Python(sklearn-LogisticRegression)
LogisticRegression(特征选择+学习曲线+参数寻优+建立模型)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import datasets,preprocessing
from sklearn.model_selection import learning_curve
from sklearn.model_selection import train_test_split,GridSearchCV,cross_val_score
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score,classification_report,confusion_matrix
import warnings
warnings.filterwarnings('ignore')
dataset = datasets.load_breast_cancer()
X,y = dataset.data,dataset.target
x = preprocessing.StandardScaler().fit_transform(X)
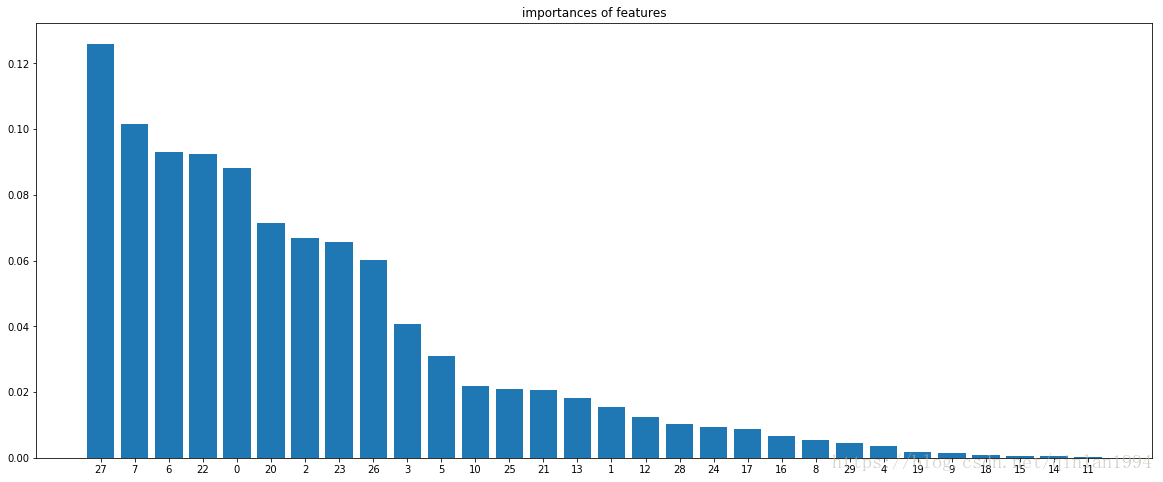
#特征选择(绘图)
clf = ExtraTreesClassifier(n_estimators=100,criterion='gini',max_depth=4)
clf.fit(x,y)
index = np.flipud(np.argsort(clf.feature_importances_))
score = clf.feature_importances_[index]
fig,ax = plt.subplots(figsize=(20,8))
plt.bar(range(len(index)),score,align='center')
plt.xticks(range(len(index)),index)
plt.title('importances of features')
plt.show()
sx = x[:,index[0:10]]
samples = np.array([510,500,400,300])
train_sizes,train_scores,validation_scores = learning_curve(LogisticRegression(dual=False,solver='liblinear'),sx,y,train_sizes=samples,cv=10)
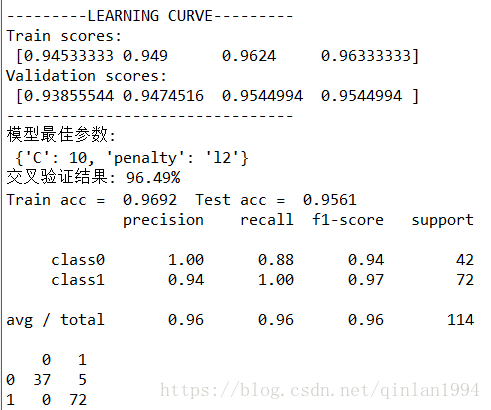
print('---------LEARNING CURVE---------')
print('Train scores:\n',np.mean(train_scores,axis=1))
print('Validation scores:\n',np.mean(validation_scores,axis=1))
print('--------------------------------')
x_train,x_test,y_train,y_test = train_test_split(sx,y,test_size=0.2,random_state=1)
#参数寻优
params = {
'penalty':['l1','l2'],
'C':[0.01,0.1,1.0,10,100,1000]
}
clf = GridSearchCV(LogisticRegression(dual=False,solver='liblinear'),params)
clf.fit(x_train,y_train)
print('模型最佳参数:\n',clf.best_params_)
#交叉验证
scores = cross_val_score(LogisticRegression(penalty='l1',C=100),x_train,y_train,scoring='accuracy',cv=10)
print('交叉验证结果:',str(round(100*scores.mean(),2))+'%')
#建模
model = LogisticRegression(penalty='l1',C=10)
model.fit(x_train,y_train)
predict_train = clf.predict(x_train)
train_acc = round(accuracy_score(y_train,predict_train),4)
predict_test = clf.predict(x_test)
test_acc = round(accuracy_score(y_test,predict_test),4)
print('Train acc = ',train_acc,' Test acc = ',test_acc)
print(classification_report(y_test,predict_test,target_names=['class0','class1']))
result = pd.DataFrame(confusion_matrix(y_test,predict_test),index=[0,1],columns=[0,1])
print(result)