函数的用法
desc function {函数名};3.详细显示自带函数的用法
desc function extended{函数名};4.自定义函数
我们可以通过UDF来完成自定义函数,根据自定义函数类别可以分为以下三种:
- UDF(User-Defined-Function)一进一出
- UDAF(User-Defined Aggregation Function)聚集函数,多进一出
- UDTF(User-Defined Table-Generating Functions)一进多出
编程步骤
- 继承org.apache.hadoop.hive.ql.UDF
- 需要实现evaluate函数,evaluate函数支持重载
- 在hive的命令窗口创建函数
- 添加jar:add jar linux_jar_path
- 创建function:create [temporay] function [dbname.]function_name AS class_name;
- 在hive命令窗口删除函数:Drop [temporay] function [if exists] [dbname.]function_name;
UDF必须有返回类型,可以返回Null,但是返回类型不能为void
5.自定义函数实例
1.创建一个java工程
2.将hive的jar包解压后,将apache-hive-1.2.1-bin\lib文件夹下的jar包拷贝到java工程中。
3.如果使用pom工程添加如下java包
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>1.2.1</version>
</dependency>4.创建类
public class Lower extends UDF {
public String evaluate(final String s){
if (s == null){
return null;
}
return s.toLowerCase();
}
}5.打成jar包上传到hive所在服务器
6.添加jar包到hive中(hive命名行中)
add jar /opt/udf.jar7.创建临时函数与开发好的java class关联
create temporary function my_lower as 'com.gyx.hive.Lower';8.使用自定义的函数
select ename,my_lower(ename) lowername from emp;三、压缩和存储
1.设置hadoop的压缩配置
参照之前的博客:https://blog.csdn.net/qq_34886352/article/details/82689965
2.开启Map输入阶段的压缩,可以减少job中map和Reduce task间数据传输量。
1.开启hive中间传输数据压缩功能
set hive.exec.compress.intermediate=true;2.开启mapreduce中map输出压缩功能
set mapreduce.map.output.compress=true;3.设置mapreduce中map输出数据的压缩方式
set mapreduce.map.outputcompress.codec={压缩格式参照上面博客的格式}3.开启reduce输出阶段压缩
当Hive将输出写入到表中时,输出内容同样可以进行压缩。属性hive.exec.compress.output控制这个功能,可以通过在查询语句中或者执行脚本中设置这个值为true。
1.开启hive最终输出数据压缩功能
set hive.exec.compress.output=true;2.开启mapreduce最终输出数据压缩
set mapreduce.output.fileoutputformat.compress=true;3.设置mapreduce最终数据输出压缩方式
set mapreduce.output.fileoutputformat.compress.codec={压缩格式参照上面博客的格式}4.设置mapreduce最终数据输出压缩为块压缩
set mapreduce.output.fileoutputformat.compress.type=BLOCK;四、存储
1.文件存储格式
hive支持的文件存储的格式主要有:TEXTFILE、SEQUENCEFILE、ORC、PARQUET。
2.列式存储和行式存储
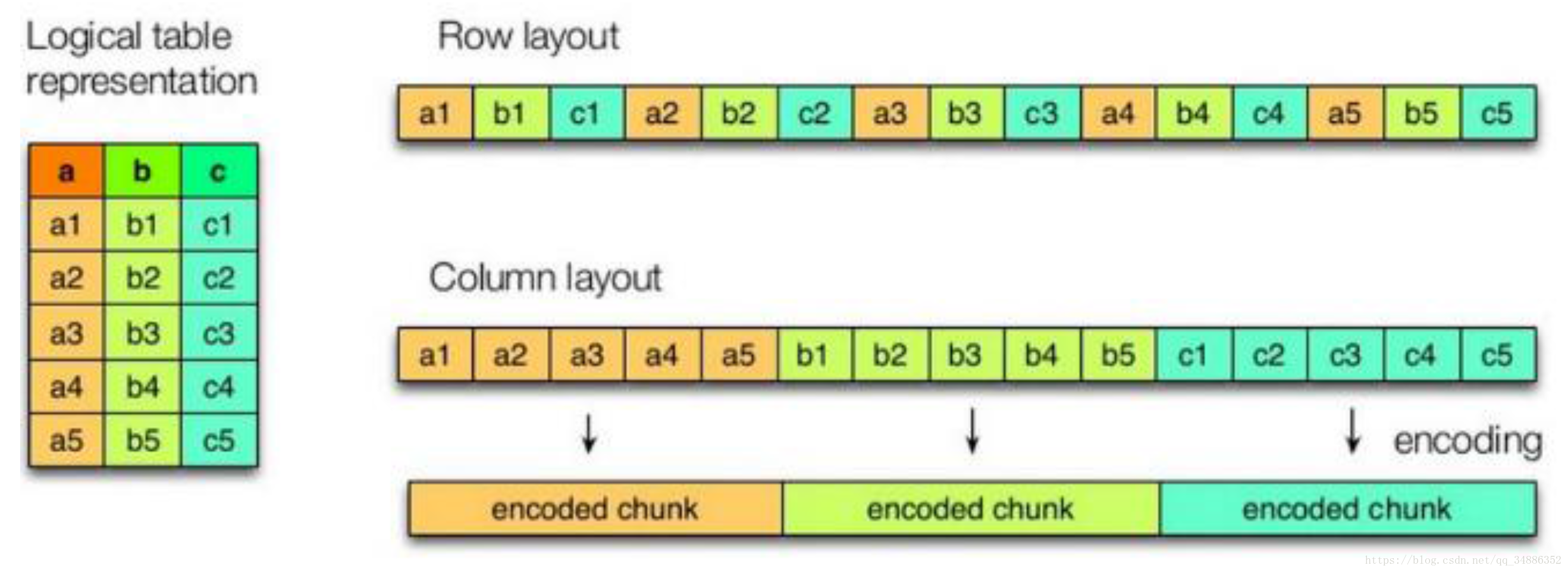
行存储的特点:查询满足条件的一整行数据的时候,列存储则需要去每个聚集的字段找到对应的每个列,行存储只需要找到其中的一个值,其余的值就在相邻的地方,所以此时行存储查询的速度更快。
列存储的特点:应为每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读的数据量;每个字段的数据类型一定是相同的,列式存储可以针对性的设计更好的压缩算法。
TEXTFILE和SEQUENCEFILE的存储格式都是基于行存储的。
ORC和PARQUET是基于列式存储的
3.TextFile格式
默认格式,数据不做压缩,磁盘开销大,数据解析开销大。可集合Gzip和Bzip2使用,但使用这种方式,hive不会对数据进行切分,从而无法对数据进行并行操作。
4.Orc格式
ORC(Optimized Row Columnar)是hive0.11版里引入的新的存储格式。
可以看到每个Orc文件由1个或多个Stripe组成,每个Stripe250M大小,这个Stripe实际相对于RowGroup概念,不过大小由4MB->250MB,这样能提升顺序读取的吞吐率。
每个Stripe里有三部分组成,分别是Index Data,RowData,Stripe Footer:
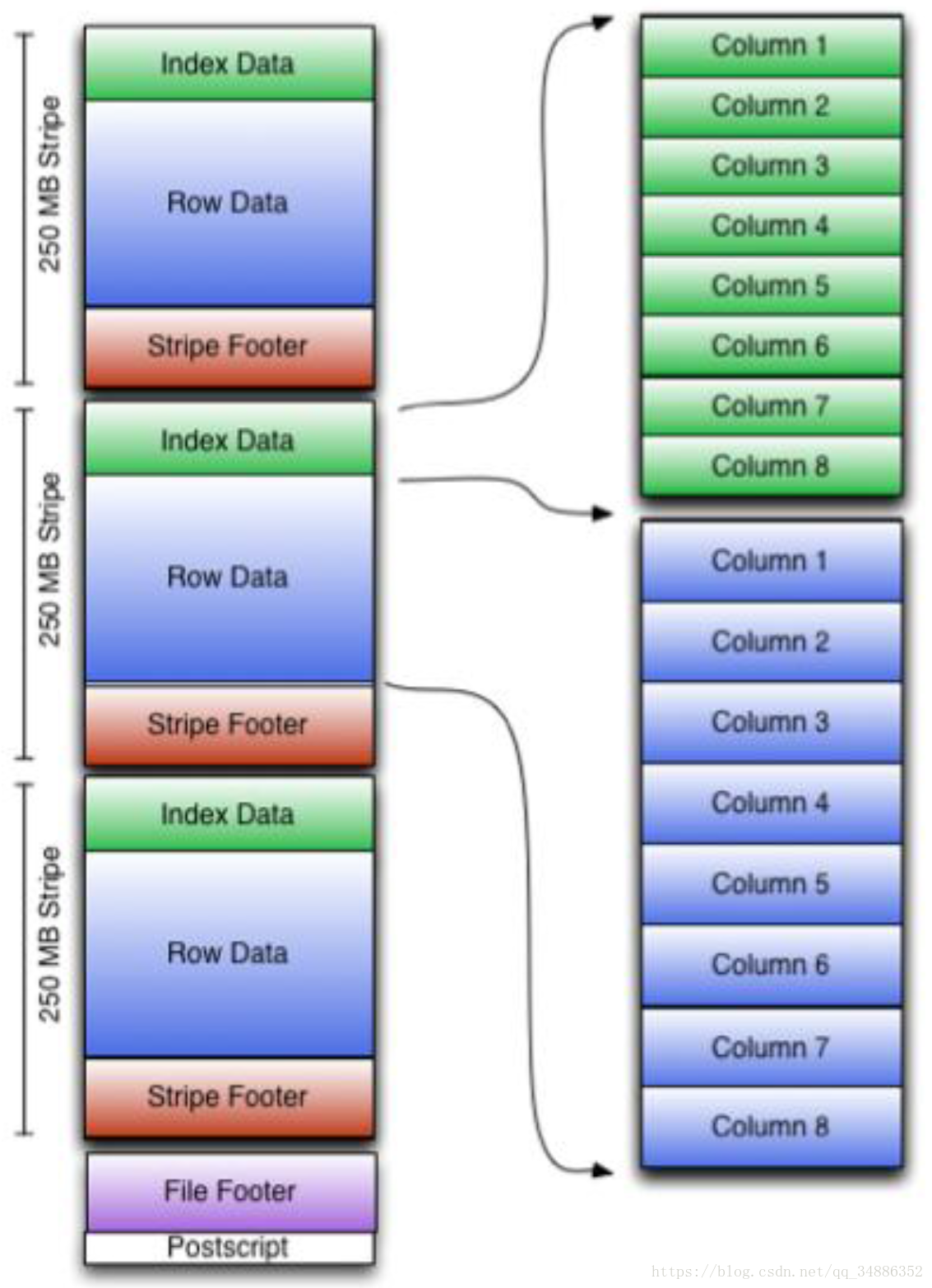
Index Data:一个轻量级的index,默认是每隔1W行做一个索引。这里做的索引应该只是记录某行的的个字段的RowData中offset。
Row Data:存的是具体的数据,先取部分行,然后对这些行按列进行存储。对每个列进行了编码,分成对多个Stream来存储。
