第一部分:视频学习总结
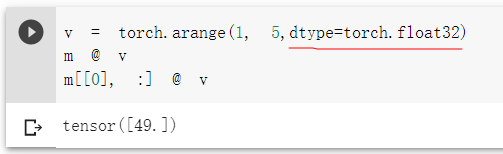
人工智能
人工智能:使机器像人一样进行感知、认知、决策和执行的人工程序或系统。
人工智能在多个领域应用,AI+应用广泛,例如AI+金融:芝麻信用;AI+创作:双11个性化海报等。
人工智能与机器学习与深度学习的关系
人工智能(目标)>机器学习(一类方法)>深度学习(一个方法)
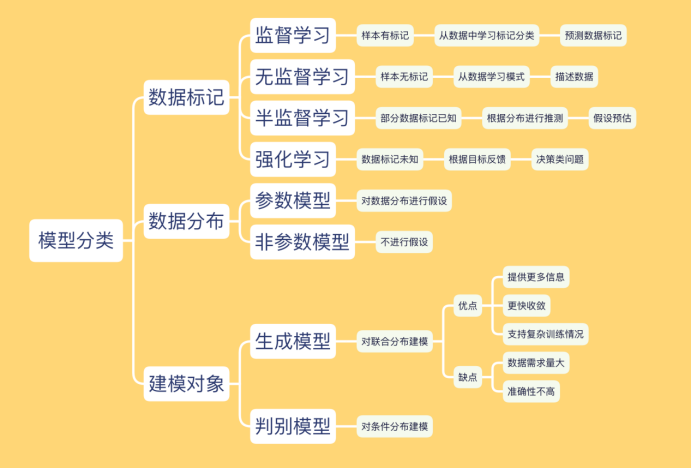
专家系统与机器学习
专家系统主要由专家制定规则,应用于规则简单但是规模较大的问题;机器学习是通过训练模型(决策树),应用于有意义的模式(无意义模式:孩子什么时候哭)和无解析解的问题。
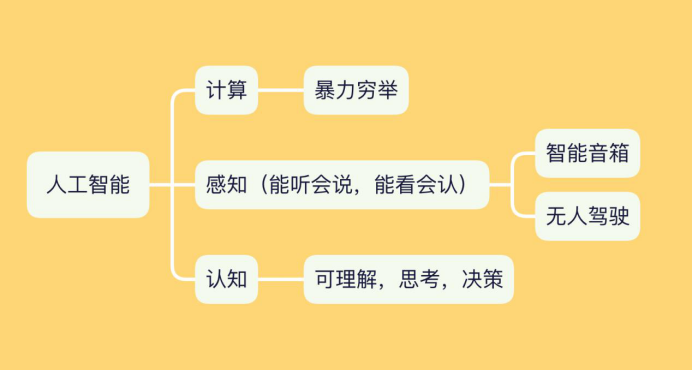
模型分类
强化学习理解:一个人找东西,每走一步都会有提示,离目标越近还是越远,智能体(找东西的人),环境(反馈),基于反馈,建立一个决策的函数,最后逼近目标。
传统机器学习与深度学习的对比
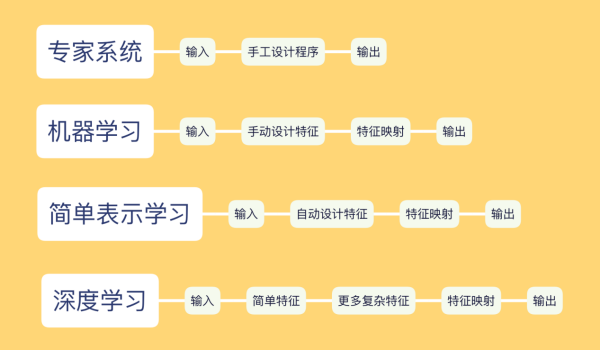
深度学习的不能
- 算法输出不稳定,容易被“攻击”
- 模型复杂度高,难以纠错和调试
- 模型层级复合程度高,参数不透明
- 样本数据量小的时候,无法体现强大拟合能力(推测迁移)
- 对开放性推理问题无能为力,专注直观感知类问题(鹦鹉与乌鸦)
- 无法引入有效监督,机器偏见
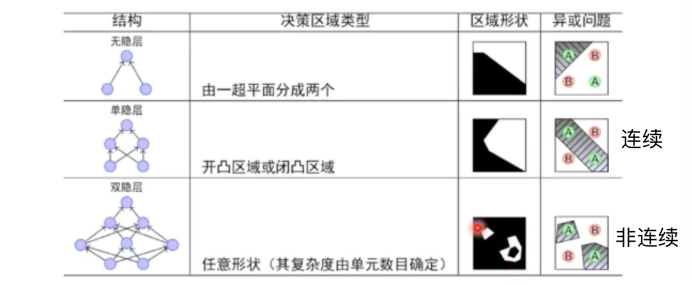
感知器
学习感知器,单层(与非或)->多层(异或门,同或门),线性分类任务组合之后可以解决非线性分类任务
万有逼近定理如果一个隐层包含足够多的神经元,三层前馈神经网络(输入-隐层-输出)能以任意精度逼近任意预定的连续函数。
当隐层足够宽时,双隐层感知器(输入-隐层1-隐层2-输出)可以逼近任意非连续函数:可以解决任何复杂的分类问题。
神经网络学习如何利用矩阵的线性变换加激活函数的非线性变换,将原始输入空间投影到线性可分的空间去分类/回归。

