GBDT+LR算法最早是由Facebook在2014年提出的一个推荐算法,该算法分两部分构成,第一部分是GBDT,另一部分是LR.下面先介绍GBDT算法,然后介绍如何将GBDT和LR算法融合
1.1 GBDT算法
GBDT的全称是 Gradient Boosting Decision Tree,梯度提升决策树。是Boost的一种典型算法,Boost的原理:首先对样本集进行训练得到第一个模型,然后对模型分类错误的样本进行提权得到新的样本集,在新的样本集上进行训练得到第二个模型,如此类推得到n个预测模型。预测的时候通过每个模型的预测值进行加权,模型的权重可以用模型的准确率衡量。
Decision Tree:CART回归树
GBDT使用的决策树就是CART回归树。
对于回归树算法来说最主要的是寻找最佳的划分点,那么回归树中的可划分点包含了所有特征的所有可取的值。在分类树中最佳划分点的判别标准是熵或者基尼系数,都是用纯度来衡量的,但是在回归树中的样本标签也是连续数值,所以再使用熵之类的指标不再合适,取而代之的是平方误差,它能很好的评判数据分散程度。我们希望最佳划分节点能够使得划分得到的两组数据组内的标签值相近,如果每组的方差都很小,这就说明每组的组内相似度很高,确实应该被划分。

从上图可以看出:利用方差寻找最佳划分点,预测值选择决策树的叶子节点中所有样本的真实值的均值。
Gradient Boosting: 负梯度——残差
假如有个人30岁,我们首先用20岁去拟合,发现损失有10岁,这时我们用6岁去拟合剩下的损失,发现差距还有4岁,第三轮我们用3岁拟合剩下的差距,差距就只有一岁了。如果我们的迭代轮数还没有完,可以继续迭代下面,每一轮迭代,拟合的岁数误差都会减小。
在GBDT的迭代中,假设我们前一轮迭代得到的强学习器是ft−1(x)ft−1(x), 损失函数是L(y,ft−1(x))L(y,ft−1(x)), 我们本轮迭代的目标是找到一个CART回归树模型的弱学习器ht(x)ht(x),让本轮的损失损失L(y,ft(x)=L(y,ft−1(x)+ht(x))L(y,ft(x)=L(y,ft−1(x)+ht(x))最小。也就是说,本轮迭代找到决策树,要让样本的损失尽量变得更小。
常见的损失函数:

GBDT选取了相对来说容易优化的损失函数——平方损失。针对怎样去拟合这个损失,大牛Freidman提出了用损失函数的负梯度来拟合本轮损失的近似值。第t轮的第i个样本的损失函数的负梯度为:
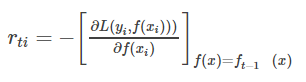
对应损失函数列表可知,GBDT使用的平方损失,经过负梯度拟合得到了y−f(xi)y−f(xi),这就是我们最终要去拟合的,它的另一个名字叫作残差。回到我们上面讲的那个通俗易懂的例子中,第一次迭代的残差是10岁,第二 次残差4岁……

1.初始化弱学习器
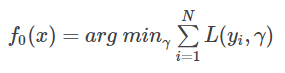
2.对迭代轮数m=1,2,…M有:
a)对每个样本i=1,2,…,N,计算负梯度,即残差
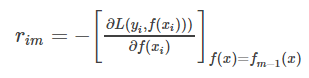
b)将上步得到的残差作为样本新的真实值,并将数据(xi,rim)(i=1,2,…N)(xi,rim)(i=1,2,…N)作为下棵树的训练数据,得到一颗新的回归树fm(x)fm(x)其对应的叶子节点区域为Rjm,j=1,2,…,JRjm,j=1,2,…,J。其中JJ为回归树t的叶子节点的个数。
c)对叶子区域j=1,2,…Jj=1,2,…J计算最佳拟合值
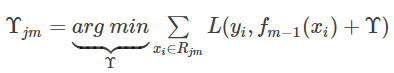
d)更新强学习器
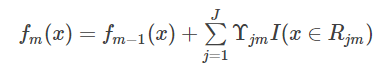
3.得到强学习器
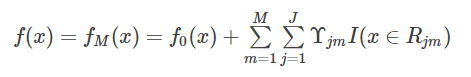
GBDT算法首先对训练样本建立一颗决策树,然后每个样本的目标变量调整为第一颗决策树预测值与实际值的残差,得到一个新的训练样本,在新的训练样本下建立第二课决策树,依次类推得到m颗决策树。详细构造如下:
Step1:数据准备,设原始的训练样本为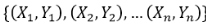
Step2:生成第1颗决策树,运用CART算法,对原始样本生成1颗决策树,第1颗决策树定义为,表示第1颗决策树对样本的预测值。
Step3:生成第2颗决策树,构造第2颗决策树的训练样本数据,对每个样本的目标变量用残差表示,具体如下,同样运用CART算法生成第2课决策树,第2颗决策树定义为DT2,DT2(Xi)表示第2颗决策树对样本Xi的预测值:

Step4:生成第m颗决策树,构造第m颗决策树的训练样本数据如下:
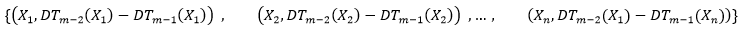
运用CART算法生成第m课决策树,第m颗决策树定义为DTm,DTm(Xi)表示第m颗决策树对样本Xi的预测值,预测的时候,将每一颗决策树的预测结果加起来就是GBDT模型的预测值。
GBDT是一个Boosting的模型,通过组合多个弱模型逐步拟合残差得到一个强模型。树模型具有天然的优势,能够很好的挖掘组合高阶统计特征,兼具较优的可解释性。GBDT的主要缺陷是依赖连续型的统计特征,对于高维度稀疏特征、时间序列特征不能很好的处理。
1.2 GBDT与LR融合的算法

Facebook提出来的论文当中,把样本在GBDT模型中决策树的叶子节点作为样本的特征,输入到LR模型里面。简单理解就是让GBDT模型来做特征工程。
1.3 扩展
沿着上述算法的思路,我们可以将one-hot离散化特征,以及BP模型融合到与GBDT并行的一层,在外面在接一层LR算法。这里面并行的模块有GBDT、one-hot离散化特征、BP,可以理解为3种不同方法的特征工程,结构图如下:

1.4实例代码
https://github.com/wolf-bailang/tensorflow_practice/tree/master/recommendation/GBDT%2BLR-Demo
参考来源
[1] http://quinonero.net/Publications/predicting-clicks-facebook.pdf
[2] http://blog.csdn.net/zpalyq110/article/details/79527653
[3] https://blog.csdn.net/kingzone_2008/article/details/81225385