StripeFooter:存的是各个Steam的类型,长度等信息。
每个文件有一个FileFooter,这个在里面存的是每个Stripe的行数,每个Column的数据类型信息等;每个文件的尾部是一个PostScript,这里面记录了整个文件的压缩类型以及FileFooter的长度信息等。在读取文件时,会seek到文件尾部读PostScript。从里面解析到FileFooter长度,在读到FileFooter,从里面解析到各个Stripe信息,再读各个Stripe,即从后往前读。
5.Parquet格式
parquet是面向分析型业务的列式存储格式,由Twitter和Cloudera合作开发,2015年5月从Apache的卵化器里毕业未Apache顶级项目。
Parquet文件是以二进制方式存储的,所有是不可以直接读取的,文件中包括该文件的数据和元数据,因此Parquet格式文件是自解析的。
通常情况下,在存储Parquet数据的时候会按照Block大小设置行组的大小,由于一般情况下每个Mapper任务处理数据的最小单位是一个Block,这样可以把每一个行组由一个mapper任务处理,增大任务执行并行度。Parquet文件格式如下
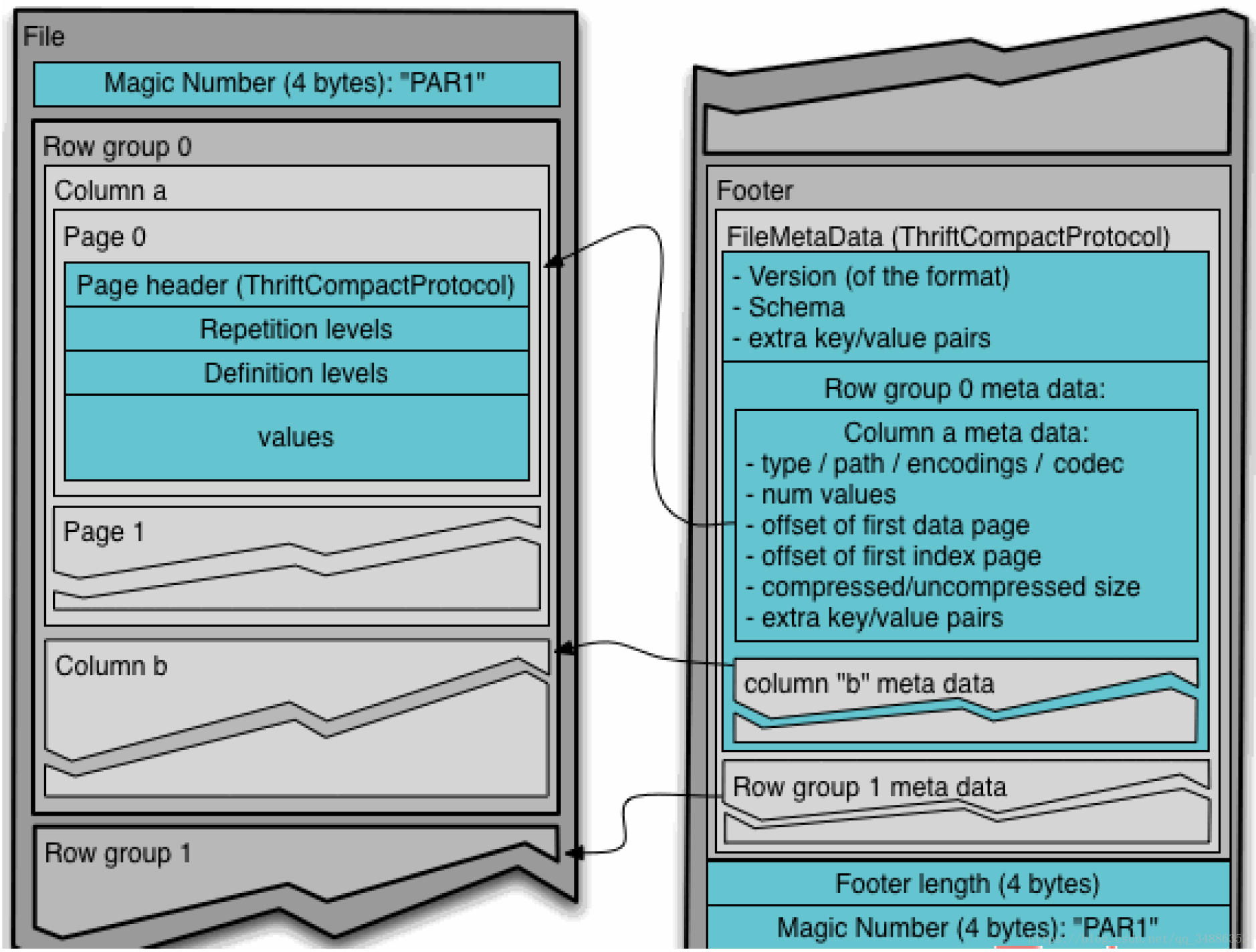
一个文件中可以存储多个行组,文件的首位都是该文件MagicCode,用于校验它是否是一个Parquet文件,Footer length记录了文件元数据的大小,通过该值和文件长度可以计算出元数据的偏移量,文件的元数据中包括每一个行组的元数据信息,和该文件存储数据的Schema信息。除了文件中每一个行组的元数据,每一夜的开始都会存储该页的元数据,在Parquet中,有三种类型的页:数据页、字典页和索引页。数据页用于存储当前行组中该列的值,字典页存储该列值的编码字典,每一个列块中最多包含一个字典页,索引页用来存储当前行组下该列的索引。
6.主流文件存储格式对比
-
存储文件压缩比:ORC>Parquet>TextFile
-
存储文件的速度对比:ORC>TextFile>Parquet(实际上三者几乎一样)