宽OR 深:神经元总数相当的话,高瘦比胖矮好一点,有更强的网络表示能力:产生更多的线性区域。
多层神经网络问题:梯度消失问题
1.增加深度会造成梯度消失,误差无法传播
2.多层网络容易陷入局部极值,难以训练
—>结论:三层神经网络是主流。
梯度是相对于多元函数来说的,在一个点有很多的方向,每个方向都可以计算导数,称为方向导数。
梯度为一个向量,方向是最大方向导数的方向,模为方向导数的最大值。
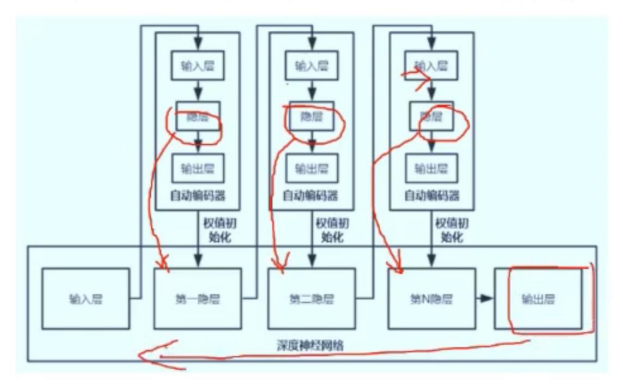
逐层预训练(layer-wise pre-training)
解决较差局部最小值和梯度消失问题:寻找不错的初始值。
难点:前面的隐层只有输入没有监督信息
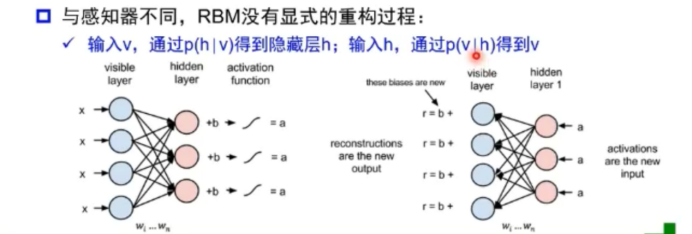
解决:受限玻尔兹曼机RBM:只有两层(可见层和隐藏层),不同层之间全连接,同层无连接,不区分前向和反向。
目的是使隐藏层得到的可见层v’与原来的可见层v分布一致。
自编码器Autoencoder:假设输出与输入相同,没有额外的监督信息,可以有多层
DNN
前馈神经网络,训练方法为BP
隐层激活函数为ReLU(改善梯度消失)
输出层激活函数为softmax,目标函数是交叉熵 +大量标注数据(避免差的局部极小值。
正则化+dropout(改善过拟合)
没有使用逐层预训练
PyTorch基础
PyTorch是一个Python库,主要提供以下两个功能
l GPU加速的张量计算功能
l 构建在反向自动求导系统上的深度神经网络功能
两个核心问题
l 怎么定义数据 —> torch.Tensor张量,存储数据,是各个类型数据的封装
l 怎么定义数据操作 —> torch.autograd.Function函数类,定义在Tensor类上的操作

