逻辑回归(二分类)是一种广义的线性回归(同样存在过拟合的可能),逻辑回归的目标值通过sigmoid函数转换成0-1之间的概率值,以0.5作为阈值变成二分类问题。 (二分类问题的概率与自变量之间的关系图形往往是一个S型曲线(sigmoid函数))
逻辑回归:线性回归的输入---sigmoid函数---0到1之间的概率值---0.5阈值---真、假(二分类)
二分类中,通常把小概率类别作为目标概率。
sigmoid函数公式: , e是自然常数(2.71828)。图形如下:

逻辑回归公式:

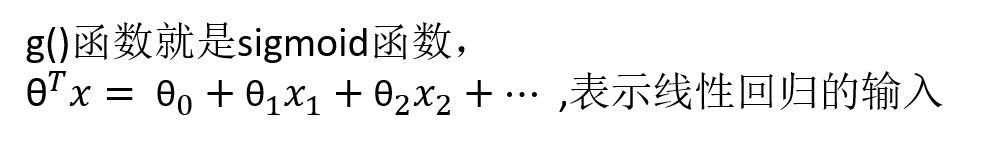
输出结果是[0, 1]之间的概率值,默认0.5作为阈值。

线性回归(包括岭回归)使用的损失函数是均方误差,不会存在多个局部最小值的情况。
逻辑回归使用的是对数似然损失函数,可能会存在多个局部最小值的情况,在通过梯度下降求解回归系数时,可能得到不同的局部最小值(不一定是全局最小值)。
逻辑回归通过梯度下降得到损失函数局部最小值而不是全局最小值的解决办法?
1、进行多次梯度下降求解(梯度下降的初始回归系数是随机的),综合比较所有结果。
2、调整学习速率(步长)
注意:这些方法并不能绝对找到全局最小值,但是在应用中的效果还不错。
demo.py(二分类,逻辑回归,LogisticRegression,预测癌症):
import pandas as pd
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import classification_report
# 二分类,逻辑回归 癌症预测(根据细胞的属性特征)
# 构造列标签名字
column_names = ['Sample code number','Clump Thickness', 'Uniformity of Cell Size','Uniformity of Cell Shape','Marginal Adhesion', 'Single Epithelial Cell Size','Bare Nuclei','Bland Chromatin','Normal Nucleoli','Mitoses','Class']
# 读取数据 (如果不指定标签名,会默认把第一行数据当成标签名)
data = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data", names=column_names)
print(data)
# 缺失值进行处理 (原始数据中的?表示缺失值)
data = data.replace(to_replace='?', value=np.nan)
data = data.dropna() # 删除有缺少值的行
# 分割数据集 划分为训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(data[column_names[1:10]], data[column_names[10]], test_size=0.25) # 第一列是id不需要,最后一列是目标值
# 进行标准化处理 因为目标结果经过sigmoid函数转换成了[0,1]之间的概率,所以目标值不需要进行标准化。
std = StandardScaler()
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test)
# 逻辑回归预测
lg = LogisticRegression(C=1.0) # 默认使用L2正则化避免过拟合,C=1.0表示正则力度(超参数,可以调参调优)
lg.fit(x_train, y_train)
# 回归系数
print(lg.coef_) # [[1.12796779 0.28741414 0.66944043 ...]]
# 进行预测
y_predict = lg.predict(x_test)
print("准确率:", lg.score(x_test, y_test)) # 0.964912280702
print("召回率:", classification_report(y_test, y_predict, labels=[2, 4], target_names=["良性", "恶性"]))
# 原始数据中的目标值:2表示良性,4表示恶性
'''
precision recall f1-score support
良性 0.97 0.98 0.98 111
恶性 0.97 0.95 0.96 60
avg/total 0.97 0.97 0.97 171
'''
逻辑回归的主要应用:广告点击率预测、疾病预测、垃圾邮件、电商购物搭配推荐(是否会购买某个商品)
优点:适合需要得到一个分类概率的场景,简单,速度快
缺点:不好处理多分类问题
逻辑回归处理多分类问题:
逻辑回归解决办法:1V1,1Vall (不推荐使用逻辑回归处理多分类问题)

先判断是否是三角形,再判断是否是正方形。
神经网络(图像识别)中通过softmax方法可以解决逻辑回归在多分类问题上的应用。