Basic recipe for machine learning
理论基础
1、关于训练集和数据集
通常来说,训练一个机器学习算法模型,需要将数据分割成训练集和数据集两部分。训练集用来训练算法模型,测试集用来测试算法模型。80%数据进行训练,20%数据进行测试。
这样,在训练过程中会遇到高方差和高偏差的问题,会采用以下的方法进行改善,就对测试集的泛化误差进行了多次度量,并调整模型和超参数来得到你和那个测试集的最佳模型。在新的运行环境下,很明显不能得到一个好的误差。
所以,从数据集中再分出一个验证集,用来调整超参数和监控模型是否过拟合。
一般三者比例为:6:2:2.
开发和测试集应该来自同一分布
吴恩达课程的答案是98:1:1.。。。。。。
2、交叉验证
1、将数据集粗略的分为比较均等不相交的k份
2、取其中的一份进行测试,另外k-1份进行训练,然后求得error的平均值作为最终评价。
3、选择具有最小泛化误差的模型作为最终模型,并且在整个训练集上再次训练该模型,得到最终的模型。
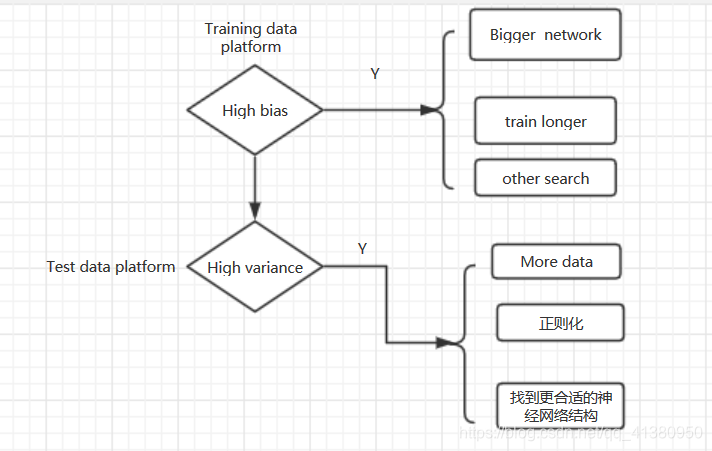
正则化改善高方差
理论基础
1、


2、

Dropout regularization(随即失活算法)
在神经网络的每一层,对于每一个神经节点都有50%的概率被删除,从而使神经网络的结构简单化。对于每一个训练样例都有不同的神经网络结构来进行训练。
- 反向随即失活 通过除以keep.prob来保证期望值不变
Data augmentation
为了降低成本,可以采用将图片翻转,随机剪裁,或者将清晰图片打马赛克等一系列玄学手段来增加数据量。
Early stopping
编程作业
目标:
1、初始化参数:
1.1:使用
来初始化参数
1.2:使用随机数来初始化参数
1.3:使用抑梯度异常初始化参数
2、正则化模型:
2.1:使用二范数对二分类模型正则化,尝试避免过拟合
2.2:使用随机删除节点的方法精简模型,避免过拟合
3、梯度校验:
对模型使用梯度校验,检测它是否在梯度下降的过程中出现误差过大的情况。
初始化参数核心代码:
1、parameters["W" + str(l)] = np.zeros((layers_dims[l],layers_dims[l-1]))
parameters["b" + str(l)] = np.zeros((layers_dims[l],1))
2、parameters['W' + str(l)] = np.random.randn(layers_dims[l], layers_dims[l - 1]) * 10 #使用10倍缩放
parameters['b' + str(l)] = np.zeros((layers_dims[l], 1))
3、parameters['W' + str(l)] = np.random.randn(layers_dims[l], layers_dims[l - 1]) * np.sqrt(2 / layers_dims[l - 1])
parameters['b' + str(l)] = np.zeros((layers_dims[l], 1))
梯度校验:
