版权声明:董瑞 https://blog.csdn.net/qq_39226755/article/details/89355974
当我们初学深度学习时,对于激活函数和损失函数的选择并不了解,这里提出一些建议,需要注意的是,这里给的是最后一层的激活函数
| 问题类型 | 最后一层激活函数 | 损失函数 |
|---|---|---|
| 二分类问题 | sigmoid | binary_crossentropy |
| 多分类、单标签问题 | softmax | categorical_crossentropy |
| 多分类、多标签问题 | sigmoid | binary_crossentropy |
| 回归到任意值 | 无 | mse |
| 回归到 0~1 范围内的值 | sigmoid | mse 或 binary_crossentropy |
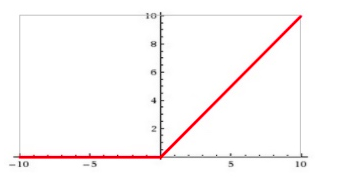
sigmoid激活函数:
函数公式如下:

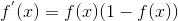
函数图像如下:

优点:
-
Sigmoid的取值范围在(0, 1),而且是单调递增,比较容易优化
-
Sigmoid求导比较容易,可以直接推导得出。
缺点:
- Sigmoid函数收敛比较缓慢
- 由于Sigmoid是软饱和,容易产生梯度消失,对于深度网络训练不太适合(从图上sigmoid的导数可以看出当x趋于无穷大的时候,也会使导数趋于0)
- Sigmoid函数并不是以(0,0)为中心点
softmax函数:
公式:
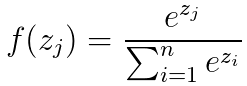
举个例子,通过若干层的计算,在输出层,最后得到的某个训练样本的向量的分数是[ 1, 5, 3 ], 那么概率分别就是:
下图说明,softmax函数是怎么计算的

tanH函数:
公式:
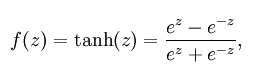
函数图像:

双切正切函数,取值范围为[-1,1],tanh在特征相差明显时的效果会很好,在循环过程中会不断扩大特征效果。与 sigmoid 的区别是,tanh 是 0 均值的,因此实际应用中 tanh 会比 sigmoid 更好。
relu函数:
ReLu是神经网络中的一个激活函数,其优于tanh和sigmoid函数。
引入relu函数的原因:
- 采用sigmoid等函数,算激活函数时(指数运算),计算量大,反向传播求误差梯度时,求导涉及除法,计算量相对大,而采用Relu激活函数,整个过程的计算量节省很多。
- 对于深层网络,sigmoid函数反向传播时,很容易就会出现 梯度消失 的情况(在sigmoid接近饱和区时,变换太缓慢,导数趋于0,这种情况会造成信息丢失),从而无法完成深层网络的训练。
- ReLu会使一部分神经元的输出为0,这样就造成了 网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生。
函数:
f(x)=max(0,x)
函数图像: