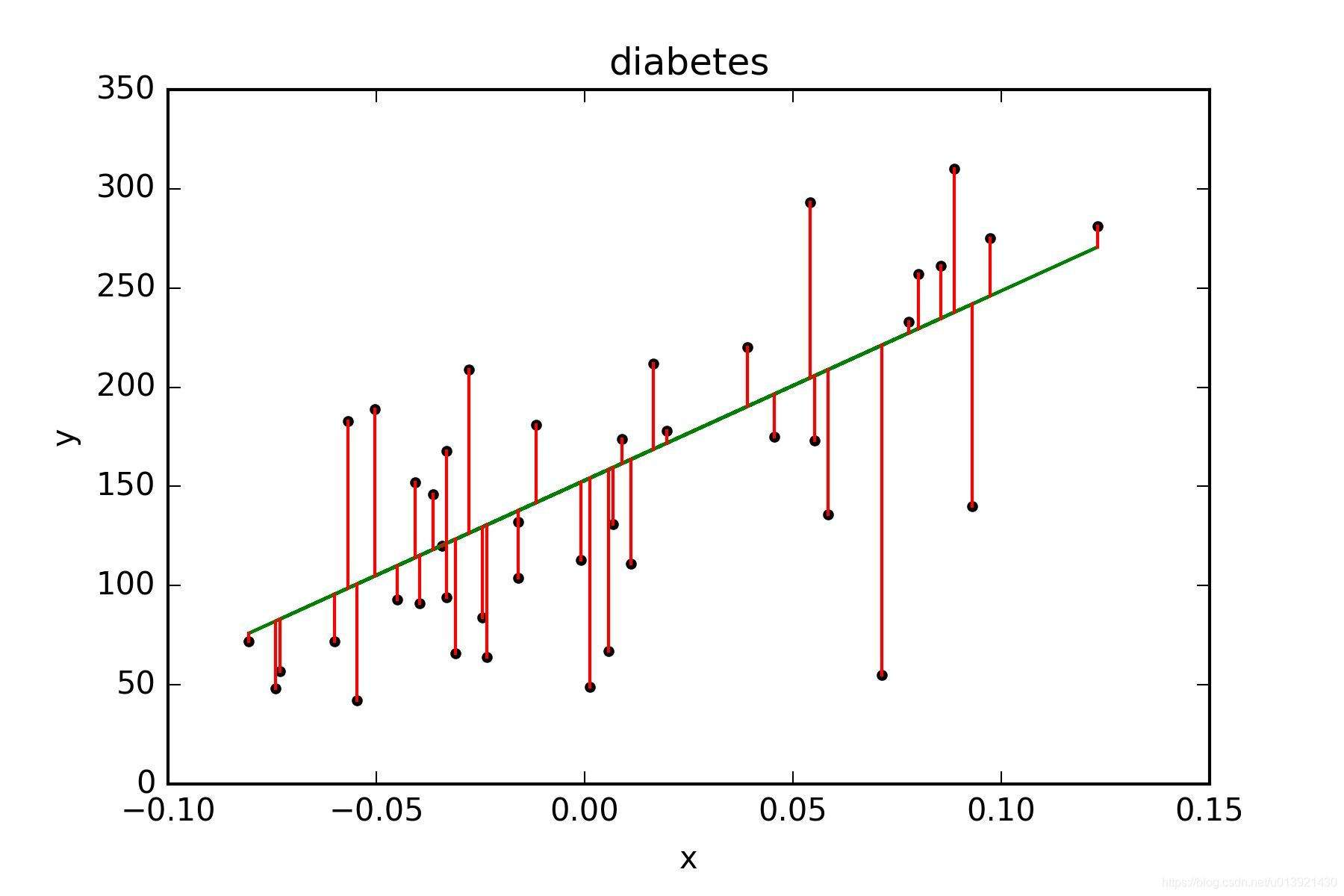
当我们有
N
N
N
那么,什么是最小二乘法呢?将我们手中已有的数据表示成一个集合,(为了简化模型,暂且只考虑输入属性只有
x
x
x
D
=
{
(
x
1
;
y
1
)
,
(
x
2
;
y
2
)
,
⋯
 
,
(
x
n
;
y
n
)
}
D=\left \{ (x_{1};y_{1}),(x_{2};y_{2}),\cdots ,(x_{n};y_{n}) \right \}
D = { ( x 1 ; y 1 ) , ( x 2 ; y 2 ) , ⋯ , ( x n ; y n ) }
y
=
a
x
+
b
y=ax+b
y = a x + b
e
i
=
∥
a
x
i
+
b
−
y
i
∥
e_{i}=\left \| ax_{i}+b-y_{i} \right \|
e i = ∥ a x i + b − y i ∥
e
i
e_{i}
e i
(
a
∗
,
b
∗
)
(a^{*},b^{*})
( a ∗ , b ∗ )
e
i
e_{i}
e i
(
a
∗
,
b
∗
)
=
a
r
g
m
i
n
(
a
,
b
)
∑
i
=
1
n
∥
a
x
i
+
b
−
y
i
∥
(a^{*},b^{*})=\underset{(a,b)}{argmin}\sum_{i=1}^{n}\left \| ax_{i}+b-y_{i} \right \|
( a ∗ , b ∗ ) = ( a , b ) a r g m i n i = 1 ∑ n ∥ a x i + b − y i ∥
(
a
∗
,
b
∗
)
=
a
r
g
m
i
n
(
a
,
b
)
∑
i
=
1
n
(
a
x
i
+
b
−
y
i
)
2
(a^{*},b^{*})=\underset{(a,b)}{argmin}\sum_{i=1}^{n} (ax_{i}+b-y_{i} )^{2}
( a ∗ , b ∗ ) = ( a , b ) a r g m i n i = 1 ∑ n ( a x i + b − y i ) 2
首先还是来看上面提到的最简单的情况。令;
E
(
a
,
b
)
=
∑
i
=
1
n
(
a
x
i
+
b
−
y
i
)
2
E(a,b)=\sum_{i=1}^{n} (ax_{i}+b-y_{i} )^{2}
E ( a , b ) = i = 1 ∑ n ( a x i + b − y i ) 2
E
E
E
a
a
a
b
b
b
E
E
E
(
a
,
b
)
(a,b)
( a , b )
(
a
,
b
)
(a,b)
( a , b )
E
E
E
E
E
E
a
a
a
b
b
b
∂
E
∂
a
=
2
∑
i
=
1
n
(
a
x
i
+
b
−
y
i
)
x
i
=
2
(
∑
i
=
1
n
a
x
i
2
+
∑
i
=
1
n
b
x
i
−
∑
i
=
1
n
y
i
x
i
)
=
2
(
∑
i
=
1
n
a
x
i
2
+
b
∗
n
x
ˉ
−
∑
i
=
1
n
y
i
x
i
)
\begin{aligned} \frac{\partial E}{\partial a}&=2\sum_{i=1}^{n} (ax_{i}+b-y_{i} )x_{i}\\ &=2(\sum_{i=1}^{n} ax_{i}^{2}+\sum_{i=1}^{n}bx_{i}-\sum_{i=1}^{n}y_{i}x_{i})\\&=2(\sum_{i=1}^{n} ax_{i}^{2}+b*n\bar{x}-\sum_{i=1}^{n}y_{i}x_{i}) \end{aligned}
∂ a ∂ E = 2 i = 1 ∑ n ( a x i + b − y i ) x i = 2 ( i = 1 ∑ n a x i 2 + i = 1 ∑ n b x i − i = 1 ∑ n y i x i ) = 2 ( i = 1 ∑ n a x i 2 + b ∗ n x ˉ − i = 1 ∑ n y i x i )
∂
E
∂
b
=
2
∑
i
=
1
n
(
a
x
i
+
b
−
y
i
)
=
2
(
a
∗
n
x
ˉ
+
n
b
−
n
y
ˉ
)
\frac{\partial E}{\partial b}=2\sum_{i=1}^{n} (ax_{i}+b-y_{i} )=2(a*n\bar{x}+nb-n\bar{y})
∂ b ∂ E = 2 i = 1 ∑ n ( a x i + b − y i ) = 2 ( a ∗ n x ˉ + n b − n y ˉ )
∂
E
∂
a
=
0
,
∂
E
∂
b
=
0
\frac{\partial E}{\partial a}=0,\frac{\partial E}{\partial b}=0
∂ a ∂ E = 0 , ∂ b ∂ E = 0
a
=
∑
i
=
1
n
x
i
y
i
−
n
x
ˉ
y
ˉ
∑
i
=
1
n
x
i
2
−
n
x
ˉ
2
a=\frac{\sum_{i=1}^{n}x_{i}y_{i}-n\bar{x}\bar{y}}{\sum_{i=1}^{n}x_{i}^{2}-n\bar{x}^{2}}
a = ∑ i = 1 n x i 2 − n x ˉ 2 ∑ i = 1 n x i y i − n x ˉ y ˉ
b
=
y
ˉ
−
a
x
ˉ
=
y
ˉ
∑
i
=
1
n
x
i
2
−
x
ˉ
∑
i
=
1
n
x
i
y
i
∑
i
=
1
n
x
i
2
−
n
x
ˉ
2
b=\bar{y}-a\bar{x}=\frac{\bar{y}\sum_{i=1}^{n}x_{i}^{2}-\bar{x}\sum_{i=1}^{n}x_{i}y_{i}}{\sum_{i=1}^{n}x_{i}^{2}-n\bar{x}^{2}}
b = y ˉ − a x ˉ = ∑ i = 1 n x i 2 − n x ˉ 2 y ˉ ∑ i = 1 n x i 2 − x ˉ ∑ i = 1 n x i y i
∑
i
=
1
n
(
x
i
−
x
ˉ
)
(
y
i
−
y
ˉ
)
=
∑
i
=
1
n
(
x
i
y
i
−
x
i
y
ˉ
−
y
i
x
ˉ
+
x
ˉ
y
ˉ
)
=
∑
i
=
1
n
x
i
y
i
−
y
ˉ
∑
i
=
1
n
x
i
−
x
ˉ
∑
i
=
1
n
y
i
+
n
x
ˉ
y
ˉ
=
∑
i
=
1
n
x
i
y
i
−
n
x
ˉ
y
ˉ
\begin{aligned} \sum_{i=1}^{n}(x_{i}-\bar{x})(y_{i}-\bar{y})&=\sum_{i=1}^{n}(x_{i}y_{i}-x_{i}\bar{y}-y_{i}\bar{x}+\bar{x}\bar{y})\\ &=\sum_{i=1}^{n}x_{i}y_{i}-\bar{y}\sum_{i=1}^{n}x_{i}-\bar{x}\sum_{i=1}^{n}y_{i}+n\bar{x}\bar{y}\\ &=\sum_{i=1}^{n}x_{i}y_{i}-n\bar{x}\bar{y} \end{aligned}
i = 1 ∑ n ( x i − x ˉ ) ( y i − y ˉ ) = i = 1 ∑ n ( x i y i − x i y ˉ − y i x ˉ + x ˉ y ˉ ) = i = 1 ∑ n x i y i − y ˉ i = 1 ∑ n x i − x ˉ i = 1 ∑ n y i + n x ˉ y ˉ = i = 1 ∑ n x i y i − n x ˉ y ˉ
∑
i
=
1
n
(
x
i
−
x
ˉ
)
2
=
∑
i
=
1
n
x
i
2
−
n
x
ˉ
2
\sum_{i=1}^{n}(x_{i}-\bar{x})^{2}=\sum_{i=1}^{n}x_{i}^{2}-n\bar{x}^{2}
i = 1 ∑ n ( x i − x ˉ ) 2 = i = 1 ∑ n x i 2 − n x ˉ 2
a
a
a
a
=
∑
i
=
1
n
(
x
i
−
x
ˉ
)
(
y
i
−
y
ˉ
)
∑
i
=
1
n
(
x
i
−
x
ˉ
)
2
a=\frac{\sum_{i=1}^{n}(x_{i}-\bar{x})(y_{i}-\bar{y})}{\sum_{i=1}^{n}(x_{i}-\bar{x})^{2}}
a = ∑ i = 1 n ( x i − x ˉ ) 2 ∑ i = 1 n ( x i − x ˉ ) ( y i − y ˉ )
上述的推导中输入属性数目为一,在一般的情况下,样本的属性会有多个,所以通过矩阵的形式将上述推导过程进行推广。假设数据集
D
D
D
d
d
d
i
i
i
(
x
i
1
;
x
i
2
;
⋯
 
;
x
i
d
;
y
)
(x_{i}^{1};x_{i}^{2};\cdots ;x_{i}^{d};y)
( x i 1 ; x i 2 ; ⋯ ; x i d ; y )
x
i
{\textbf{x}}_{i}
x i
d
d
d
w
{\textbf{w}}
w
x
i
=
(
x
i
1
;
x
i
2
;
⋯
 
;
x
i
d
)
{\textbf{x}}_{i}=(x_{i}^{1};x_{i}^{2};\cdots ;x_{i}^{d})
x i = ( x i 1 ; x i 2 ; ⋯ ; x i d )
w
=
(
w
1
;
w
2
;
⋯
 
;
w
d
)
{\textbf{w}}=(w_{1};w_{2};\cdots ;w_{d})
w = ( w 1 ; w 2 ; ⋯ ; w d )
f
(
x
i
)
=
w
T
x
i
+
b
f({\textbf{x}}_{i})={\textbf{w}}^{T}{\textbf{x}}_{i}+b
f ( x i ) = w T x i + b
w
^
=
(
w
;
b
)
\hat{\textbf{w}}=({\textbf{w}};b)
w ^ = ( w ; b )
x
{\textbf{x}}
x
x
i
=
(
x
i
1
;
x
i
2
;
⋯
 
;
x
i
d
;
1
)
{\textbf{x}}_{i}=(x_{i}^{1};x_{i}^{2};\cdots ;x_{i}^{d};1)
x i = ( x i 1 ; x i 2 ; ⋯ ; x i d ; 1 )
f
(
x
i
)
=
w
^
T
x
i
f({\textbf{x}}_{i})=\hat{\textbf{w}}^{T}{\textbf{x}}_{i}
f ( x i ) = w ^ T x i
X
=
(
x
1
1
x
1
2
⋯
x
1
d
1
x
2
1
x
2
2
⋯
x
2
d
1
⋮
⋱
⋱
⋮
⋮
x
n
1
x
n
2
⋯
x
n
d
1
)
=
(
x
1
T
1
x
2
T
1
⋮
⋮
x
n
T
1
)
{\textbf{X}}=\begin{pmatrix} x_{1}^{1} & x_{1}^{2} & \cdots & x_{1}^{d} &1 \\ x_{2}^{1} & x_{2}^{2} & \cdots & x_{2}^{d} &1\\ \vdots & \ddots & \ddots &\vdots & \vdots \\ x_{n}^{1} & x_{n}^{2} & \cdots & x_{n}^{d} &1 \end{pmatrix}=\begin{pmatrix} {\textbf{x}}_{1}^{T} &1 \\ {\textbf{x}}_{2}^{T} &1 \\ \vdots &\vdots \\ {\textbf{x}}_{n}^{T} & 1 \end{pmatrix}
X = ⎝ ⎜ ⎜ ⎜ ⎛ x 1 1 x 2 1 ⋮ x n 1 x 1 2 x 2 2 ⋱ x n 2 ⋯ ⋯ ⋱ ⋯ x 1 d x 2 d ⋮ x n d 1 1 ⋮ 1 ⎠ ⎟ ⎟ ⎟ ⎞ = ⎝ ⎜ ⎜ ⎜ ⎛ x 1 T x 2 T ⋮ x n T 1 1 ⋮ 1 ⎠ ⎟ ⎟ ⎟ ⎞
y
=
(
y
1
;
y
2
;
⋯
 
;
y
n
)
{\textbf{y}}=({y}_{1};{y}_{2};\cdots;{y}_{n})