怎么定义数据操作?Torch.autograd.Function
凡是用Tensor进行各种计算的,都是用Function
l 基本计算,加减乘除,求幂求余
l 布尔运算,大于小于,最大最小
l 线性运算,矩阵乘法,求模,求行列式
基本运算
| 函数 |
功能 |
| abs/sqrt/div/exp/fmod/log/pow... |
绝对值/平方根/除法/指数/求余/求幂... |
| cos/sin/asin/atan2/cosh... |
相关三角函数 |
| ceil/round/floor/trunch |
上取整/四舍五入/下取整/只保留整数部分 |
| clamp(input,min,max) |
超过min和max部分截断 |
| sigmod/tanh... |
激活函数 |
| mean/sum/median/mode |
均值/和/中位数/众数 |
| norm/dist |
范数/距离 |
| std/var |
标准差/方差 |
| cumsum/cumprod |
累加/累乘 |
布尔运算
| 函数 |
功能 |
| gt/lt/ge/le/eq/ne |
大于/小于/大于等于/小于等于/等于/不等于 |
| topk |
最大的k个数 |
| sort |
排序 |
| max/min |
比较两个tensor最大最小值 |
线性计算
| 函数 |
功能 |
| trace |
对角线元素之和(矩阵的迹) |
| diag |
对角线元素 |
| triu/tril |
矩阵的上三角/下三角,可指定偏移量 |
| mm/bmm |
矩阵乘法,batch的矩阵乘法 |
| addmm/addbmm/addmv/addr/badbmm |
矩阵运算 |
| t |
转置 |
| dot/cross |
内积/外积 |
| inverse |
求逆矩阵 |
| svd |
奇异值分解 |
Tensor组成
l Data属性,用来存数据
l Grad属性,用来存梯度
l Grad_fn属性,指向创造自己的Function
例如:y=x+2 y.grad_fn就是+
代码实现流程
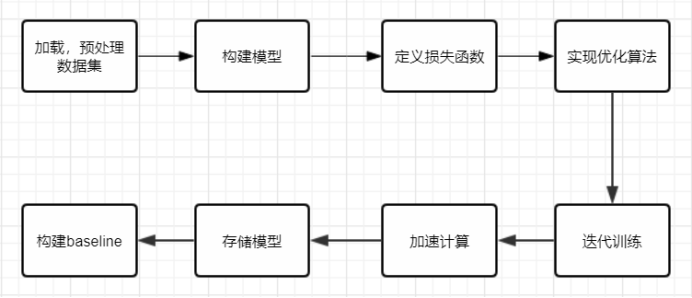
第二部分:代码练习
2.1图像处理基本练习
1.下载并显示图像
!wget https://raw.githubusercontent.com/summitgao/ImageGallery/master/yeast_colony_array.jpg
import matplotlib import numpy as np import matplotlib.pyplot as plt import skimage from skimage import data from skimage import io colony = io.imread('yeast_colony_array.jpg') print(type(colony)) print(colony.shape)
# Plot all channels of a real image plt.subplot(121) plt.imshow(colony[:,:,:]) plt.title('3-channel image') plt.axis('off') # Plot one channel only plt.subplot(122) plt.imshow(colony[:,:,0]) plt.title('1-channel image') plt.axis('off');
2.读取并改变图像像素值
# Get the pixel value at row 10, column 10 on the 10th row and 20th column camera = data.camera() print(camera[10, 20]) # Set a region to black camera[30:100, 10:100] = 0 plt.imshow(camera, 'gray')

# Set the first ten lines to black camera = data.camera() camera[:10] = 0 plt.imshow(camera, 'gray')

# Set to "white" (255) pixels where mask is True camera = data.camera() mask = camera < 80 camera[mask] = 255 plt.imshow(camera, 'gray')

# Change the color for real images cat = data.chelsea() plt.imshow(cat)

# Set brighter pixels to red red_cat = cat.copy() reddish = cat[:, :, 0] > 160 red_cat[reddish] = [255, 0, 0] plt.imshow(red_cat)

# Change RGB color to BGR for openCV BGR_cat = cat[:, :, ::-1] plt.imshow(BGR_cat)

3.转换图像数据类型
- img_as_float Convert to 64-bit floating point.
- img_as_ubyte Convert to 8-bit uint.
- img_as_uint Convert to 16-bit uint.
- img_as_int Convert to 16-bit int.
from skimage import img_as_float, img_as_ubyte float_cat = img_as_float(cat) uint_cat = img_as_ubyte(float_cat)
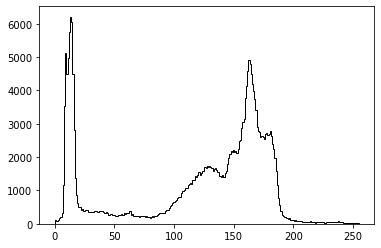
4. 显示图像直方图
img = data.camera() plt.hist(img.ravel(), bins=256, histtype='step', color='black');
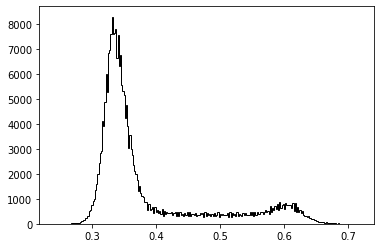
5. 图像分割
# Use colony image for segmentation colony = io.imread('yeast_colony_array.jpg') # Plot histogram img = skimage.color.rgb2gray(colony) plt.hist(img.ravel(), bins=256, histtype='step', color='black');
# Use thresholding plt.imshow(img>0.5)

