LogisticRegression
LogisticRegression最基本的学习算法是最大似然。啥叫最大似然,可以看看我的另一篇博文“从最大似然到EM算法浅解”。假设我们有n个独立的训练样本{(x1, y1) ,(x2, y2),…, (xn, yn)},y={0, 1}。那每一个观察到的样本(xi, yi)出现的概率是:
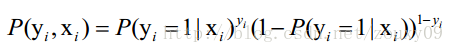
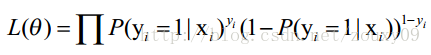
那最大似然法就是求模型中使得似然函数最大的系数取值θ*。这个最大似然就是我们的代价函数(cost function)了
我们先变换下L(θ)得到:
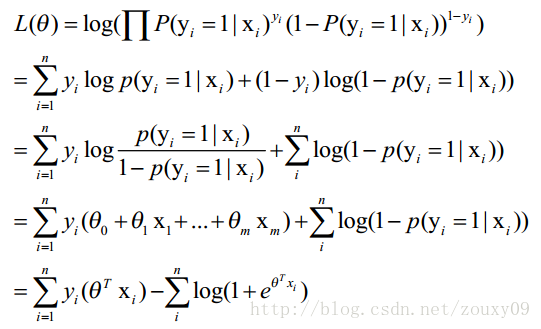
这时候,用L(θ)对θ求导,得到:
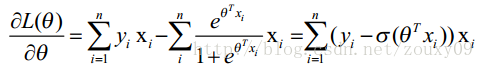
但是这个不好求,所以采用梯度下降算法
对logistic Regression来说,梯度下降算法新鲜出炉,如下:
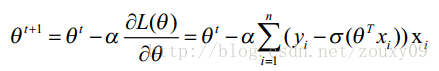
程序如下:
import numpy as np import math from sklearn import datasets from sklearn.model_selection import train_test_split import matplotlib.pyplot as plt def sigmoid(x): #sigmoid函数 return 1.0/(1+math.exp(-x)) class log_Regression: def __init__(self): self.iter_time=600 #迭代次数 self.alphal= 0.01 # 迭代步长 def cal_weight(self,x_train,y_train): x_train=np.mat(x_train) y_train=np.mat(y_train) m,n=np.shape(x_train) weight=np.zeros((n,1)) for k in range(self.iter_time): i=np.random.randint(0,m) h=sigmoid(x_train[i,:]*weight) error=h-y_train[0,i] weight+=self.alphal*x_train[i,:].transpose()*error#transpose是矩阵的转置,2个矩阵相加,要求行列一样 return weight def calAccuracyRate(self,x_test, y_test, weight): x_test=np.mat(x_test) y_test=np.mat(y_test) number=np.shape(y_test)[1] count = 0 # 记录划分正确的样本数 numSamples, numFeatures = np.shape(x_test) # 获取训练样本的规模 for i in range(numSamples): h = sigmoid(x_test[i, :] * weight) if h >= 0.5 and int(y_test[0,i]) == 1: count = count + 1 elif h < 0.5 and y_test[0,i] == 0: count = count + 1 return count/number def load_data(): data=datasets.load_iris()#因为logistic Regression 的标签必须非0即1 data_x=data['data'][0:99] data_y=data['target'][0:99] x_train,y_train,x_test,y_test=train_test_split(data_x,data_y,test_size=0.4) return x_train,y_train,x_test,y_test def main(): x_train, y_train, x_test, y_test=load_data() logistic=log_Regression() weight=logistic.cal_weight(x_train,x_test) count=logistic.calAccuracyRate(y_train,y_test,weight) print('精度是:',count) if __name__=='__main__': main()
结果显示:
精度是: 0.5