y = ( y 1 ; y 2 ; ⋯ ; y n )
w
^
∗
=
a
r
g
 
m
i
n
w
^
(
y
−
X
w
^
)
T
(
y
−
X
w
^
)
\hat{\textbf{w}}^{*}=\underset{\hat{\textbf{w}}}{arg\, min}({\textbf{y}}-{\textbf{X}}\hat{\textbf{w}})^{T}({\textbf{y}}-{\textbf{X}}\hat{\textbf{w}})
w ^ ∗ = w ^ a r g m i n ( y − X w ^ ) T ( y − X w ^ )
E
=
(
y
−
X
w
^
)
T
(
y
−
X
w
^
)
E=({\textbf{y}}-{\textbf{X}}\hat{\textbf{w}})^{T}({\textbf{y}}-{\textbf{X}}\hat{\textbf{w}})
E = ( y − X w ^ ) T ( y − X w ^ )
w
^
\hat{\textbf{w}}
w ^
∂
E
∂
w
^
=
2
X
T
(
X
w
^
−
y
)
\frac{\partial E}{\partial \hat{\textbf{w}}}=2{\textbf{X}}^{T}({\textbf{X}}\hat{\textbf{w}}-\textbf{y})
∂ w ^ ∂ E = 2 X T ( X w ^ − y )
w
^
∗
=
(
X
T
X
)
−
1
X
T
y
\hat{\textbf{w}}^{*}=({\textbf{X}}^{T}{\textbf{X}})^{-1}{\textbf{X}}^{T}\textbf{y}
w ^ ∗ = ( X T X ) − 1 X T y
更一般的,可以将这种线性回归用于非线性函数的拟合;例如对于对数函数;
f
(
x
i
)
=
y
=
l
n
(
w
T
x
i
+
b
)
f({\textbf{x}}_{i})=y=ln({\textbf{w}}^{T}{\textbf{x}}_{i}+b)
f ( x i ) = y = l n ( w T x i + b )
h
=
e
y
=
w
T
x
i
+
b
h=e^{y}={\textbf{w}}^{T}{\textbf{x}}_{i}+b
h = e y = w T x i + b
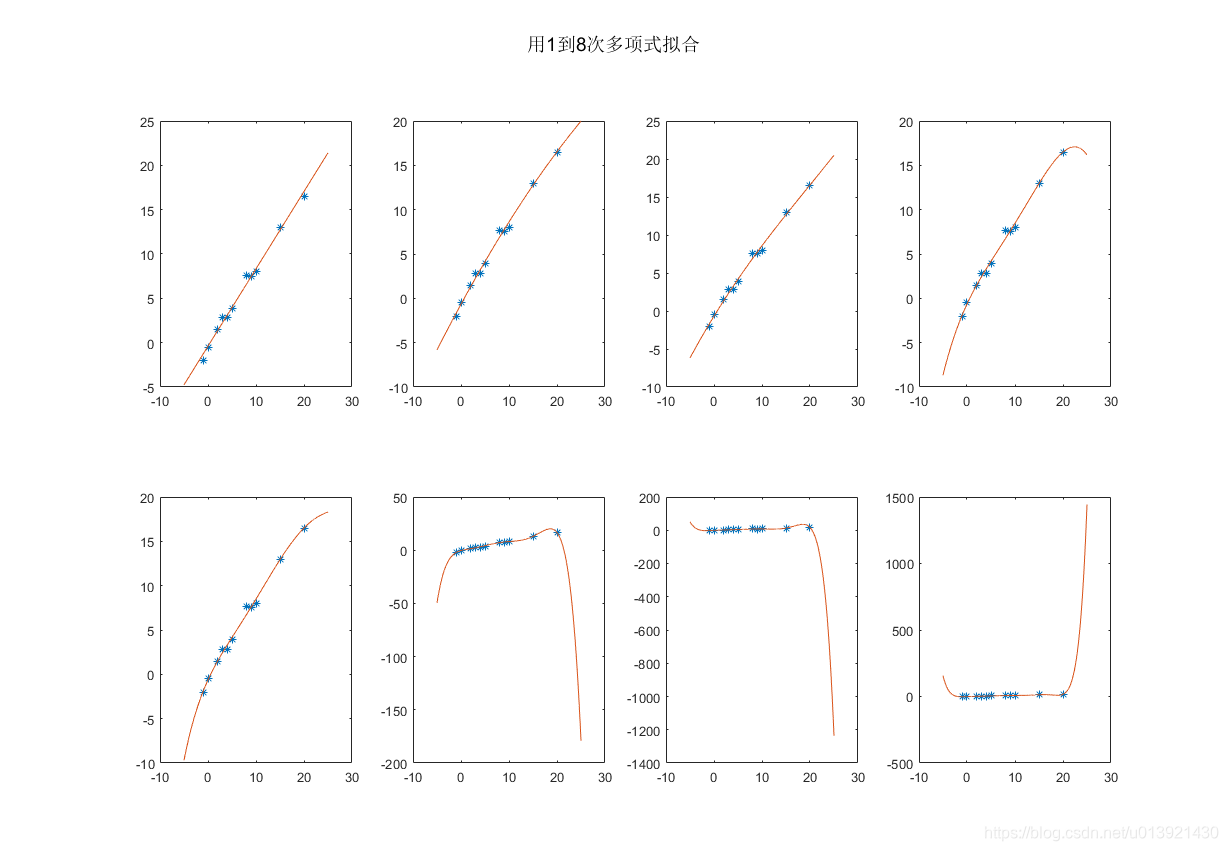
甚至可以用最小二乘法拟合多项式曲线。
y
=
a
0
+
a
1
x
+
a
2
x
2
+
⋯
+
a
m
x
m
y=a_{0}+a_{1}x+a_{2}x^{2}+\cdots +a_{m}x^{m}
y = a 0 + a 1 x + a 2 x 2 + ⋯ + a m x m
X
=
(
x
1
m
x
1
m
−
1
⋯
x
1
1
1
x
2
m
x
2
m
−
1
⋯
x
2
1
1
⋮
⋱
⋱
⋮
⋮
x
n
m
x
n
m
−
1
