转载内容
推荐系统遇上深度学习(十)--GBDT+LR融合方案实战 - 知乎 (zhihu.com)
GBDT+LR算法解析及Python实现 - Bo_hemian - 博客园 (cnblogs.com)
- GBDT+LR 最广泛的场景是CTR点击率预估,即预测当给用户推送的广告会不会被用户点击 。点击率预估模型涉及的训练样本一般是上亿级别,样本量大,模型常采用速度较快的LR。但LR是线性模型,学习能力有限,此时特征工程尤其重要。GBDT算法的特点正好可以用来发掘有区分度的特征、特征组合,减少特征工程中人力成本。
- GBDT:自动进行特征筛选和组合, 进而生成新的离散特征向量。
GBDT与传统的Boosting区别较大,它的每一次计算都是为了减少上一次的残差,而为了消除残差,我们可以在残差减小的梯度方向上建立模型,所以说,在GradientBoost中,每个新的模型的建立是为了使得之前的模型的残差往梯度下降的方法,与传统的Boosting中关注正确错误的样本加权有着很大的区别。
在GradientBoosting算法中,关键就是利用损失函数的负梯度方向在当前模型的值作为残差的近似值,进而拟合一棵CART回归树。
GBDT的会累加所有树的结果,而这种累加是无法通过分类完成的,因此GBDT的树都是CART回归树,而不是分类树(尽管GBDT调整后也可以用于分类但不代表GBDT的树为分类树)。GBDT的性能在RF的基础上又有一步提升,因此其优点也很明显
1、它能灵活的处理各种类型的数据;
2、在相对较少的调参时间下,预测的准确度较高。
由于它是Boosting,因此基学习器之前存在串行关系,难以并行训练数据。
- LR :将GBDT生成的离散特征向量当做LR模型的输入, 来产生最后的预测结果
GBDT + LR 融合

- 图中共有两棵树,x为一条输入样本,遍历两棵树后,x样本分别落到两颗树的叶子节点上,每个叶子节点对应LR一维特征,那么通过遍历树,就得到了该样本对应的所有LR特征。构造的新特征向量是取值0/1的。举例来说:上图有两棵树,左树有三个叶子节点,右树有两个叶子节点,最终的特征即为五维的向量。对于输入x,假设他落在左树第二个节点,编码[0,1,0],落在右树第二个节点则编码[0,1],所以整体的编码为[0,1,0,0,1],这类编码作为特征,输入到LR中进行分类。
- 在用GBDT构造新的训练数据时,采用的也正是One-hot方法。并且由于每一弱分类器有且只有一个叶子节点输出预测结果,所以在一个具有n个弱分类器、共计m个叶子结点的GBDT中,每一条训练数据都会被转换为1*m维稀疏向量,且有n个元素为1,其余m-n 个元素全为0。
- 新的训练数据构造完成后,将GBDT构造的训练数据和原始的训练数据中的label(输出)数据一并输入到Logistic Regression分类器中进行最终分类器的训练。思考一下,在对原始数据进行GBDT提取为新的数据这一操作之后,数据不仅变得稀疏,而且由于弱分类器个数,叶子结点个数的影响,可能会导致新的训练数据特征维度过大的问题,因此,在Logistic Regression这一层中,可使用正则化来减少过拟合的风险,在Facebook的论文中采用的是L1正则化。
代码
import pandas as pd
import lightgbm as lgb
from sklearn.preprocessing import OneHotEncoder
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingClassifier
import numpy as np
data = pd.read_csv('loan_data 银行借贷决策树.txt',sep='\s+',encoding='utf-8',index_col='nameid')
data.head()
data.columns
x = data.drop(['approve'],axis = 1).values
y = data['approve'].values
print(x.shape,y.shape)
x1 = x[:900]
y1 = y[:900]
x2 = x[900:]
y2 = y[900:]
X_train,X_test,y_train,y_test = train_test_split(x1,y1,test_size = 0.2)
gbm1 = GradientBoostingClassifier(n_estimators=50, random_state=10, subsample=0.6, max_depth=7,
min_samples_split=900)
gbm1.fit(X_train, y_train)
#用实际数据去实现GBDT特征的提取,
# model.apply(X_train),返回训练数据X_train在训练好的模型里每棵树中所处的叶子节点的位置(索引)
train_new_feature = gbm1.apply(X_train)
train_new_feature = train_new_feature.reshape(-1, 50)
# 转换成GBDT特征
#pandas中的 get_dummies()也可以实现独热编码
enc = OneHotEncoder()
enc.fit(train_new_feature)