6. Canny 算子用于边缘检测
from skimage.feature import canny from scipy import ndimage as ndi img_edges = canny(img) img_filled = ndi.binary_fill_holes(img_edges) # Plot plt.figure(figsize=(18, 12)) plt.subplot(121) plt.imshow(img_edges, 'gray') plt.subplot(122) plt.imshow(img_filled, 'gray')

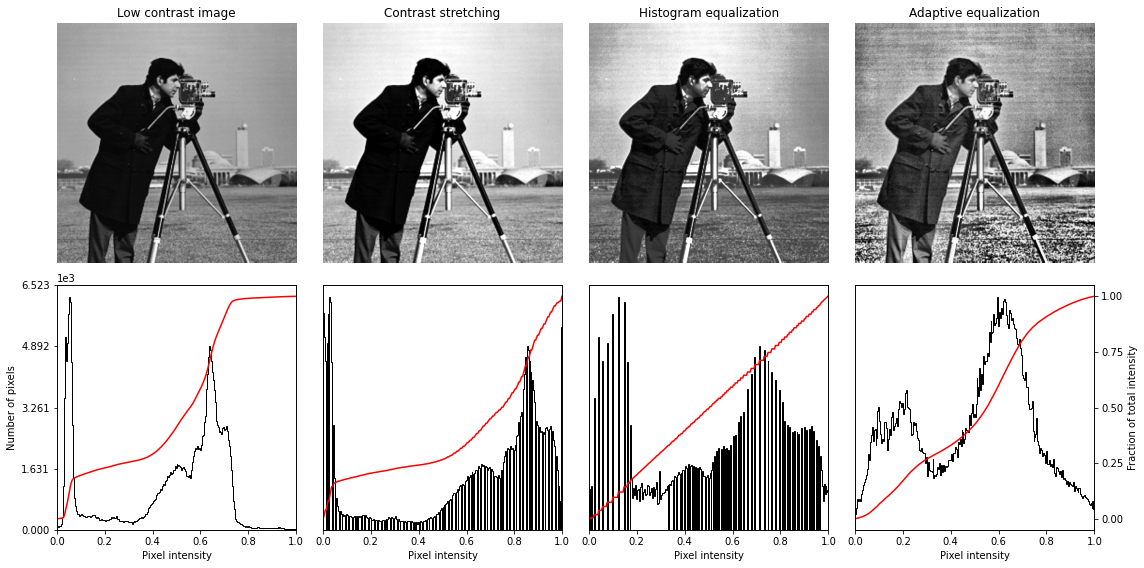
7. 改变图像的对比度
# Load an example image img = data.camera() plt.imshow(img, 'gray')

# Contrast stretching p2, p98 = np.percentile(img, (2, 98)) img_rescale = exposure.rescale_intensity(img, in_range=(p2, p98)) plt.imshow(img_rescale, 'gray')