⋯
x
n
1
1
)
{\textbf{X}}=\begin{pmatrix} x_{1}^{m} & x_{1}^{m-1} & \cdots & x_{1}^{1} &1 \\ x_{2}^{m} & x_{2}^{m-1} & \cdots & x_{2}^{1} &1\\ \vdots & \ddots & \ddots &\vdots & \vdots \\ x_{n}^{m} & x_{n}^{m-1} & \cdots & x_{n}^{1} &1 \end{pmatrix}
X = ⎝ ⎜ ⎜ ⎜ ⎛ x 1 m x 2 m ⋮ x n m x 1 m − 1 x 2 m − 1 ⋱ x n m − 1 ⋯ ⋯ ⋱ ⋯ x 1 1 x 2 1 ⋮ x n 1 1 1 ⋮ 1 ⎠ ⎟ ⎟ ⎟ ⎞
m
m
m
m
m
m
m
m
m
X
{\textbf{X}}
X
w
^
∗
\hat{\textbf{w}}^{*}
w ^ ∗
w
^
∗
=
(
X
T
X
)
−
1
X
T
y
\hat{\textbf{w}}^{*}=({\textbf{X}}^{T}{\textbf{X}})^{-1}{\textbf{X}}^{T}\textbf{y}
w ^ ∗ = ( X T X ) − 1 X T y
用Matlab实现了最小二乘法一元高次多项式拟合;代码如下;
**%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%不用先生,2018.11.22,最小二乘法一元高次多项式拟合
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
clc;
clear all;
xi=[-1,0,2,3,4,5,8,9,10,15,20];
yi=[-2,-0.5,1.5,2.8,2.8,3.9,7.6,7.5,8,13,16.5];
[~,n]=size(xi);
m=8; %%最高8次多项式;
W=zeros(m+1,m);
for i=1:m
X=zeros(n,i+1); %%创建一个n*+1的矩阵;
for j=1:n
for s=1:i
X(j,s)=xi(j)^(i+1-s); %%计算矩阵中每一个元素的值
end
X(j,i+1)=1;
end
XX=inv(X'*X)*X'*yi'; %%得到系数并赋值
for j=1:i+1
W(j,i)=XX(j);
end
end
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%构造方程,画图
x=-5:0.01:25;
for i=1:m
y=W(1,i)*x.^i;
for j=2:i+1
y=y+W(j,i)*x.^(i-j+1);
end
subplot(2,4,i);
plot(xi,yi,'*');
hold on;
plot(x,y);
hold off
end
suptitle('用1到8次多项式拟合')
**
《机器学习》,周志华 著,清华大学出版社;
已完。。