基于深度学习推荐系统
1. 基础知识
(1)one-hot编码带来的问题
我们知道,当我们遇到标签类/离散/类别型的数据,我们通过会把它变成one-hot编码。但是这样会使得数据特别庞大而且稀疏。而广告计算和推荐算法很多数据的特征是非常多的,而且大部分会是离散的数据,这样一来数据的稀疏性就会变得非常大。
因此,FM主要就是为了解决数据稀疏的情况下,特征怎样组合的问题。
(2)因式分解机(FM)
因式分解机是一种基于LR模型的高效的学习特征间相互关系;
对于因子分解机FM来说,最大的特点是对于稀疏的数据具有很好的学习能力。
FM的优点:
① FM模型可以在非常稀疏的数据中进行合理的参数估计;
② 在FM模型的复杂度是线性的,优化效果很好,而且不需要像SVM一样依赖于支持向量。
③ FM是一个通用模型,它可以用于任何特征为实值的情况。而其他的因式分解模型只能用于一些输入数据比较固定的情况。
(1)问题 1:为什么要做特征组合?
在推荐系统中,我们知道用户或者物品的特征之间是由相互关系的。如果我们能够知道特征之间的关联性,就能够更加合理的给用户推荐相关信息。
但是一般线性模型中,各个特征是独立考虑的。
LR模型: y = sigmoid(ω0 + ω1x1 + ω2x2 + …)
逻辑回归(LR模型):线性模型,每个特征对最终输出结果影响是独立的。
为了解决LR模型特征之间独立的问题,我们引入LR模型的改进,即加入手动特征交叉组合部分。
y = sigmoid(ω0 + ∑i ωi*xi + ∑i ∑j ωij *xi * xj)
但是这样的话就会使得在输入的特征如果有0的时候,就无法训练ωij。而我们前面说过,我们的特征数据非常稀疏,因此大部分都是0。
所以这个时候,FM算法出现了。
(2)问题 2:FM模型是如何做到特征组合的呢?
FM模型: y = ω0 + ∑i ωixi + ∑i ∑j <vi,vj>xixj
通过对每一个特征分量x 引入辅助向量v。然后,利用<vi,vj>对交叉项的系数ω进行估计。即ω=<vi,vj>,就可以实现即使x为0的情况下,也能够训练ω。
经过求解分解后,我们就可以通过随机梯度下降法SGD或者其他求最优解的算法进行求解。
我们可以看到,通过FM模型,我们解决了在数据比较稀疏的情况下,特征的组合问题。但是问题还是存在,数据庞大的问题还是存在,因此模型的时间复杂度难以解决。
(3)embedding嵌入层
在训练FM模型前,引入embedding层的作用就是为了解决数据庞大的问题。
embedding的本质就是用来对特征进行降维或者升维。
例如:将大量的特征,降低到一个定长的特征。我们的特征是10001000的特征矩阵,我们让他乘以一个100020的参数矩阵,就可以将特征缩小到1000*20,整整缩小了50倍。而且通过类似这样的操作,也使得特征之间产生关联性。
embedding层的两个特点:
① 输出的长度是定长的;
② embedding的参数是通过模型自己学习到的。
(4)引入DNN
我们知道深度学习的应用和更新,在逐步取代了机器学习的地位。深度学习在对特征的处理上有着无可匹敌的地位。因此,人们就想把DNN应用在推荐算法上。
首先提出的是FNN模型:
FNN:
FNN的基本原理就是先使用预先训练好的FM模型,得到隐向量,然后作为DNN的输入来训练模型。
FNN模型的缺点可想而知,我们通过FM模型进行的特征组合只有到二阶,是比较差的,因此FM预训练的效果并不是很好。
PNN
其次提出的是PNN模型:
详细PNN的网络设计 https://www.jianshu.com/p/be784ab4abc2
PNN的本质就是为了捕获高阶组合特征。
即在embedding和DNN层中间加入product layer,目的是通过product layer使用内积、外积、混合分别衍生出IPNN, OPNN, PNN*三种类型。
FNN和PNN,都有一个共同缺点:对于低阶的组合特征,学习到的比较少。而我们希望推荐系统不止看到低阶特征,同时也看到高阶特征。
而且embedding会导致几乎所有的预测值都是非0的,这就导致了推荐过度泛化,会推荐一些不那么相关的物品。
Wide&Deep
为了同时学习低阶和高阶组合的特征,google提出了Wide&Deep模型。
就是混合了一个线性模型(Wide)和一个deep模型。
wide模型和deep模型需要不同得输入。(没有共享输入)
Wide模型:Wide part部分的输入,依旧依赖人工特征工程。它的目的是提取低阶组合特征。
Deep模型:deep模型就是传统的一个dnn模型,就是将特征放入一个embedding层后,直接用MLP进行训练。提取特征。
然后将两个模型结合,经过输出层输出结果。
缺点:
- 偏向于提取低阶或者高阶的组合特征。不能同时提取这两种类型的特征。
- 需要专业的领域知识来做特征工程。
于是,我们将wide部分进行改进,用FM模型代替了wide模型。成功解决上面两个问题。并做出了其他的改进。
2. DeepFM模型
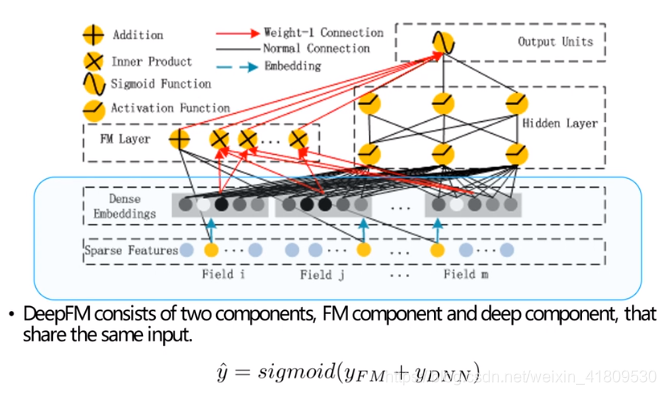
主要做法如下:
- FM Component + Deep Component。FM提取低阶组合特征,Deep提取高阶组合特征。但是和Wide&Deep不同的是,DeepFM是端到端的训练,不需要人工特征工程。
- 共享feature embedding。FM和Deep共享输入和feature embedding不但使得训练更快,而且使得训练更加准确。相比之下,Wide&Deep中,input vector非常大,里面包含了大量的人工设计的pairwise组合特征,增加了他的计算复杂度。
DeepFM整个模型各个模块是一起训练学习的,且Deep和FM共享输入,能够同时学习低阶和高阶组合特征,而不会像wide&deep,没有共享输入,模块是相互独立的,会导致过度学习低阶特征或者高阶特征。