# Equalization img_eq = exposure.equalize_hist(img) plt.imshow(img_eq, 'gray')

# Adaptive Equalization img_adapteq = exposure.equalize_adapthist(img, clip_limit=0.03) plt.imshow(img_adapteq, 'gray')

# Display results def plot_img_and_hist(img, axes, bins=256): """Plot an image along with its histogram and cumulative histogram. """ img = img_as_float(img) ax_img, ax_hist = axes ax_cdf = ax_hist.twinx() # Display image ax_img.imshow(img, cmap=plt.cm.gray) ax_img.set_axis_off() ax_img.set_adjustable('box') # Display histogram ax_hist.hist(img.ravel(), bins=bins, histtype='step', color='black') ax_hist.ticklabel_format(axis='y', style='scientific', scilimits=(0, 0)) ax_hist.set_xlabel('Pixel intensity') ax_hist.set_xlim(0, 1) ax_hist.set_yticks([]) # Display cumulative distribution img_cdf, bins = exposure.cumulative_distribution(img, bins) ax_cdf.plot(bins, img_cdf, 'r') ax_cdf.set_yticks([]) return ax_img, ax_hist, ax_cdf
fig = plt.figure(figsize=(16, 8)) axes = np.zeros((2, 4), dtype=np.object) axes[0, 0] = fig.add_subplot(2, 4, 1) for i in range(1, 4): axes[0, i] = fig.add_subplot(2, 4, 1+i, sharex=axes[0,0], sharey=axes[0,0]) for i in range(0, 4): axes[1, i] = fig.add_subplot(2, 4, 5+i) ax_img, ax_hist, ax_cdf = plot_img_and_hist(img, axes[:, 0]) ax_img.set_title('Low contrast image') y_min, y_max = ax_hist.get_ylim() ax_hist.set_ylabel('Number of pixels') ax_hist.set_yticks(np.linspace(0, y_max, 5)) ax_img, ax_hist, ax_cdf = plot_img_and_hist(img_rescale, axes[:, 1]) ax_img.set_title('Contrast stretching') ax_img, ax_hist, ax_cdf = plot_img_and_hist(img_eq, axes[:, 2]) ax_img.set_title('Histogram equalization') ax_img, ax_hist, ax_cdf = plot_img_and_hist(img_adapteq, axes[:, 3]) ax_img.set_title('Adaptive equalization') ax_cdf.set_ylabel('Fraction of total intensity') ax_cdf.set_yticks(np.linspace(0, 1, 5)) fig.tight_layout() plt.show()
2.2pytorch基础练习
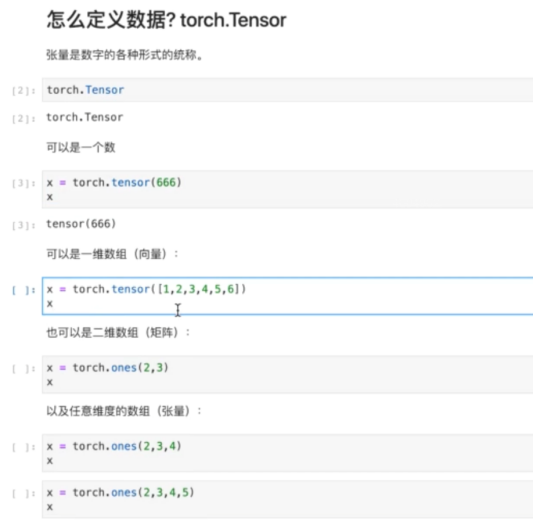
import torch # 可以是一个数 x = torch.tensor(666) print(x)
# 可以是一维数组(向量) x = torch.tensor([1,2,3,4,5,6]) print(x)
# 可以是二维数组(矩阵) x = torch.ones(2,3) print(x)
# 可以是任意维度的数组(张量) x = torch.ones(2,3,4) print(x)
# 创建一个空张量 x = torch.empty(5,3) print(x)
# 创建一个随机初始化的张量 x = torch.rand(5,3) print(x)
# 创建一个全0的张量,里面的数据类型为 long x = torch.zeros(5,3,dtype=torch.long) print(x)
# 基于现有的tensor,创建一个新tensor, # 从而可以利用原有的tensor的dtype,device,size之类的属性信息 y = x.new_ones(5,3) #tensor new_* 方法,利用原来tensor的dtype,device print(y)
z = torch.randn_like(x, dtype=torch.float) # 利用原来的tensor的大小,但是重新定义了dtype print(z)