train_new_feature2 = np.array(enc.transform(train_new_feature).toarray())
# create dataset for lightgbm
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)
params = {
'task': 'train',
'boosting_type': 'gbdt',
'objective': 'binary',
'metric': {'binary_logloss'},
'num_leaves': 64,
'num_trees': 100,
'learning_rate': 0.01,
'feature_fraction': 0.9,
'bagging_fraction': 0.8,
'bagging_freq': 5,
'verbose': 0
}
# number of leaves,will be used in feature transformation
num_leaf = 64
# train
gbm = lgb.train(params=params,
train_set=lgb_train,
valid_sets=lgb_train, )
# save model to file
gbm.save_model('model.txt')
# y_pred分别落在100棵树上的哪个节点上
y_pred = gbm.predict(X_train, pred_leaf=True)
#返回预测的每一类的概率
y_pred_prob = gbm.predict(X_train)
'''GradientBoostingClassifier默认生成的子树为100颗,
y_pred的每一列其实就是对应着样本在每一颗子树落到的叶子节点。'''
y_pred.shape
#(720, 100)
len(y_pred[1])#100,第二行的长度,也就是列的数目,子树为100颗
len(y_pred)#720 样本数量
len(y_pred[0])#100,第一行的长度,也就是列的数目,也是子树的数目
result = []
threshold = 0.5
for pred in y_pred_prob:
result.append(1 if pred > threshold else 0)
print('result:', result)
print('Writing transformed training data')
transformed_training_matrix = np.zeros([len(y_pred), len(y_pred[1]) * num_leaf],
dtype=np.int64) # N * num_tress * num_leafs
for i in range(0, len(y_pred)):
# temp表示在每棵树上预测的值所在节点的序号(0,64,128,...,6436 为100棵树的序号,中间的值为对应树的节点序号)
temp = np.arange(len(y_pred[0])) * num_leaf + np.array(y_pred[i])
# 构造one-hot 训练数据集
transformed_training_matrix[i][temp] += 1
#用测试集构造训练数据
y_pred = gbm.predict(X_test, pred_leaf=True)
print('Writing transformed testing data')
transformed_testing_matrix = np.zeros([len(y_pred), len(y_pred[1]) * num_leaf], dtype=np.int64)
for i in range(0, len(y_pred)):
temp = np.arange(len(y_pred[0])) * num_leaf + np.array(y_pred[i])
# 构造one-hot 测试数据集
transformed_testing_matrix[i][temp] += 1
#用LR进行预测
from sklearn.linear_model import LogisticRegression
lm = LogisticRegression(penalty='l2',C=0.05)
lm.fit(transformed_training_matrix,y_train)
# 每个类别的概率
y_pred_test = lm.predict_proba(transformed_testing_matrix)
y_pred_test效果评价
NE = (-1) / len(y_pred_test) * sum(((1+y_test)/2 * np.log(y_pred_test[:,1]) + (1-y_test)/2 * np.log(1 - y_pred_test[:,1])))
print("Normalized Cross Entropy " + str(NE))在Facebook的paper中,模型使用NE(Normalized Cross-Entropy),进行评价,计算公式如下:
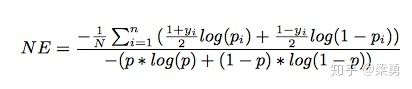
- 业务数据大多为大量离散特征导致的高维度离散数据。而树模型对离散特征处理不够好,容易导致过拟合。