# 创建一个 2x4 的tensor m = torch.Tensor([[2, 5, 3, 7], [4, 2, 1, 9]]) print(m.size(0), m.size(1), m.size(), sep=' -- ')
# 返回 m 中元素的数量 print(m.numel())
# 返回 第0行,第2列的数 print(m[0][2])
# 返回 第1列的全部元素 print(m[:, 1])
# 返回 第0行的全部元素 print(m[0, :])
v = torch.arange(1, 5,dtype=torch.float32)
m @ v
m[[0], :] @ v
# Add a random tensor of size 2x4 to m m + torch.rand(2, 4)
# 转置,由 2x4 变为 4x2 print(m.t())
# 使用 transpose 也可以达到相同的效果,具体使用方法可以百度 print(m.transpose(0, 1))
# returns a 1D tensor of steps equally spaced points between start=3, end=8 and steps=20 torch.linspace(3, 8, 20)
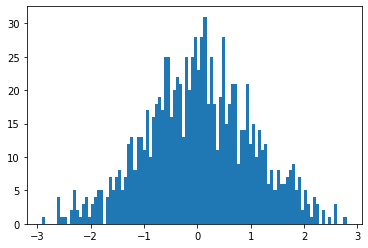
from matplotlib import pyplot as plt # matlabplotlib 只能显示numpy类型的数据,下面展示了转换数据类型,然后显示 # 注意 randn 是生成均值为 0, 方差为 1 的随机数 # 下面是生成 1000 个随机数,并按照 100 个 bin 统计直方图 plt.hist(torch.randn(1000).numpy(), 100);
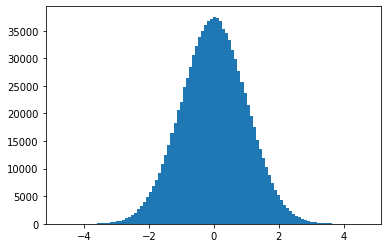
# 当数据非常非常多的时候,正态分布会体现的非常明显 plt.hist(torch.randn(10**6).numpy(), 100);
# 当数据非常非常多的时候,正态分布会体现的非常明显 plt.hist(torch.randn(10**6).numpy(), 100); # 创建两个 1x4 的tensor a = torch.Tensor([[1, 2, 3, 4]]) b = torch.Tensor([[5, 6, 7, 8]]) # 在 0 方向拼接 (即在 Y 方各上拼接), 会得到 2x4 的矩阵 print( torch.cat((a,b), 0)) # 在 1 方向拼接 (即在 X 方各上拼接), 会得到 1x8 的矩阵 print( torch.cat((a,b), 1))
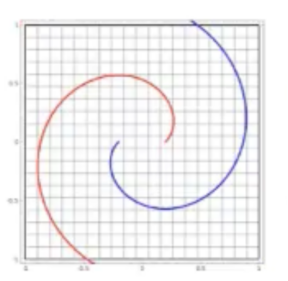
2.3螺旋数据分类
!wget https://raw.githubusercontent.com/Atcold/pytorch-Deep-Learning/master/res/plot_lib.py
import random import torch from torch import nn, optim import math from IPython import display from plot_lib import plot_data, plot_model, set_default # 因为colab是支持GPU的,torch 将在 GPU 上运行 device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") print('device: ', device) # 初始化随机数种子。神经网络的参数都是随机初始化的, # 不同的初始化参数往往会导致不同的结果,当得到比较好的结果时我们通常希望这个结果是可以复现的, # 因此,在pytorch中,通过设置随机数种子也可以达到这个目的 seed = 12345 random.seed(seed) torch.manual_seed(seed) N = 1000 # 每类样本的数量 D = 2 # 每个样本的特征维度 C = 3 # 样本的类别 H = 100 # 神经网络里隐层单元的数量
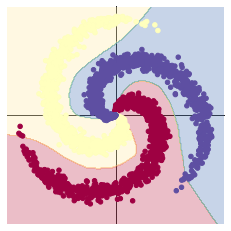
X = torch.zeros(N * C, D).to(device) Y = torch.zeros(N * C, dtype=torch.long).to(device) for c in range(C): index = 0 t = torch.linspace(0, 1, N) # 在[0,1]间均匀的取10000个数,赋给t # 下面的代码不用理解太多,总之是根据公式计算出三类样本(可以构成螺旋形) # torch.randn(N) 是得到 N 个均值为0,方差为 1 的一组随机数,注意要和 rand 区分开 inner_var = torch.linspace( (2*math.pi/C)*c, (2*math.pi/C)*(2+c), N) + torch.randn(N) * 0.2 # 每个样本的(x,y)坐标都保存在 X 里 # Y 里存储的是样本的类别,分别为 [0, 1, 2] for ix in range(N * c, N * (c + 1)): X[ix] = t[index] * torch.FloatTensor((math.sin(inner_var[index]), math.cos(inner_var[index]))) Y[ix] = c index += 1 print("Shapes:") print("X:", X.size()) print("Y:", Y.size()) # visualise the data plot_data(X, Y)

learning_rate = 1e-3 lambda_l2 = 1e-5 # nn 包用来创建线性模型 # 每一个线性模型都包含 weight 和 bias model = nn.Sequential( nn.Linear(D, H), nn.Linear(H, C) ) model.to(device) # 把模型放到GPU上 # nn 包含多种不同的损失函数,这里使用的是交叉熵(cross entropy loss)损失函数 criterion = torch.nn.CrossEntropyLoss() # 这里使用 optim 包进行随机梯度下降(stochastic gradient descent)优化 optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, weight_decay=lambda_l2) # 开始训练 for t in range(1000): # 把数据输入模型,得到预测结果 y_pred = model(X) # 计算损失和准确率 loss = criterion(y_pred, Y) score, predicted = torch.max(y_pred, 1) acc = (Y == predicted).sum().float() / len(Y) print('[EPOCH]: %i, [LOSS]: %.6f, [ACCURACY]: %.3f' % (t, loss.item(), acc)) display.clear_output(wait=True) # 反向传播前把梯度置 0 optimizer.zero_grad() # 反向传播优化 loss.backward() # 更新全部参数 optimizer.step()
print(y_pred.shape) print(y_pred[10, :]) print(score[10]) print(predicted[10])
# Plot trained model print(model) plot_model(X, Y, model)

learning_rate = 1e-3 lambda_l2 = 1e-5 # 这里可以看到,和上面模型不同的是,在两层之间加入了一个 ReLU 激活函数 model = nn.Sequential( nn.Linear(D, H), nn.ReLU(), nn.Linear(H, C) ) model.to(device) # 下面的代码和之前是完全一样的,这里不过多叙述 criterion = torch.nn.CrossEntropyLoss() optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate, weight_decay=lambda_l2) # built-in L2 # 训练模型,和之前的代码是完全一样的 for t in range(1000): y_pred = model(X) loss = criterion(y_pred, Y) score, predicted = torch.max(y_pred, 1) acc = ((Y == predicted).sum().float() / len(Y)) print("[EPOCH]: %i, [LOSS]: %.6f, [ACCURACY]: %.3f" % (t, loss.item(), acc)) display.clear_output(wait=True) # zero the gradients before running the backward pass. optimizer.zero_grad() # Backward pass to compute the gradient loss.backward() # Update params optimizer.step()
# Plot trained model print(model) plot_model(X, Y, model)
2.4回归分析
!wget https://raw.githubusercontent.com/Atcold/pytorch-Deep-Learning/master/res/plot_lib.py
import random import torch from torch import nn, optim import math from IPython import display from plot_lib import plot_data, plot_model, set_default from matplotlib import pyplot as plt set_default() device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") seed = 1 random.seed(seed) torch.manual_seed(seed) N = 1000 # 每类样本的数量 D = 1 # 每个样本的特征维度 C = 1 # 类别数 H = 100 # 隐层的神经元数量 X = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1).to(device) y = X.pow(3) + 0.3 * torch.rand(X.size()).to(device) print("Shapes:") print("X:", tuple(X.size())) print("y:", tuple(y.size()))
# 在坐标系上显示数据 plt.figure(figsize=(6, 6)) plt.scatter(X.cpu().numpy(), y.cpu().numpy()) plt.axis('equal');
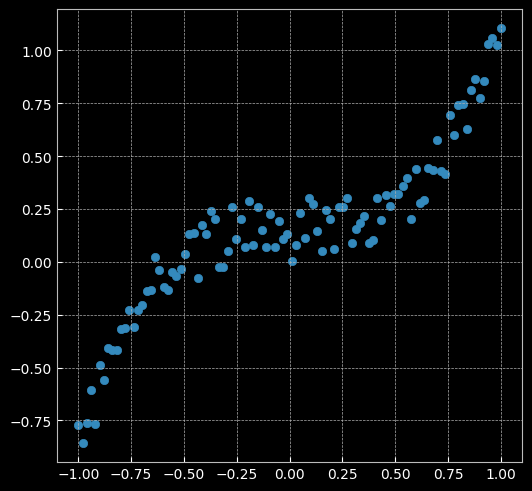
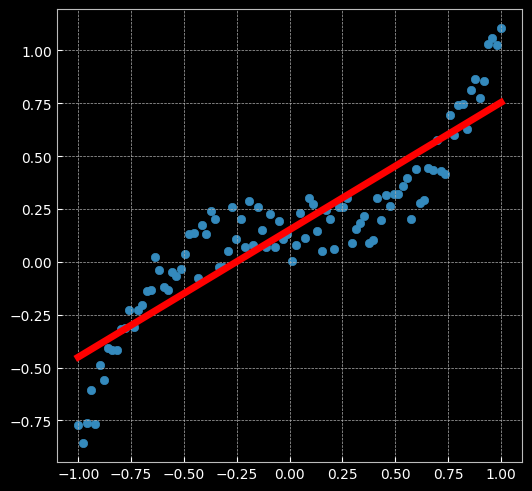
learning_rate = 1e-3 lambda_l2 = 1e-5 # 建立神经网络模型 model = nn.Sequential( nn.Linear(D, H), nn.Linear(H, C) ) model.to(device) # 模型转到 GPU # 对于回归问题,使用MSE损失函数 criterion = torch.nn.MSELoss() # 定义优化器,使用SGD optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, weight_decay=lambda_l2) # built-in L2 # 开始训练 for t in range(1000): # 数据输入模型得到预测结果 y_pred = model(X) # 计算 MSE 损失 loss = criterion(y_pred, y) print("[EPOCH]: %i, [LOSS or MSE]: %.6f" % (t, loss.item())) display.clear_output(wait=True) # 反向传播前,梯度清零 optimizer.zero_grad() # 反向传播 loss.backward() # 更新参数 optimizer.step()
# 展示模型与结果 print(model) plt.figure(figsize=(6,6)) plt.scatter(X.data.cpu().numpy(), y.data.cpu().numpy()) plt.plot(X.data.cpu().numpy(), y_pred.data.cpu().numpy(), 'r-', lw=5) plt.axis('equal');
# 这里定义了2个网络,一个 relu_model,一个 tanh_model, # 使用了不同的激活函数 relu_model = nn.Sequential( nn.Linear(D, H), nn.ReLU(), nn.Linear(H, C) ) relu_model.to(device) tanh_model = nn.Sequential( nn.Linear(D, H), nn.Tanh(), nn.Linear(H, C) ) tanh_model.to(device) # MSE损失函数 criterion = torch.nn.MSELoss() # 定义优化器,使用 Adam,这里仍使用 SGD 优化器的化效果会比较差,具体原因请自行百度 optimizer_relumodel = torch.optim.Adam(relu_model.parameters(), lr=learning_rate, weight_decay=lambda_l2) optimizer_tanhmodel = torch.optim.Adam(tanh_model.parameters(), lr=learning_rate, weight_decay=lambda_l2) # 开始训练 for t in range(1000): y_pred_relumodel = relu_model(X) y_pred_tanhmodel = tanh_model(X) # 计算损失与准确率 loss_relumodel = criterion(y_pred_relumodel, y) loss_tanhmodel = criterion(y_pred_tanhmodel, y) print(f"[MODEL]: relu_model, [EPOCH]: {t}, [LOSS]: {loss_relumodel.item():.6f}") print(f"[MODEL]: tanh_model, [EPOCH]: {t}, [LOSS]: {loss_tanhmodel.item():.6f}") display.clear_output(wait=True) optimizer_relumodel.zero_grad() optimizer_tanhmodel.zero_grad() loss_relumodel.backward() loss_tanhmodel.backward() optimizer_relumodel.step() optimizer_tanhmodel.step()
plt.figure(figsize=(12, 6)) def dense_prediction(model, non_linearity): plt.subplot(1, 2, 1 if non_linearity == 'ReLU' else 2) X_new = torch.unsqueeze(torch.linspace(-1, 1, 1001), dim=1).to(device) with torch.no_grad(): y_pred = model(X_new) plt.plot(X_new.cpu().numpy(), y_pred.cpu().numpy(), 'r-', lw=1) plt.scatter(X.cpu().numpy(), y.cpu().numpy(), label='data') plt.axis('square') plt.title(non_linearity + ' models') dense_prediction(relu_model, 'ReLU') dense_prediction(tanh_model, 'Tanh')
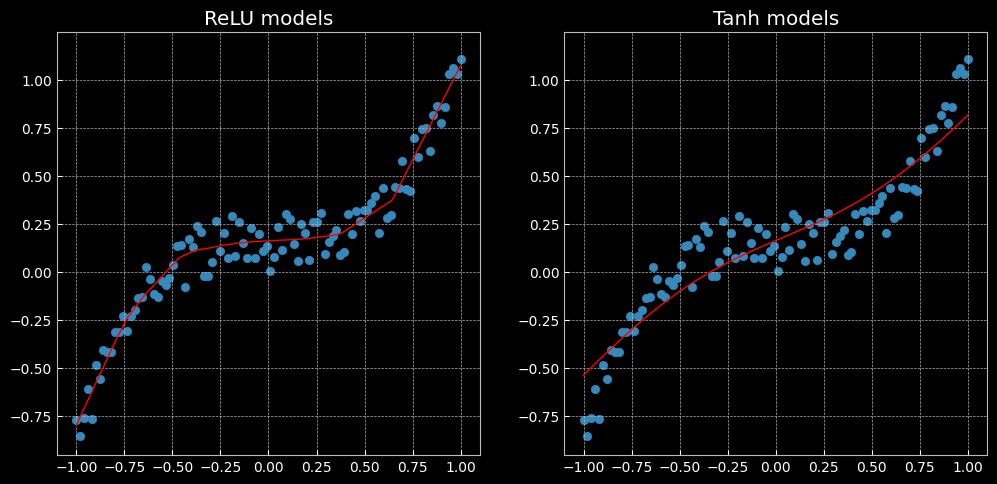
出现问题

解决